



Please note that this talk covers the previous version of neosemantics, the current version has a lot of new features and capabilities, please check out the documentation and videos on the neosemantics Neo4j Labs page.
Presentation Summary
Jesús Barrasa, Neo4j Sales Engineering Director, presents Neosemantics, NSMNTX. NSMNTX is an extension plugin for Neo4j built to help users work with RDF and linked data.
Starting off, Barrasa discusses different types of data. RDF is a standard defined by W3C and is a standard model for data exchange on the web. As such, RDF offers a number of serialization formats.
Even though RDF is a different model it still has the same underlying abstraction of the world, and sees the world as a graph. With NSMNTX, users will be able to import RDF data into Neo4j. Because they are both graphs the transition is straightforward.
The import and export process for RDF data into and out of Neo4j is exactly the same. We run a series of commands, produce a serialization and export the graph as RDF. These are nonstop procedures. Additionally, users can also run Cypher on the database.
NSMNTX is not just about importing and exporting data. Other features include ontology management and publishing ontologies within your graph. There is .importOntology which will take the ontology from wherever it lives and it will import it. It also includes inferencing which is being able to define as data explicit descriptions or explicit behaviors that you want a general purpose engine to run. Finally, users can clone subgraphs from one Neo4j instance to another.
Full Presentation
Hi, everyone. My name is Jesús Barrasa. I’m going to be presenting Neosemantics, NSMNTX.
I’ll be talking about this extension plugin for Neo4j that will help you work with RDF data, linked data and do some quite interesting things.
I will start with a proper introduction.

I’m Jesús Barrasa. I’m based in London. I’m part of the field team with Neo4j and have been for the last four years. I’ve spent quite some time working with graphs and property graphs with Neo4j.
I also have a background in RDF. I did my PhD in Semantic Technologies. I spent years working on a lot of RDF, ontologies and linked data for some interesting projects. In particular, I focused on mapping relational schemas to ontologies. That was a long time ago.
The reason why I’m talking about NSMNTX , RDF, linked data and Neo4j today is because of my background. Additionally, I’ve been working for the last few years on this extension that I’m going to present.
I’m super happy to announce that the project Neosemantix joins the Neo4j Labs incubator.

This is great news!
Here is the URL with all of the information. I hope that we’ll get a lot more exposure and users. There’s already an involved community around it, but I’d love to amplify the use and get more contributions.
When you go to that URL, what you will get is the page of the project. Here’s what it looks like:

You’ll have a summary of what I’m going to be talking about today. The summary will include what Neoemantics is, what you are able to do with it and share some interesting links.
There is a button at the bottom of the page. You will see some documents and blog posts about the use of Neosemantix and Neo4j. There are also some video presentations and webinars that are useful when getting started.
More importantly, you have a link to the source code, as all the projects in the Neo4j Labs are open source. You are able to have a look at it and contribute. You also have a link to a fantastic documentation that Mark Needham has helped me prepare for you.
Let’s get started.
What is NSMNTX?

Most of you know Neo4j and RDF.
RDF is a standard defined by W3C. RDF is a standard model for data exchange on the web. RDF offers a number of serialization formats that we’ll be looking at.
What’s interesting is that RDF represents models of the world in terms of connected entities. RDF uses the notion of triples and that’s how it represents the world.
A triple is a subject connected to an object through a predicate. In Neo4j, that’s an edge in a graph. Effectively, when you combine triples, you’re forming a graph.
What’s interesting is that RDF, being a different model, has the same underlying abstraction of the world. It sees the world as a graph. One of the things that we’ll be able to do with RDF through NSMNTX is be able to import RDF data into Neo4j. They’re graphs, so they should be straightforward.
You are able to import RDF data, this RDF data could come from services that expose the results as RDF, it could be datasets that exist that are published as RDF or it could be your own files. Any kind of RDF data is able to be imported with NSMNTX into Neo4j. It’s important that we do so in a lossless manner. By doing that, we store the RDF data.
