NeoConverse - Graph Database Search with Natural Language
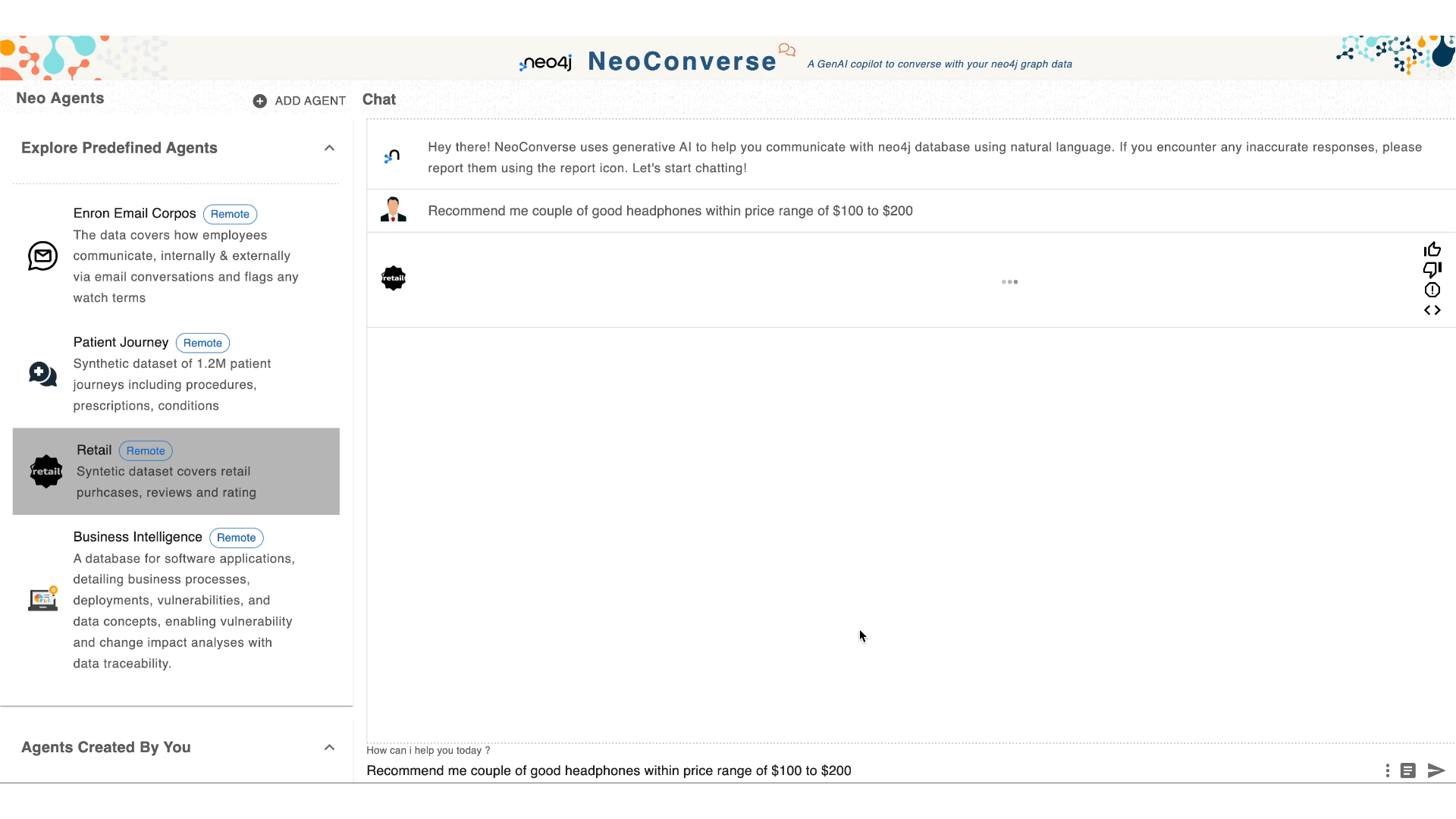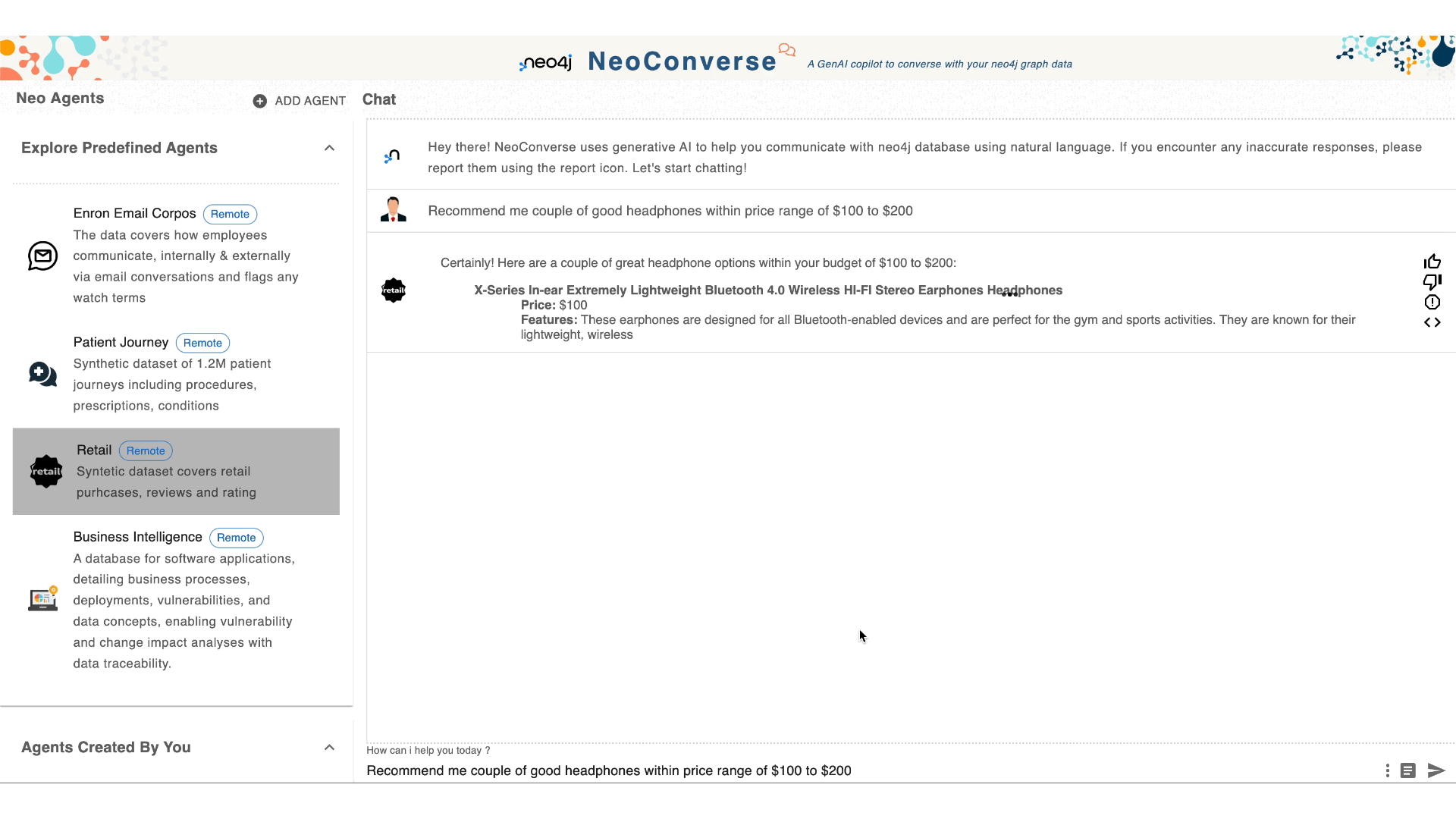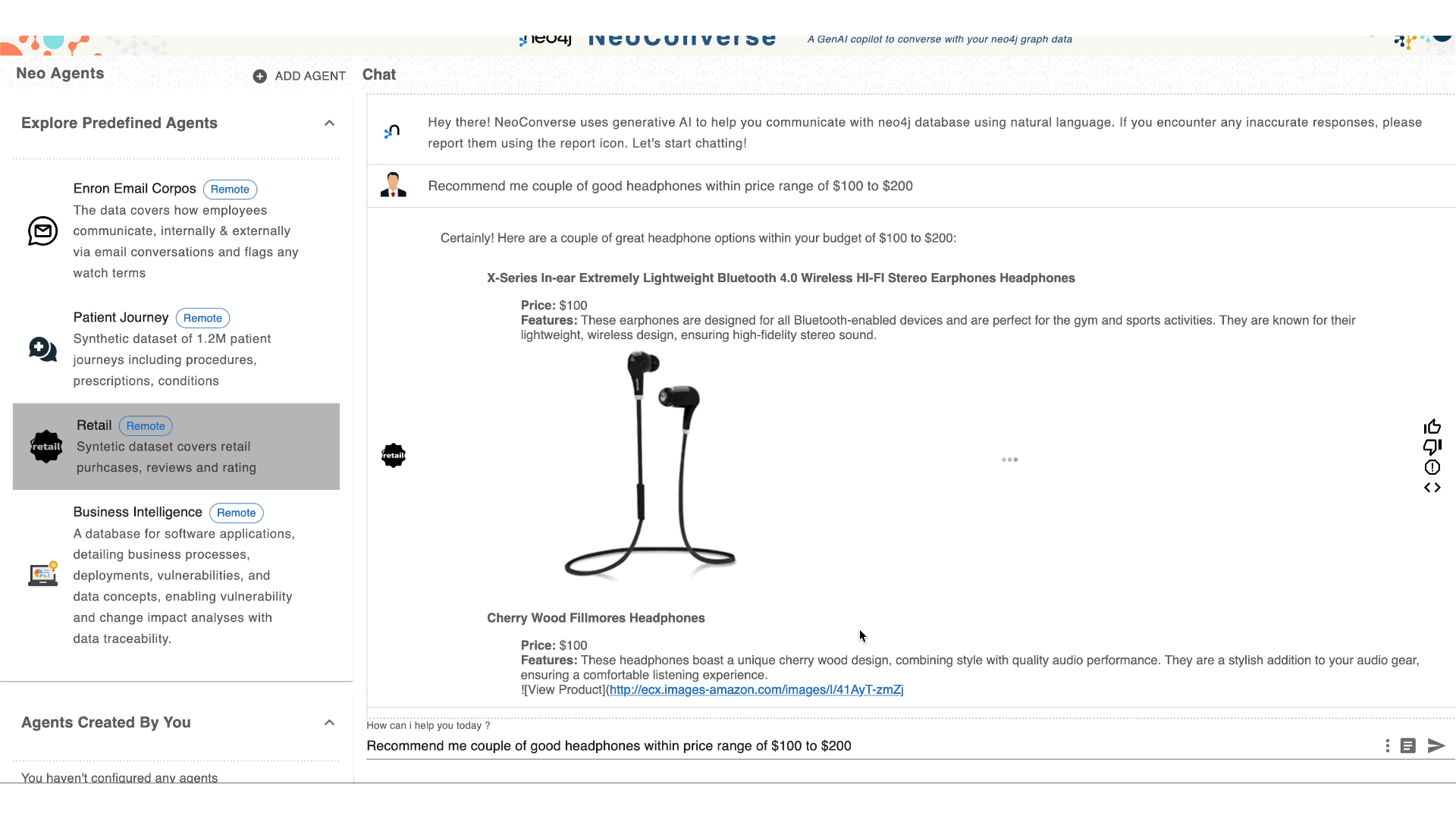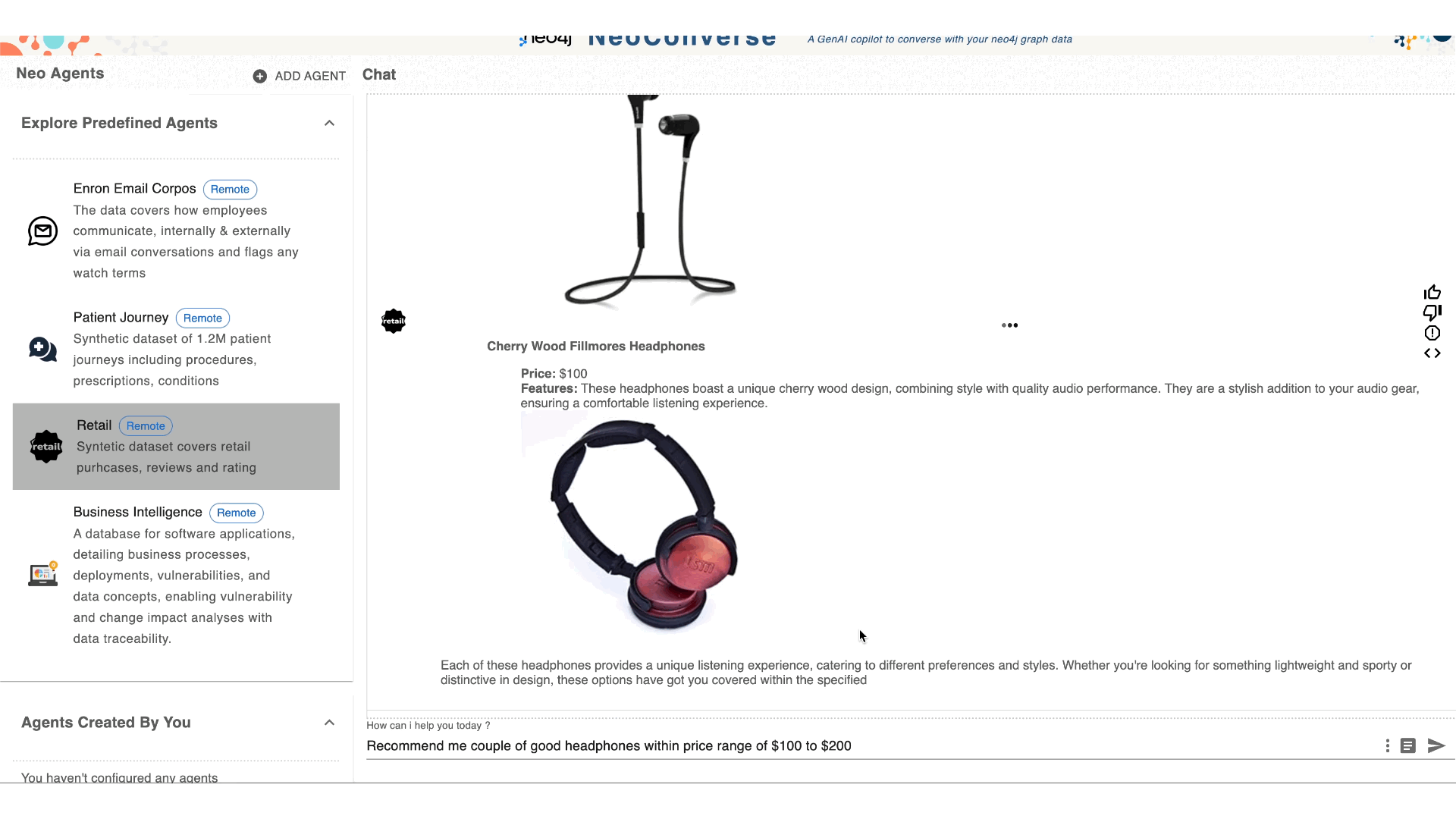
NeoConverse is an application to demonstrate natural language database search with GenAI. It makes existing graph databases available to non-technical users, allowing them to issue natural language questions. Using the graph database schema, question-statement examples, and fine-tuning, the natural language question is translated by an LLM to a graph query (Cypher). Which is then validated and executed against the database.
