Neo4j is Built to Perform at Scale
Thousands of companies, with more than 50 of the Global 2000, rely on Neo4j
to enable mission-critical applications.
Whether serving up online recommendations to millions of web users, managing master data hierarchies, or routing millions of packages per day in real time, Neo4j is built to perform at scale. Neo4j’s native graph architecture combines blazing-fast connected queries with near-linear read scalability, combining high-availability clustering with robust transactional guarantees.
With Neo4j Enterprise, you get:
 High-Performance Cache
High-Performance Cache
 High-Performance Cache
High-Performance CacheIncluded in Neo4j Enterprise is a high-performance cache, that when enabled, can provide up to 10x the performance under concurrent load.
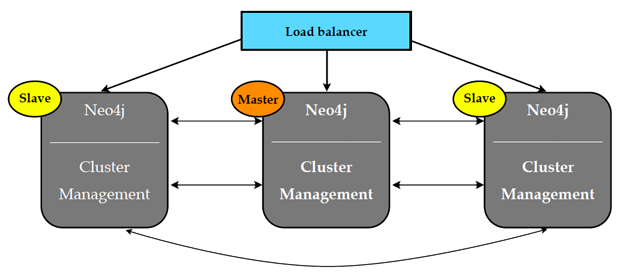
 Clustering/Cache Sharding
Clustering/Cache Sharding
 Clustering/Cache Sharding
Clustering/Cache ShardingNeo4j clustering provides scale-out capability for reads: letting you spread out your graph in memory, while ensuring each instance is able to get to any node or relationship at any time using its own local copy. Neo4j’s architecture allows you to maintain blazing speed as your graph grows, while providing high availability via a master-slave HA protocol.
Hot Backups
Hot backups, available in Neo4j Enterprise, let you take point-in-time backups while the database is running, allowing 24×7 operation, without compromising your availability, or the quality of your backups.
 Advanced Monitoring
Advanced Monitoring
Advanced Monitoring provides operational metrics not available in the Community Edition, making it easier to manage your system and keep it running healthy
“Minutes to Milliseconds” Performance
Neo4j handles connected data queries up to a thousand times faster than other kinds of databases. Even on very modest hardware, Neo4j can handle millions of traversals per second between nodes in a graph on a single machine, and many thousands of transactional writes per second. This extreme speed is the result of an architecture that is natively engineered to store and process graph data.
"The challenge was speed. Due to the rate of growth we saw from our competitors in the Chinese market, we knew that we had to launch Chitu as quickly as possible."
– Bin Dong, Manager of Development at Chitu, LinkedIn China
on why they selected Neo4j for the project
Instead of chaining together index lookups to relate data for each traversal, the Neo4j query engine leverages a unique feature of Neo4j’s native graph storage engine known as “index-free adjacency”. This highly-optimized means of retrieving connected data lets the database traverse a graph using direct pointer lookups for each hop, bypassing indexes altogether. This is not only orders-of-magnitude faster than joining with an index; it also provides constant-time traversal characteristics for the majority of data. Unlike relational and other databases, most queries don’t slow down as the database gets bigger. Further, by ensuring that each instance has access to all of the data in the graph, we ensure that query time remains fast, predictable, and constant as you add instances to the cluster.

Understanding Neo4j Scalability
Scalability means different things to different people. The Neo4j scalability package is known as high availability, or HA. This whitepaper helps you understand what it means to scale with Neo4j, and what HA provides.