We store the RDF data as a property graph. In a little bit, we will see how that happens because that’s what Neo4j is. It’s a property graph. We store that graph in a way that it is able to be regenerated back again as RDF without loss of any single triple. That’s what I mean by a lossless import/export of data.
These are the two main capabilities of the NSMNTX extension and it’s where it all started.
I’d like to emphasize the idea that we see Neo4j as the mechanism to publish and import data, as defined by the W3C. It’s a model for data exchange and that’s how we use it. Essentially, Neo4j says that you’re free to use the storage that you like and RDF is this layer on top that simplifies and enables interoperability between applications through the standard format. These are the two main points – import and export.
There’s model mapping capabilities, essentially it allows you to map your Neo4j graph to an existing public vocabulary and expose your data according to that vocabulary. Additionally, there’s some basic inferencing capabilities. This is just the beginning of it.
Inferencing is not built into Neo4j, but NSMNTX brings a little bit of these. This is another powerful feature, some of the languages built on top of RDF are OWL or RDFS.
Importing data
Let’s have a look at importing data into Neo4j.
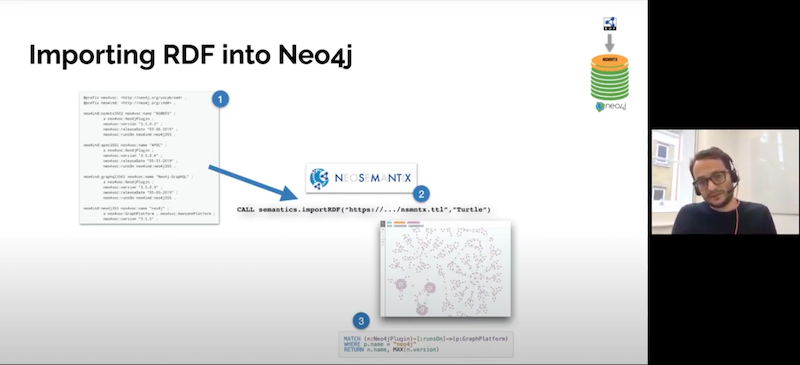
This scheme is a diagram represented in the three basic steps. There is some RDF data that comes from a previous RD, like a SPARQL endpoint producing RDF. Or it could be a static dump of RDF that you got.
You have that source of RDF, and through NSMNTX and by using the import RDF procedure, you are able to import all these triples into Neo4j and have a nice graph, one that you’re familiar with and that you love. Then, you’ll be able to query your data using Cypher. Plus, there are all the extra benefits that you get from having your data in Neo4j. For example, having access to the fantastic library of algorithms and getting all the fast traversals.
How does that happen, effectively?

There’s one main procedure. Because these extensions are mostly implemented as procedures.
The procedure for import is .importRDF and we’re going to see in a minute the parameters that it takes. However, there are two additional ones, which are called .streamRDF and .previewRDF which are utility procedures to analyze the RDF data before you actually persist it in the graph. The import does save the RDF in your Neo4j graph in a persisted way. Whereas the other two just parse the RDF and produce serialization for visualization purposes but do not persist it.
As I was saying, the procedure takes two main parameters. There’s two that have to be always there. One is the URL which is the point to where the data lives and that could be an HTTP endpoint.

It could be wherever the RDF lives and then the format. There are a number of serialization formats, standard by the W3C and you have some of them there. You have to specify which one your source data uses so that the parser treats it accordingly. There are common ones like Turtle, which is pretty compact. JSON-LD is pretty popular. There are also traditional ones, RDF/XML serializes XML, or N-Triples which is essentially a list of statements in plain text.
The URL, the location of your RDF source and the format are required, and then there’s a number of parameters that are optional. First example, I’ll run without parameters and we’ll see what happens.
Let’s try it!

Let’s have a look at this import capability in the first place. I’m going to bring up the Neo4j browser.
I have an empty database here. There’s no elements here and I’ve created a few queries that I’m going to use for this demonstration.
The first import statement looks something like this.
