



Today we’re going to be talking about some Neo4j tools and integrations for NoSQL polyglot persistence:
As a member of the developer relations team at Neo4j, I talk to a lot of users who frequently ask whether or not Neo4j will work with a certain language, database, or framework (such as Spring Data, Docker and Spark). Can we move data back and forth?
These are always valid questions — when you’re evaluating a technology, you need to know how that technology can be incorporated into your existing stack. I’m going to answer these questions by reviewing a variety of tools and integrations that are available for use in conjunction Neo4j.
Why Polyglot Persistence?
Polyglot persistence is the idea of using multiple databases to power a single application. A typical polyglot deployment might look like this:

Our application talks to multiple databases and internally we make ad hoc analyses, BI queries, and other similar actions. It could be that we are using this type of deployment for legacy reasons, or that we’re trying to take advantage of polyglot persistence:
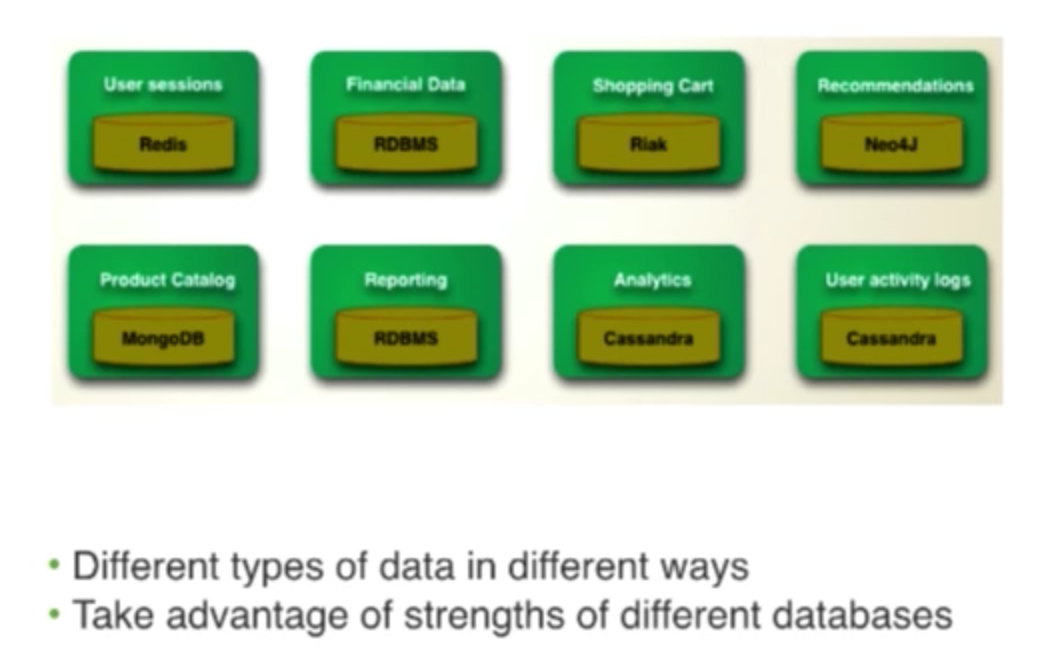
Martin Fowler is one of the first people to talk about taking advantage of the strength of different database technologies. Because different technologies are optimized for working with certain types of data, when you put them all together, you end up with an incredibly powerful tool.
Consider a typical e-commerce application. We might be using something like Redis, a key-value store for the shopping cart where we’re interested in very quick reads and writes. However, in this case, we don’t need to perform complex queries on this particular set of data. We have the ID for my shopping cart session, so I can pull that out very quickly. We might use a document database to store a lot of information about our products in a product catalog, for which we need to be able to perform text searches and return lots of JSON to populate the view in our application. For recommendations, we might use a graph database like Neo4j because we know that this tool is great for generating recommendations.