The query results are sent with the user question to the LLM to generate a natural language answer. Alterantively the LLM can be configured to generate the data an configuration to render the results of the query as a chart for visual representation.
Functionality Includes
-
Experiment with different cloud providers' GenAl models: Currently supported are GCP and OpenAI, with AWS Bedrock coming soon.
-
Connect your own neo4j databases as agents in NeoConverse and interact with them in plain English:
-
Configure schema information as context for the large language model (LLM).
-
Optionally add a few-shot examples to provide in-context learning to the LLM.
-
Save the conversation in a configured database for future analysis:
-
Evaluate the LLM responses.
-
Rank the responses and use them to improve future LLM interactions
-
Prompt engineering adjustments.
-
-
-
Generate chart visualizations from natural language questions.
-
Interact with predefined agents from different domains:
-
Chat with these agents.
-
Explore the data model of the predefined agent datasets.
-
Loaded with sample questions to get you started.
-
Configuring Agents
NeoConverse includes with selection of predefined conversational agents, each backed by Neo4J database,
To explore and converse with Neo4j database using these agents, user can select any agent from the Explore Predefined Agent section.
Upon selection, users can engage with the chosen agent through the chat interface displayed on the right side of the screen.
This enables users to interact directly with the database graoh, faciltating an interactive exploration of the knowledge graph.
Users have the flexibility to add your own local agents that are backed by your organizations neo4j database, and start interacting with your database knowledge graphs.