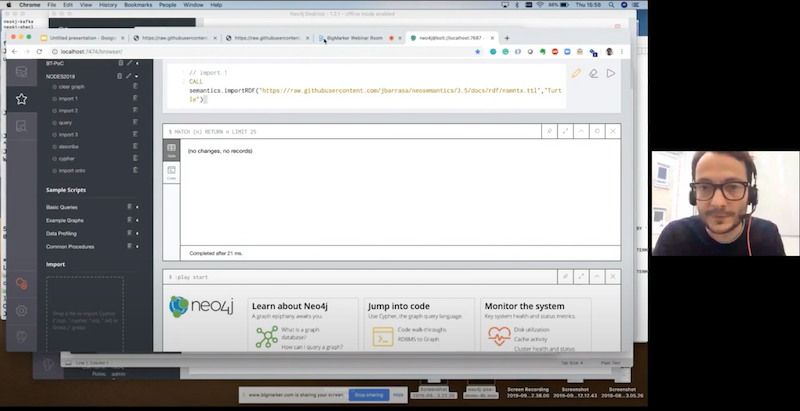
As you see it’s just a simple
CALL. The CALL is the keyword Cypher to invoke installed procedure. I was calling the .importRDF that I was mentioning before, and all I’m passing as a parameter is the location of these RDFs. This is the URL of an RDF fragment that I’m going to show, and I’m specifying that it’s serialized as Turtle.It would be a good idea for me to actually show that RDF. Here’s this fragment of Cypher.

For those who are familiar with Turtle, you see that we’re using serialization here. Also, there’s four descriptions and resources being described.
The first one is NSMNTX. The second one is APOC, which is the library of procedures and the third one is Neo4j-GraphQL. Finally, the fourth one is Neo4j.
I’m describing three plugins and I say in my triples that all three of them are Neo4j plugins. I have Neo4j at the bottom and it’s described as a graph platform. It’s an awesome platform. They all have a property that describes the version. You see that every resource has a version and some of them, in the case of plugins, have the release date and the version of Neo4j it runs on. This effectively implements the links in this RDF graph.
What I’m going to do is take this URL, publish in GitHub, and use it in my invocation of semantics import, and that’s all I have to do in Turtle.
I get a summary of the execution and what has happened there. Of course, this is a small set of triples – there’s just 19 triples there.
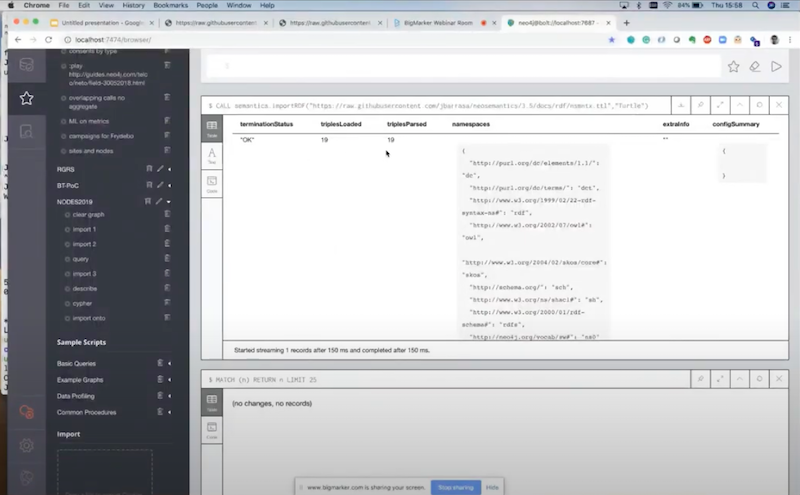
Now the triples have been imported, some namespaces have been created, and I’m going to show you what that looks like.
I’m going to click here to get all the elements, we have the three plugins.

There’s GraphQL, there’s Neo4j, there’s APOC and NSMNTX. All these statements and triples are not lost. You see that they have been represented. If I select one of them, as properties of the nodes, that’s the transformation that takes place when you input RDF into Neo4j.