This type of polyglot deployment might be typical for an e-commerce application:
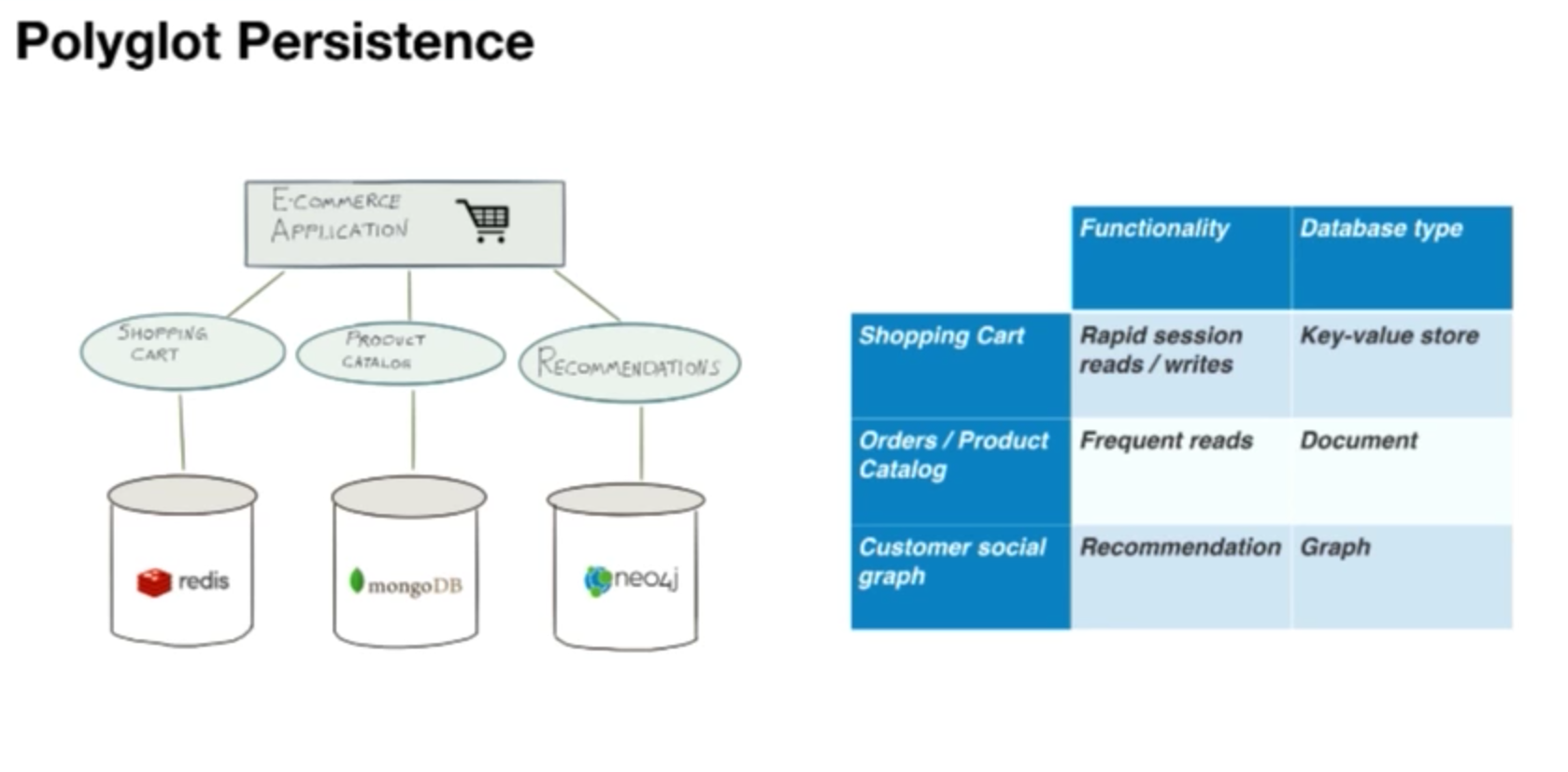
However, the benefits of polyglot persistence don’t come for free; it does result in some added complexity. But at Neo4j, in partnership with our community, we’ve developed some tools that make working in polyglot environments much easier.