Below is the quick visual guide to ADD, DELETE, EDIT agents, and interact with your own database
|
When integrating your own agents, be aware that these agents are stored in the client’s browser storage and not on a server. This means that all interactions, including API calls and result processing, happen on the client side and do not reach our servers. Consequently, if the browser’s local storage is cleared for reasons such as browsing data cleanup, selection of "cookies and other site data", or when local storage capacity is exceeded, all custom agents will be permanently lost. |
|
We are considering future updates to enhance user experience. These updates may include capabilities for the export/import of agents and the persistence of user-defined agent configurations within the user’s own database. Such features aim to provide a more unified and simplified experience across different users and sessions. |
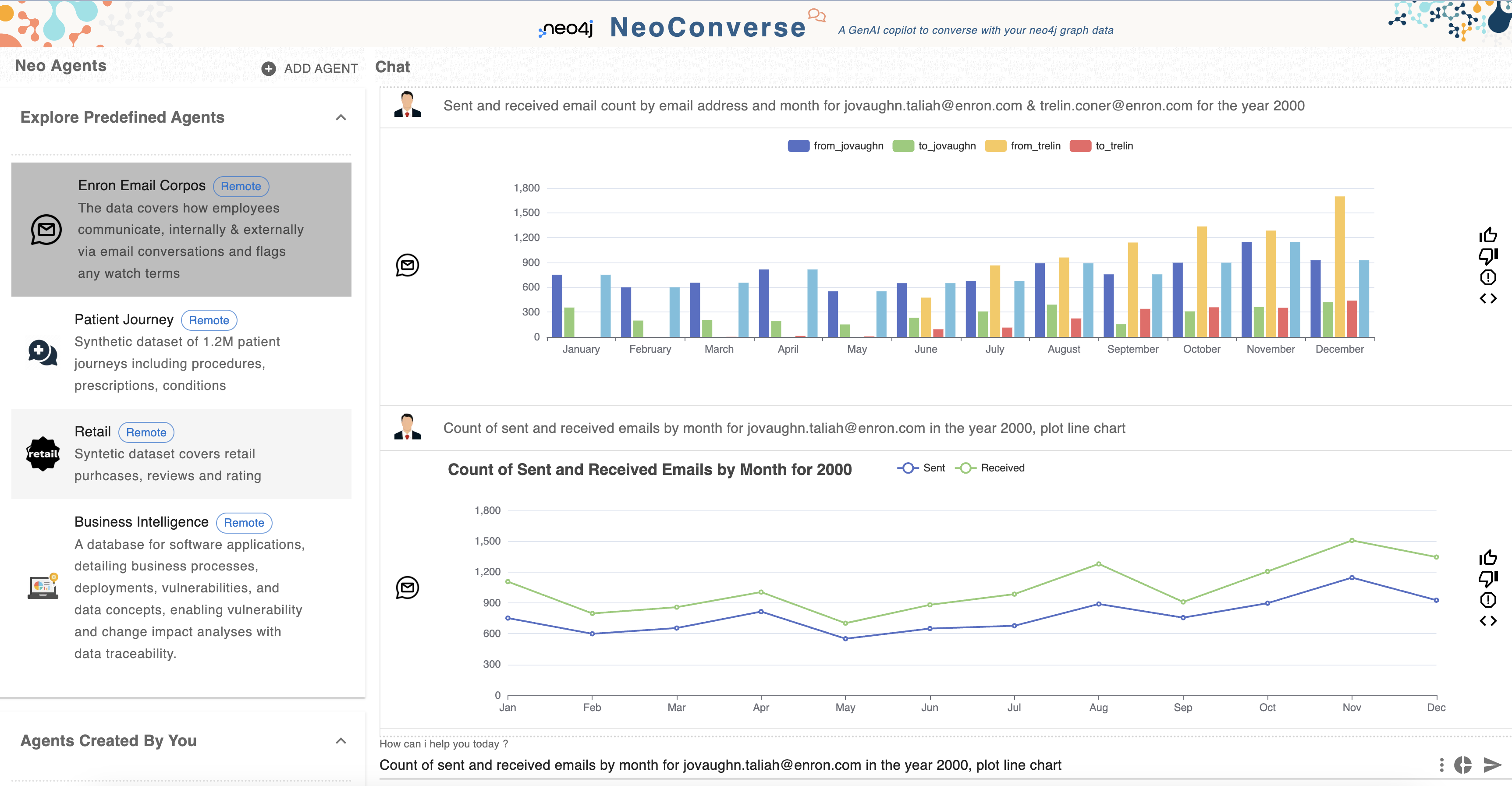
Generating Chart Visualizations
NeoConverse empowers users to create chart visualizations directly from the chat interface. By switching between the text input and a chart icon within the chat window, users can seamlessly transition their queries into visual representations. Here’s how it works: Users pose their question in plain English, which is then transformed into a Cypher query for execution in the Neo4J database. Following this, the query results are passed to a Large Language Model (LLM), which generates chart metadata based on the data. The LLM intelligently selects the most appropriate chart type for the data at hand and returns the corresponding chart metadata. This metadata is then used to render the chart, enabling users to visualize and interpret the data insights more effectively and in an easily consumable manner.