Essentially what’s called literal properties, attributes of the statements, of the triples or of the resources are transformed into properties. We have GraphQL with its name, release date, version and a unique identifier, which is the URI. We have the same for APOC and NSMNTX. They’re linked through the
runsOn relationship. You will notice that everything is prefixed and it’s not runsOn but ns0_runsOn. This is the way we encode namespaces.You realize in the RDF that I showed before everything represented was identified by URIs. That’s one of the building blocks of RDF. I want to be able to regenerate that, we don’t need that in Neo4j but if we want to regenerate that, I need to be able to do it. This
ns0 actually is the reference in this list of namespaces that have been created.We have our RDF data in Neo4j now. Now you are able to start querying it with Cypher and do all sorts of things.
Some people will say, “Hang on, I really don’t like having to work with these names because then that will affect my Cypher.” They think if they want to query a graph they’ll have to type
ns_0 every time. The RDF data that I’m importing is just a data source. I want that RDF data stored in a natural way in Neo4j. That’s not a problem, so that introduces this idea of the configuration parameters that you are able to add to the input process.Let’s go back to our import statement. What I’m going to do now is exactly the same as I did before. I’m going to add the handle vocabularies property. By doing that, I am able to tell where to keep the URIs, because I might want to reproduce them or the RDF afterwards. Or I want to keep them because I’m importing RDFs from different sources and I want to avoid clashes, so it’s important to me. The different options are important to different users. You could keep, you can shorten, or you can just ignore.
I choose to ignore this URI. I don’t care about the URIs, because all I want to do is import the data and make it look nice in Neo4j.
If I rerun this, I get exactly the same. However, this time I’m not generating namespace so I’m not needing them now. If I show the graph again, it’s exactly the same in terms of content.
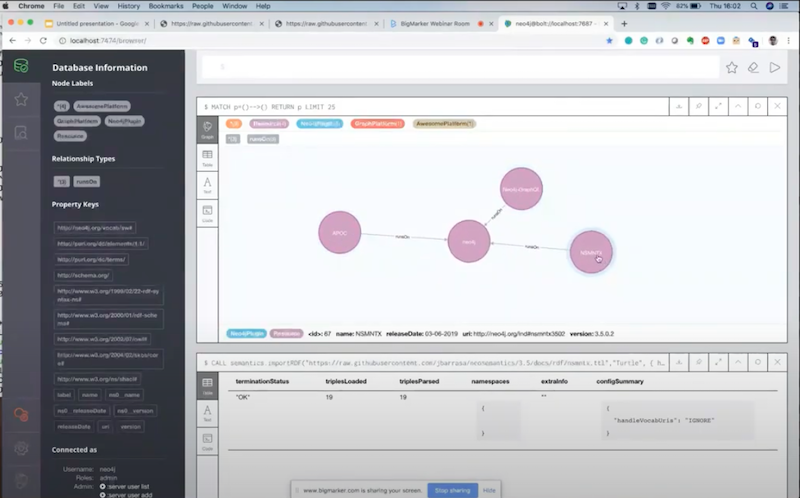
You see that APOC still has all the attributes, but it all looks the same the way we’re used to in Neo4j. We name things without having to use prefixes. That’s one of the features that you get, configuration parameters that you could add to the import process. We are able to add more.
I’m going to show the filtering of predicates.
Let’s say that I’m going back to my RDF that I want to import. If you think you’re loading a dataset with hundreds of millions of triples, you might want to say, “I don’t care about everything. I’m not interested in inversions and release dates. All I want is the plugins and the connections with the platforms they run on.”
You are able to specify and be granular to the statement and the predicate level. You are able to specify which predicates you want to exclude from the import.
I do it by adding another configuration parameter, which is
predicateExclusionList. I provide basically a list of the predicates that I want to exclude. In this case, I just ignore the version and release date.I’ll clear my graph to do the import one more time, this time I’m filtering the two predicates. You see that there’s 19 triples but only 12 have been loaded into. All have been parsed but only 12 have persisted in Neo4j. That’s precisely because of the filter we’ve just applied.