Using Polyglot Persistence: How To Keep Data In Sync
The first challenge I want to talk about is data sync: if we’re using multiple databases, how do we keep the databases in sync while we move data back and forth?
In a polyglot deployment into which we’re introducing Neo4j, we have three options. The first is to migrate all of our data into Neo4j. The second it to migrate a subset of our data and queries into Neo4j: graph data and queries go to Neo4j while our non-graph data and queries go to our relational or document database. The third option is to duplicate a subset of the data, so that all of our data goes into our relational database and of that, we move the graph pieces into Neo4j:
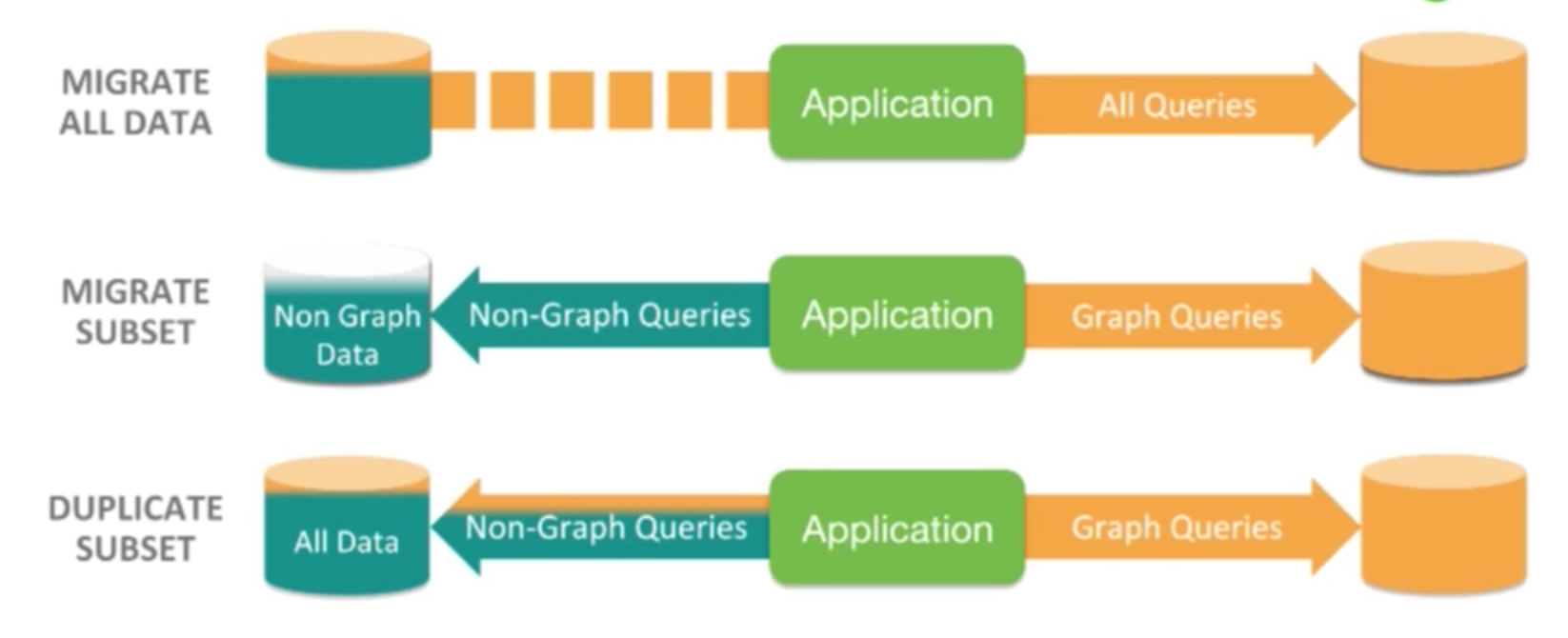
Let’s take a look at an example application where we’re taking the third approach, duplicating a subset of data. Below is a course catalog for an online platform of courses:

In this tool, the user is searching and browsing for courses they might be interested in. The user needs to be able to do a text search, a date-range search and to filter by category, as well as to return lots of text and images to populate this view in our application. This is actually a great use case for a document database, so we’ll use MongoDB.