Looking ahead, NeoConverse is considering the expansion of its visualization capabilities to include graph visualizations. This development will be contingent upon the interest and feedback from NeoConverse users, potentially broadening the scope of interactive data exploration.
How NeoConverse Works: Overcoming LLM Limitations
Large Language Models (LLMs) are trained on massive public datasets, making them adept at tasks based on that knowledge. However, their usefulness in enterprise settings is limited because:
-
Their knowledge is confined to the training data.
-
Updating their knowledge with internal data can be challenging.
-
Information may be outdated.
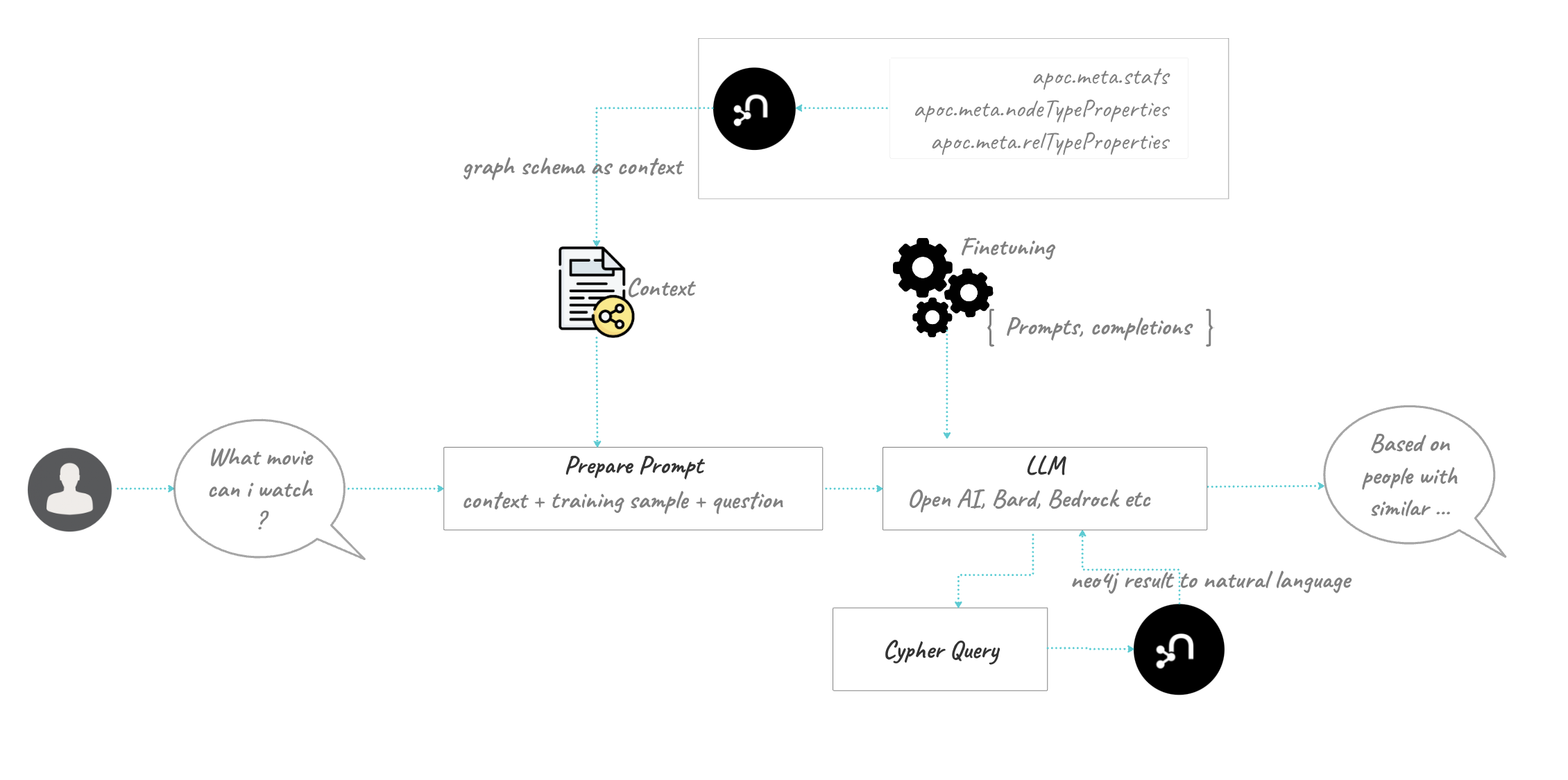
NeoConverse leverages Retrieval-Augmented Generation (RAG) to address these issues. RAG provides LLMs with additional context retrieved from internal data sources hosted in Neo4j graph databases.