If I get the graph, you’ll see that it looks structurally still the same.
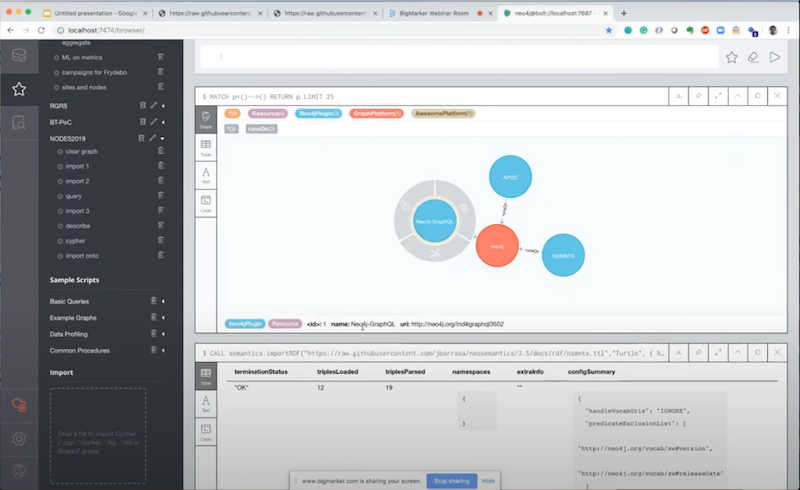
If you look at it now, we only have the name. We don’t have the version or the release date.
Export RDF data in Neo4j
Next, we look at how to export RDF data into Neo4j, the process is exactly the same.
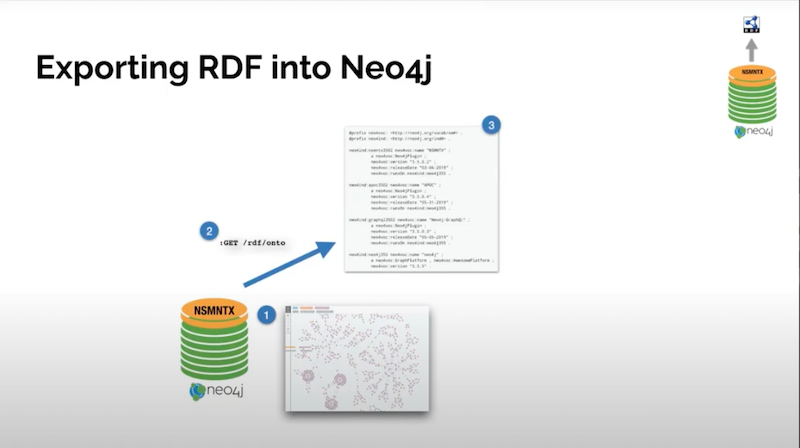
You have your graph database and Neo4j. You don’t need to use a graph database, you could use any database or graph that you have in Neo4j. We get your graph and we run a series of commands.
This is implemented as an extension and produces a serialization, an export of our graph as RDF. That serialization is exactly what this second part shows, and these are nonstop procedures.

I’m in the process of including all the stop procedures that do these, but at the moment it’s implemented as an HTTP endpoint. I thought it would be a useful way to simplify integration with an RDF consuming application.
You are able to do things like take an element in your graph by ID and serialize it. You take an element by property and value, which is probably the better way to do it. Or you run any random Cypher on your graph and serialize the results as RDF.
Let’s try it!
I’m going to use a movie database. You are able to access it directly from the initial guide.
I load my graph with actors, directors, etc and you see that we have persons, directing movies and all the people that act in movies.

Above is the database that you get with Neo4j. We have a simple property graph.
Now, I want to be able to export this graph, as is, through an HTTP endpoint as RDF. The easiest way to do it is to describe operation.
I’m using the browser to describe the operation but what’s happening here is the column GET is simulating an HTTP GET request on that URL. The RDF is mounted on your server, in my case it’ll be running on localhost 7474, but it’s a proper HTTP request.
