


Mapping the PMBOK Standard as a Graph Database

Management Consultant, GestioDinamica EIRL
4 min read

Within the project management community, the Project Management Body of Knowledge® (PMBOK) Standard, published by the Project Management Institute (PMI®), is a well-known compilation of project management best practices.
Its earliest versions (back in 1980) were organized by knowledge areas, groups of processes and processes with inputs and outputs. Even then, there were some inconsistencies because not all the concepts were mature enough.
The Interdependencies of the PMBOK
But during the intervening decades, project management practice evolved in interesting ways. For instance, the accuracy to defining what is a proper scope — or the fact that every scope is built as a structured set of deliverables and requirements — encouraged project management practitioners to increase the accuracy of their defined inputs and outputs. These definitions would then trickle down into other chains and flows throughout the whole project lifecycle.
For example, a project management process called “Collect Requirements” has five input elements and two output elements. The output elements are “Requirements Traceability Matrix” and “Requirements Documentation.”
But the element called “Requirements Traceability Matrix” is also an input for another project management process called “Scope Control,” and so on. In addition, the process “Collect Requirements” belongs to the Planning Process Group, whereas “Scope Control” belongs to the Monitoring and Control Process Group.
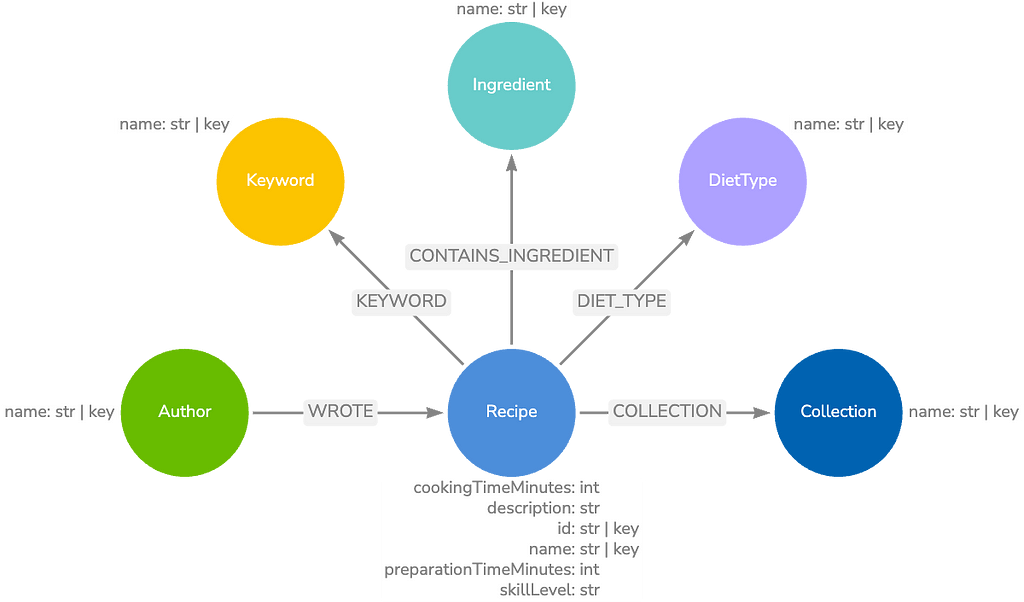
Why the PMBOK Standard Is a Perfect Graph
So, as you can see below, there are clearly identifiable nodes and relationships when it comes to these project management dependencies.

Project management best practices are also well fit for a graph database because processes and elements fit perfectly as properties. Here are a few examples:
Processes
-
- Name
- PMBOK Code
- Process Group: Initiation, Planning…
- Knowledge Area: For example Scope Management, Time Management…
Elements
-
- Name
- PMBOK Code (although it can be unified when the element is at the same time input for one process and output for another process)
Organizing the PMBOK Standard
Neo4j proved to be a brilliant opportunity to organize the PMBOK Standard as a graph database.
In November 2014, I submitted a paper to the PMI 5th International Congress (South Cone Tour) in Santa Cruz, Bolivia. Despite most project management practitioners not having a background in graph databases, the concept of organizing the PMBOK Standard as a graph was well-received by all in attendance.
Loading the PMBOK Standard data in Neo4j, I was able to complete queries like these:
Query:
I want to know how the circuits are only for Scope Management Processes.
MATCH (p:Process {parea: ‘Scope’}), (e:Element), (p)-[r]-(e)
RETURN r
Query:
I would like to know what elements come out from planning processes and feed monitoring processes.
Cypher:
MATCH (p:Process {pgroup: ‘Planning’}), (q:Process {pgroup: ‘Monitoring’}), (e:Element), (p)-[r]->(e)-[s]->(q)
RETURN r,s
Query:
I want to know the quantity of inputs for time management processes, making a list beginning with the process with more inputs.
Cypher:
MATCH (p:Process {parea: ‘Time’}), (e:Element), (e)-[r]->(p)
RETURN p.name, count(r) ORDER BY count(r) DESC
The image for the third query is shown below:

In this graph above, blue nodes are elements and yellow nodes are processes. Green arrows represent that the element is an output and red arrows that it is an output.
Once we get used to the sequence between green and red, we can easily understand how the project management concepts flow from process to process, being able to explain how the Standard describes the ideal functioning of the project.
Future Work with the PMBOK Standard and Graph Databases
Of course, there are some discoveries to make, such as which elements are generated by a process but are not connected to any other process, or which elements are overloaded with arrows that they are candidates to be separated in different elements.
Looking at the whole shape of the nodes conglomerate we can see clusters of processes that are more or less close to each other, but this is just the beginning. The opportunity for management professionals diagramming their Standards is huge.
Unfortunately, I am not an information technology engineer, but I was able to understand the logic behind a Standard and match it with a graph database manager like Neo4j.
I would like to work further with developers and experts to make these tools more accessible via web platforms. I’d also love to make the most of Neo4j tools so that project management practitioners who are not involved with graph databases are still able to understand the deep details of their frameworks.
Conclusion
This post was about using Neo4j to organize presentations about the PMBOK Standard, but the potential for project management can go well beyond the Standard.
Future practitioners might be able to configure a detailed project scope, specify requirements or even enhance the visual tools to make decisions. I’m excited to tackle these future projects by working together with the Neo4j community.
Want to learn more about graph databases? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technologies for your mission-critical application today.
Share Article


Explore
Related Articles



Neo4j Text2Cypher: Analyzing Model Struggles and Dataset Improvements