Here’s the step-by-step process of how NeoConverse works:
-
User Asks a Question: The user asks a natural language question about their enterprise data stored in Neo4j.
-
Context for LLM: NeoConverse provides the LLM with context relevant to the question:
-
Schema information about the data stored in the Neo4j database.
-
A few relevant examples from the data to guide the LLM.
-
-
LLM Generates Cypher Query: Based on the question and context, the LLM generates a Cypher query, the query language for Neo4j.
-
Query Refinement and Execution: NeoConverse cleans, formats, and executes the Cypher query on the Neo4j database.
-
Data Retrieval: Relevant data is retrieved from the Neo4j database based on the executed query.
-
LLM Answer Generation: Finally, the LLM uses the retrieved data and the original question to generate an accurate and relevant answer that’s grounded in the user’s specific data.
By leveraging internal data, NeoConverse empowers LLMs to provide more accurate and relevant answers to user queries within an enterprise setting.
Available predefined datasets
-
Enron Email Corpus Dataset: The subset of publicly available enron email corpus data has been anonymized and ingested in neo4j database, the ingested dataset contains about 500K email messages, The dataset facilitates an in-depth exploration of email communication both within enron leadership internally and with external parties, providing means to analyse anomolies and email leakages. In addition to email communcation metadata, this dataset also enriched with entities and watch terms extracted from email subject & body.
-
Patient Journey Dataset : The patient journey dataset encapsulates the healthcare experiences of 1 million patients, detailing 41 million encounters that span doctor visits, diagnoses, treatments, and allergies, among other medical events. With 11 million prescriptions, 26 million observations, 9 million condition-specific observations, 200 unique conditions, and 500K allergy encounters, this rich dataset offers a comprehensive view of individual health narratives. It’s a crucial resource for analyzing treatment patterns, patient outcomes, and drug efficacy, providing insights that can enhance healthcare delivery and personalize patient care strategies.
-
Retail Dataset : This retail dataset leverages a knowledge graph built from a public Amazon electronics dataset containing product information, reviews, and user purchase and review history. To extract deeper insights, Neo4j GDS graph algorithms have been applied to calculate similarity scores between users and products, considering not only product features and user demographics but also how users interact with the products.
-
Business Intelligence: Its a Knowledge graph of Software Applications with supported business processes, deployed instances, software vulnerability reports, and data concepts that provides impact analysis for vulnerabilities as well as impact analysis for application changes and data traceability
Enhancing NeoConverse
NeoConverse relies on Large Language Models (LLMs) cypher generation capabilities, while LLMs have shown improvements in generating Cypher queries, yet inconsistencies persist. NeoConverse is designed to identify these inconsistencies, providing users with effective ways to navigate or bypass them, rather than confronting them with raw errors. This approach ensures a smoother user experience.
In future NeoConverse can be enhanced to mitigate these inconsistencies by:
-
Fine-Tuning LLMs: Finetune LLMs for cypher generation for more accurate and consistent Cypher queries.
-
Developing a Semantic Layer: To deepen LLMs' contextual understanding, improving result accuracy.
-
Incorporating Domain-Specific Nomenclature: To increase the relevance and precision of queries.
-
Leveraging Historical Conversations: Using past interactions to provide richer context and more relevant examples to LLMs.
These initiatives aim to address current challenges and improve the reliability of LLM-generated Cypher queries in NeoConverse.
Installation
The Demo is available online, https://neoconverse.graphapp.io
You can also run it locally, by cloning the repository and following the instructions in the README.md file.