I’m going to ask NSMNTX to serialize this RDF, selecting it by ID. I understand that it’s probably not the safest way to do it but that’s what I want.
Let’s take Tom Hanks.
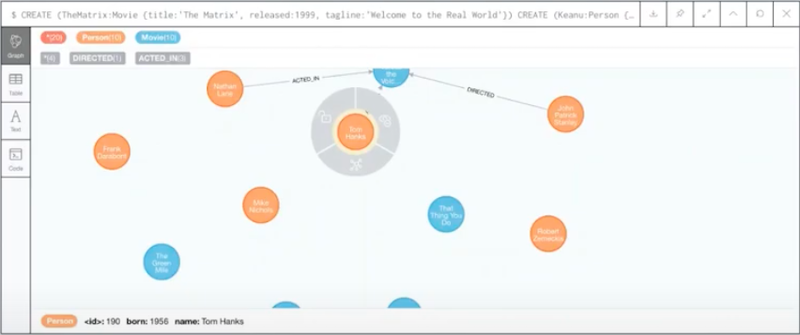
We see that Tom Hanks has 190 as his ID. I was saying it’s not safe because the ID is the internal unique identifier in Neo4j for specific nodes. You probably want to use some domain-specific nodes.
In this case, maybe the name of it’s a unique identifier, or any kind of primary key to identify a node. This is just for the example.
You select a node and when you click GET, you see that NSMNTX is producing an RDF serialization of this individual.
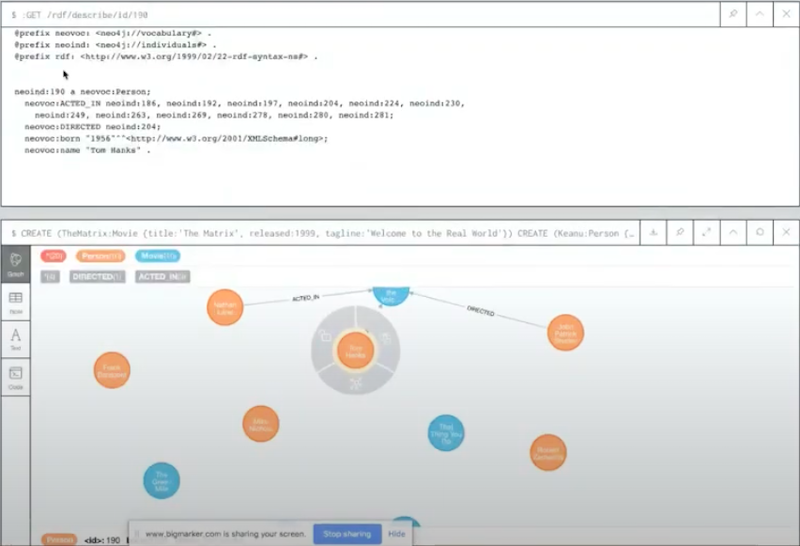
You see that this 190 is Tom Hanks – labeled as a person. I’m translating the labels in Neo4j into type statements in RDF and then the same with the properties.
Unique identifier 190 was born in 1956, has a name Tom Hanks, and has a number of relationships
acted in and directed that link it to other individuals. I am generating these unique identifiers on the fly.We have the generation of RDF on the fly from any random graph. Another thing you could do is run some random Cypher, and get the output of this Cypher serialized as RDF.
Before I do that, I mentioned before that different serializations are probably going to show if I make any mistake. You could select the type of serialization that you want and the same RDF can be generated as Turtle, by default, or you could generate RDF/XML.
You could get any variant any possible realization JSON-based with JSON or the XML-based with RDF/XML, or Turtle, but this is completely computed on the fly.
Running Cypher on the database
Let’s run some Cypher on our database and export the output as RDF.
We do this with a POST request because I’m requesting the query with some parameters. I’m sending a Cypher element which contains the Cypher that I want serialized and the serialization format that I want to use.
Instead of returning any possible triple, let’s get triples of type
directed.These will return all the paths formed by nodes connected through the
directed relationship. I run this, and if I’ve made no mistake, that would produce a larger set of course. because it’s returning all the links and nodes represented by directors connected to movies.
