Modeling the TOUR DE FRANCE 2014 in a Neo4j Graph Database
Modeling the TOUR DE FRANCE 2014 in a Neo4j Graph Database

The FIFA World Cup’s hottest matches are nearer and nearer and we are having lots of fun not only watching TV but also working with Neo4j.
As a cyclist, I’d like to have some fun with Tour De France 2014 as well. In particoular I dedicate this work to all my Neo4j friends living in London, who will have the chance to see this event live tomorrow July 7th, since tomorrow the 3rd étape of the 101st Tour de France edition will take place in London.
So, let me introduce you to one of the hardest but at the same time most amazing event in the world.
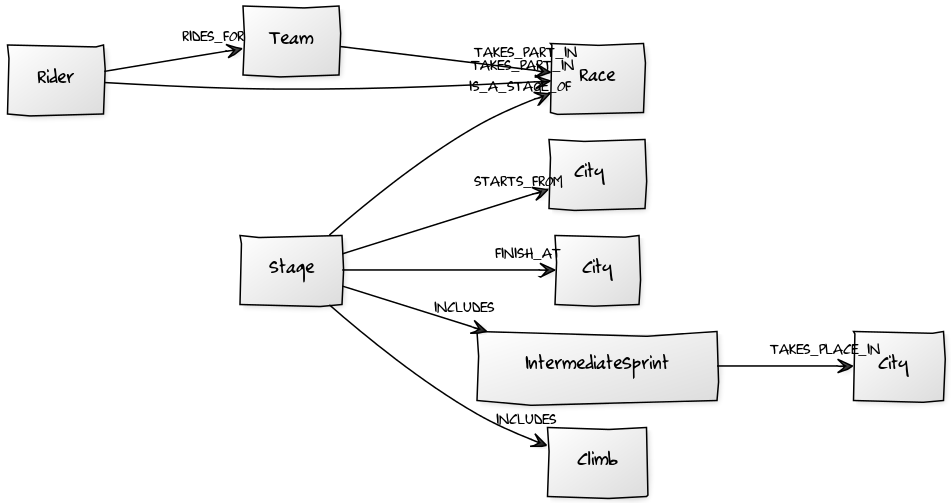
2. Loading data into the graph database

Neo4j 2.1.2 introduces the LOAD CSV feature: a fast and easy way to load data into the graph database from a comma-separated values file. We can do that either via FILE or HTTP protocol, the same way we are used to doing it when we digit an URL on the browser navigation bar.
2.1 Loading Teams and Riders
First of all, I loaded TEAMs and RIDERs by executing the following Cypher statement:
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/inserpio/tour-de-france-2014/master/tour-de-france-2014-0001-teams-and-riders.csv" AS csvLine
MERGE (r:Race { id: toInt(csvLine.RACE_ID), name: csvLine.RACE_NAME, from: csvLine.RACE_FROM, to: csvLine.RACE_TO, edition: csvLine.RACE_EDITION, distance: csvLine.RACE_DISTANCE, number_of_stages: csvLine.RACE_NUMBER_OF_STAGES, website: csvLine.RACE_WEBSITE })
MERGE (t:Team { id: toInt(csvLine.TEAM_ID), name: csvLine.TEAM_NAME, country: csvLine.TEAM_COUNTRY, sportingDirectors: csvLine.TEAM_MANAGERS }) MERGE (p:Rider { name: csvLine.RIDER_NAME, country: csvLine.RIDER_COUNTRY })
CREATE (t)-[:TAKES_PART_IN]->(r)<-[:TAKES_PART_IN { number: toInt(csvLine.RIDER_NUMBER), info: csvLine.RIDER_INFO }]-(p), (p)-[:RIDES_FOR { year: toInt(csvLine.RACE_YEAR) }]->(t);Apart from the LOAD CVS syntax, it’s interesting to note the usage of toInt() and toFloat() to properly set the data type. That is because "Cypher reads all CSV columns as Strings by default".
I also used MERGE because some of the data in the CSV file are redundant and I didn’t want to duplicate those nodes.
2.2 Loading Étapes
Second, I loaded STAGEs. A STAGE starts from a CITY, finishes in another CITY and may INCLUDE some CLIMBs and an INTERMEDIATE SPRINT. Geo data could be used together with Spatial Plugin.