But, something is missing in this view. Once a user is logged in, the site knows the courses that user has taken and how they’ve interacted with the site and other users on the site. Because of this, we should really be able to provide course recommendations based on the other courses the user has taken. We know that Neo4j is great for generating recommendations, so we may want to use our document database for our standard product catalog features and Neo4j for generating recommendations.
The question is, if we’re using MongoDB to store our product catalog information about courses the user has already taken, how do we get that information into Neo4j so that we can perform these graphy recommendation queries?
Neo4j Doc Manager to Automatically Sync Data
The first tool I’ll go over is the Neo4j Doc Manager. This is a project that is designed to automatically sync documents from MongoDB into Neo4j by converting data from a document format into to a property graph model. There’s also a lot of information about this available online.
Let’s go through a really high level overview of how this works:

This tool essentially tails the Mongo OPLOG — which is the transaction log for Mongo — so that it’s notified of any updates that take place in Mongo. These are converted into Cypher and streamed over to Neo4j to ensure the graph database is updated along with MongoDB.
But how can we convert a document into a graph? Let’s look at a simple example, below:
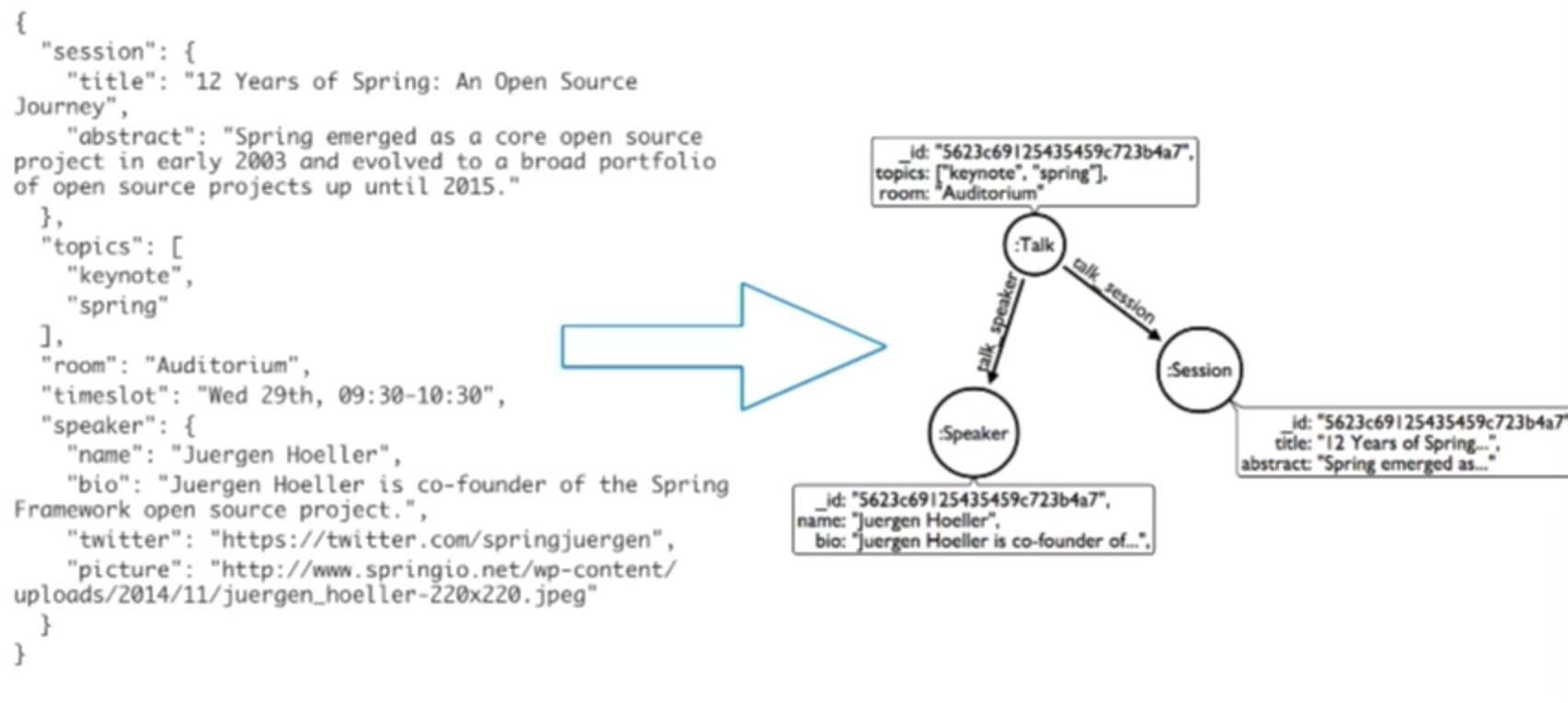
On the left is a document that describes a talk at a conference. We have one root-level document, a couple of nested documents, session subdocuments, and a speaker subdocument. If we were to insert this into Mongo using the Neo4j doc manager, we would end up with the graph on the right. We have one node with a “talk” label, which comes from the talk collection in Mongo. We have two nodes for each of the subdocuments — speaker and session — with their relationship to the root-level document. And we’re storing properties from the root-level and nested documents on the nodes as well. This is also all available as a Python command-line application. There is also a similar community-developed tool for Couchbase.
Neo4j Docker Image for Deploying Multiple Databases
Now we have two databases that we need to deploy along with a Python service that needs to listen to both of them. This complicates my deployment and operations.
At Neo4j, we love Docker because it provides a way to bundle software and all of its dependencies into a standard unit called a container, which is defined by an image. At Neo4j, we have an official Docker image that is maintained by our engineering team and is available on Docker Hub. If you want to pull down and run Docker or Neo4j in a Docker container, just Docker pull Neo4j and you’re good to go — you don’t have to worry about other dependencies.