You are able to produce RDF on the fly from your Neo4j graph.
If the Neo4j graph is the result of importing RDF previously, you have the capability to generate exactly the same RDF that you imported. That’s what this lossless nature of the import comes into play.
What else could you do with NSMNTX?
Model mapping
First, there is model mapping.
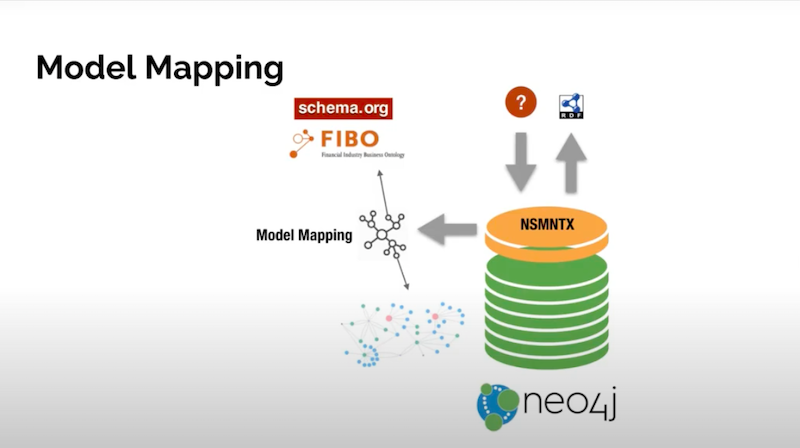
You have your Neo4j database and whatever graph. You could define a mapping between the entities in your graph and the schema of the elements in your graph.
We could use some public schema or any other public schema or ontology out there. What happens is you define this mapping and then when you run it, where mappings will be applied on the fly. You would be exporting your graph data coming from Neo4j, but describe in terms of the public vocabulary that you’re mapping to. That’s a pretty powerful capability.
There’s a number of other methods like public vocabularies, to public schemas, and then define mappings. You have all the documentations in the NSMNTX page. There’s some utility functions for listings, for dropping, for adding, etc.
Ontology management

You could publish the ontology in your graph.
I know the type of model we have because it’s the movie database. I could do something like RDF onto that and it will generate an ontology, an OWL description of the entities in my graph.
There’s a category called
movie, and there’s a category called person. There’s a number of relationships between these two things such as ACTED_IN which connects persons to movies.Because OWL is a language with vocabulary on top of RDF, you could publish your ontology. Keep in mind that this is different from manually, explicitly creating an ontology. This is an ontology that’s created on the fly. However, you could import an existing ontology and there are methods that will help you do that.
.importOntology
We have an .importOntology, which will take the ontology from wherever it lives and it will import it. Additionally, .importOntology will filter some of the elements and bring into Neo4j a simplified representation in terms of categories, subcategories, domains and range, but not much more.
This is intended to exclude explicitly some of these complex things. However, you could import ontologies using RDF, because it’s RDF in the end. That will bring a complete import of every single statement in the ontology.
Inferencing
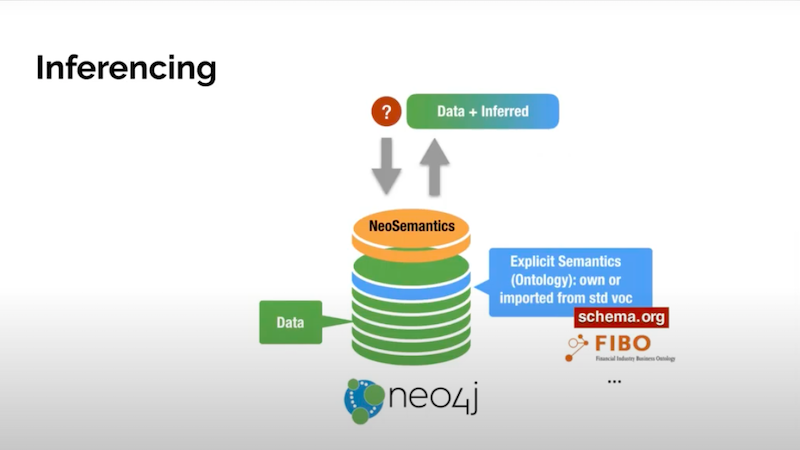
Inferencing is being able to define as data explicit descriptions or explicit behaviors that you want a general purpose engine to run. In other words, as you run you generate data derived from the data that you have in your graph. That data is computed on the fly based on certain rules which could be ontologies or rules.