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/inserpio/tour-de-france-2014/master/tour-de-france-2014-0002-stages.csv" AS csvLine MATCH (r:Race { id: 1 })
MERGE (s:Stage { name: csvLine.STAGE_START + " / " + csvLine.STAGE_FINISH, number: toInt(csvLine.STAGE_NUMBER), type: csvLine.STAGE_TYPE, date: csvLine.STAGE_DATE, distance: toFloat(csvLine.STAGE_DISTANCE), info: csvLine.STAGE_INFO})
MERGE (cs: City { name: csvLine.STAGE_START, country: csvLine.STAGE_START_COUNTRY, lat: toFloat(csvLine.STAGE_START_LATITUDE), lon: toFloat(csvLine.STAGE_START_LONGITUDE) })
MERGE (cf: City { name: csvLine.STAGE_FINISH, country: csvLine.STAGE_FINISH_COUNTRY, lat: toFloat(csvLine.STAGE_FINISH_LATITUDE), lon: toFloat(csvLine.STAGE_FINISH_LONGITUDE) })
CREATE (s)-[:IS_A_STAGE_OF]->(r), (s)-[:STARTS_FROM]->(cs), (s)-[:FINISHED_AT]->(cf);2.3 Loading Climbs
Third, I loaded CLIMBs. CLIMBs start at km X, from an initial altitude and of course they have an average slope, a category (from 1 to 4 plus Hors Catégorie) and a distance.
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/inserpio/tour-de-france-2014/master/tour-de-france-2014-0003-climbs.csv" AS csvLine
MATCH (s:Stage { number: toInt(csvLine.STAGE_NUMBER) })
CREATE (s)-[:INCLUDES]->(c:Climb { startingAtKm: toFloat(csvLine.STARTING_AT_KM), name: csvLine.NAME, initialAltitude: toFloat(csvLine.INITIAL_ALTITUDE), averageSlope: toFloat(csvLine.AVERAGE_SLOPE), distance: toFloat(csvLine.DISTANCE), category: csvLine.CATEGORY });2.4 Loading Intermediate Sprints
Last but not least, I loaded INTERMEDIATE SPRINTs.
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/inserpio/tour-de-france-2014/master/tour-de-france-2014-0004-intermediate_sprints.csv" AS csvLine
MERGE (c:City { name: csvLine.CITY, country: csvLine.COUNTRY, lat: toFloat(csvLine.LATITUDE), lon: toFloat(csvLine.LONGITUDE) })
WITH c, csvLine MATCH (s:Stage { number: toInt(csvLine.STAGE_NUMBER) })
CREATE (s)-[:INCLUDES]->(i:IntermediateSprint { atKm: toFloat(csvLine.AT_KM) })-[:TAKES_PLACE_IN]->(c);3. Asking for some interesting questions to Neo4j
3.1 TDF 2014
match (r:Race) return r.name, r.year, r.edition, r.from, r.to, r.distance, r.number_of_stages, r.website;3.2 Which teams will take part in TDF 2014?
match (t:Team)
return t.name, t.country, t.sportingDirectors
order by t.name;3.3 How many teams per country will take part in TDF 2014?
match (t:Team) return distinct t.country, collect(t.name), count(t.name) as teamsPerCountry order by teamsPerCountry desc;3.4 How many riders per country will take part in TDF2014?
match (r:Rider) return distinct r.country, count(r.name) as ridersPerCountry order by ridersPerCountry desc;3.5 Which are the TDF 2014 stages?
match (s:Stage) return s.number, s.name, s.date, s.distance, s.type order by s.number3.6 How many stages per type exist?
match (s:Stage) return distinct s.type, count(s) order by s.type3.7 What are the min, max and avg stage distances?
match (s:Stage) return min(s.distance), avg(s.distance), max(s.distance);3.8 What are the min, max, avg stage distances by type?
match (s:Stage) return distinct s.type, min(s.distance), avg(s.distance), max(s.distance);3.9 What are the climbs per stage?
match (s:Stage)-[:INCLUDES]->(c:Climb) return s.number, s.name, s.date, s.distance, s.type, c.name, c.averageSlope, c.distance, c.category order by s.number3.10 How many kilometres will cyclist have to climb per stage?
match (s:Stage)-[:INCLUDES]->(c:Climb) return s.number, s.name, s.date, s.distance, s.type, sum(c.distance) as kmToClimb order by kmToClimb desc;3.11 What’s the hardest average slope to climb?
match (s:Stage)-[:INCLUDES]->(c:Climb) return s.number, s.name, s.date, s.distance, s.type, max(c.averageSlope);3.12 What’s the hardest average slope to climb by category?
match (c:Climb) with distinct c.category as category, max(c.averageSlope) as maxAvgSlope match (c1:Climb) where c1.category = category and c1.averageSlope = maxAvgSlope return c1.name, case when c1.category = 'H' then 'Hors Catégorie' else 'Catègorie ' + c1.category end as category, c1.averageSlope order by c1.category;Is this page helpful?