For polyglot deployments, there’s a tool called
Here’s how we deploy Mongo, Neo4j, and this Python Neo4j Doc Manager in our course catalog example:

First we specify one container using the Mongo image, and when that starts up, we indicate that we need to create a replica set so that we can tail the transaction log. We define a container and expose a port for Neo4j. Then we have another container for the Mongo connector project based on a Python distribution on Ubuntu, and we link the Mongo connector container to the Mongo and Neo4j container. When that starts up, we install Doc Manager and start the Mongo connector service. Once we define this, it’s just Docker Compose up. Docker pulls down all of the dependencies that we need, and we can run this locally and play it to the cloud.
The Neo4j Cassandra Data Import Tool for Inconsistent Data Models
We’ve hinted at another challenge of these polyglot environments surrounding data models. Each database has its own specific type of data model: we have property graphs, document databases, key-value stores, and column family data models. And translating back and forth between these can be a challenge.
Let’s take Cassandra, which is a column family database, as an example. This is a fundamentally different model from a property graph because there is no concept of relationships. That doesn’t mean we don’t have relationships in our data; it just means they’re not expressed in the data model. So how can we pull out some data from Cassandra into Neo4j and take advantage of the relationships that are present?
For that, we have tool number three: the Neo4j Cassandra Data Import Tool. This is another Python tool that uses both the Neo4j and Cassandra drivers. First we inspect the Cassandra instance and look at the schema of that instance, and then we apply some basic rules for translating the model: tables, artist column families, and tracks all become nodes. The letters inside the curly brackets { } are what allow us to configure how we want to map the data model from Cassandra — which is column family oriented — to a property graph. In the below example we are tying a music track to a specific artist

With the Neo4j Cassandra Data Import tool, we can generate LOAD CSV Cypher which allows us to efficiently import data into Neo4j:

This is automatically generated based on how we’ve defined this mapping in our data model from column family to graph. With the LOAD CSV statements that are executed with this tool, we can import a subset of our data from Cassandra into Neo4j and start using Cypher to take advantage of the integration relationships in our data.