We are able to do inferencing based on the type hierarchies of both nodes and relationships. A subclass of hierarchies could be used to infer labels for nodes and also for relationships as you see here.
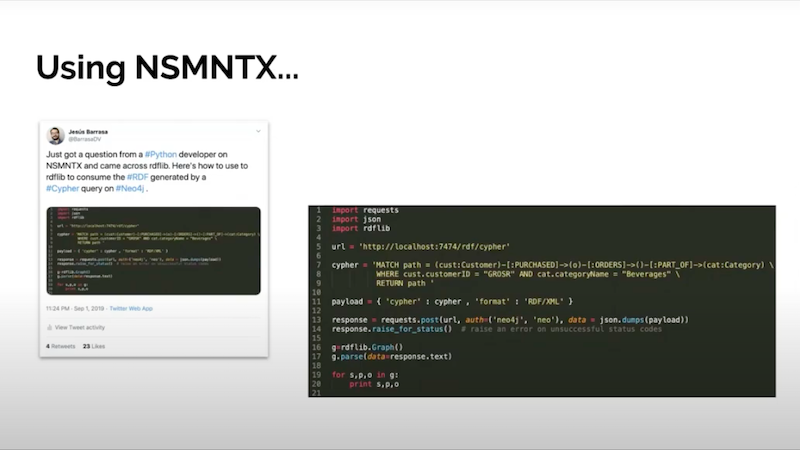
On Twitter, we met a user of NSMNTX that asked about how to use it from Python. There you have a great example of how to run a Cypher query on a Neo4j database. Serialize the output as RDF and import it directly with rdflib, which is a Python library that manages RDF.
Cloning subgraphs
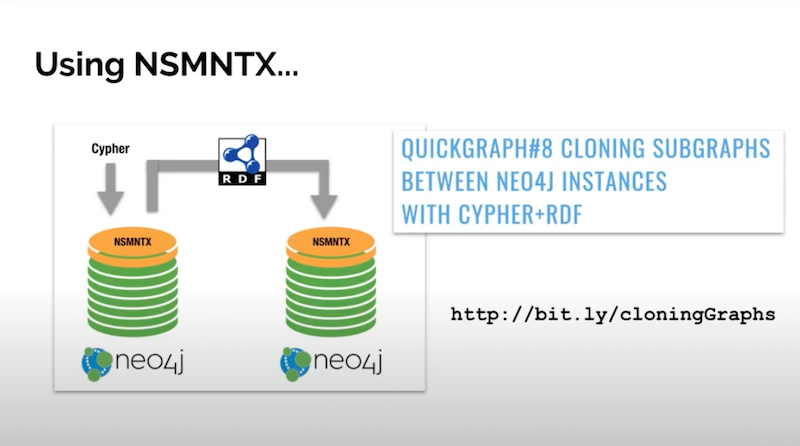
I recently wrote about the possibility of using RDF as a way of cloning graphs from one Neo4j instance to another.
You export RDF as we’ve seen out of your graph and then import it on another instance. You use RDF as the mechanism to exchange data, which is it’s intended purpose.
Conclusion
I just wanted to conclude by inviting you to join the community. Ask all your questions. Share your experiences, help grow this fantastic project and contribute to building it.
Above is the source code and anyone who wants to add to it is more than welcome.
Want to engage with more technical talks like this one? NODES 2020: Neo4j Online Developer Expo and Summit is happening on October 20, so be sure to save your spot today!
Save My Spot
Save My Spot