Neo4j 3.0: New, Powerful Tools for Data Integration
There are a number of updates introduced in Neo4j 3.0 that greatly impact how we can build these types of tools and integrations. Those include updates related to stored procedures, Bolt, and drivers.
Updates to Stored Procedures
Let’s go over stored procedures first, which are user-defined procedures written in Java, deployed into the database, and are callable from Cypher. These are already built in, so we can sayCALL db.labels to get back all of the labels that currently exist in our database. These are contributions from the community as well as people from Neo4j, and are in the Neo4j Contrib GitHub repository.This is a library of around 100 awesome procedures — APOC — that includes things such as
Call apoc.meta graph. This will inspect our database and draw the graph of our data model. For example, if we ran that on our movie graph, we could see that a certain person directed movie, a certain person reviewed movie, etc.One section I want to talk about in particular is how we can load data from a relational database using a procedure. Let’s look at a specific example using Northwind, which is a canonical relational example. It deals with customers, their orders, products and employees that fulfill the orders. We’re going to focus on just a subset of this data: orders, products, and customers.

If we were to import this into Neo4j, it might look something like this:
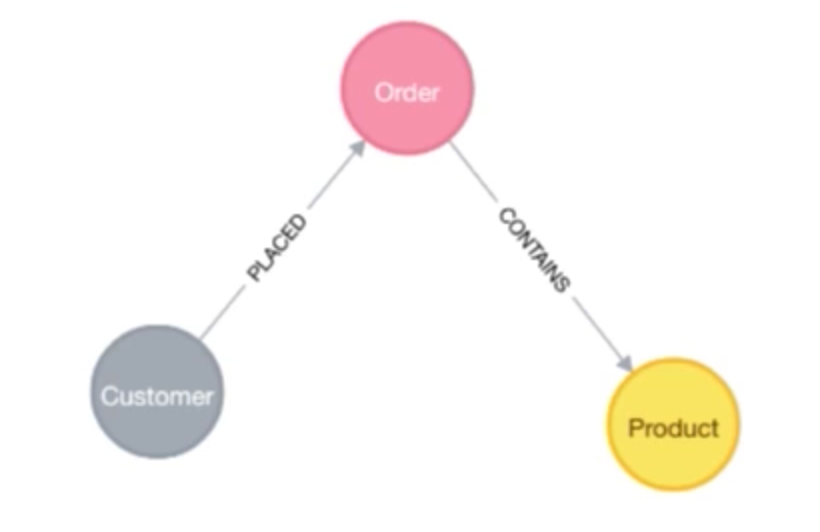
The following demo reviews how to import data from a relational database into Neo4j without leaving Cypher:
Updates to Bolt, Neo4j’s Binary Protocol
The other big update to Neo4j 3.0 was in Bolt, which is this binary protocol for Neo4j. We now have official language drivers in Java Script, .NET, and Python that implement the Bolt protocol. This allows us to do things such as build a Neo4j Spark connector, quickly stream data out of Neo4j into Spark, and quickly write those updates back to Neo4j.
It also allows us to build embeddable graph visualizations in Java Script:

While the Neo4j browser is great as a work bench, sometimes we want to embed visualizations into our application. For example, we may want to be able to say that a certain node property indicates the size we want that node to be in a visualization because maybe it’s a measure of centrality or importance in the network. Or maybe we want to specify edges and group colors in a certain way.
Below is a quick demo of a project I’ve been working on, which is built on top of the Javascript visualization tool Vis.js and combines the Bolt Neo4j Javascript driver. This tool generates the Cypher request necessary to pull out the relevant data:
If you want to learn more about any of the tools included in this post, please visit Neo4j for Developers. It includes code snippets for a number of drivers that are relevant for specific use cases, and includes a number of additional tools that are outside the scope of this presentation.
Take your Neo4j skills up a notch: Take our online training class, Neo4j in Production, and learn to scale the world’s leading graph database to unprecedented levels.





