Social Networks in the Clinton Email Corpus
The Hillary Clinton email archives being released by the US Department of State are an intriguing data set for analysis. They’re too large to easily analyze by hand, but still small enough that we can process them on a laptop. Here I will review some of the basic techniques of retreiving the emails and then performing some basic queries on the social networks within. Note that we’ll only be using a subset of the data here, as the entire processed corpus is too large for a gist to handle. For additional details and scripts, check out my github: https://github.com/agussman/hrc-email.
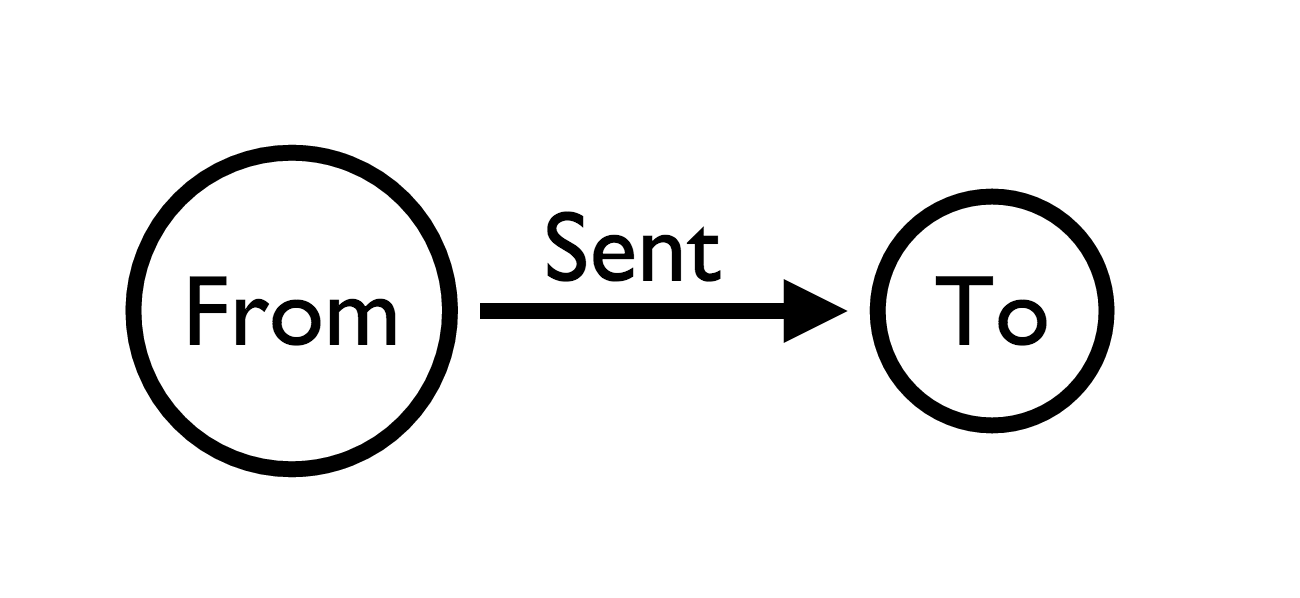
Our data model is pretty straight forward. We’re recording the address that sent the email ("From"), the destination email address ("To"), and the timestamp when the email was sent. Individual email address can both send and receive emails, so nodes will have incoming and outgoing edges.
1. Load the data set
We’ll begin by loading a subset of email occurances from the full corpus. We have the "From", "To" fields as well as the timestamp when it was sent. We’ll want to specify that each name be unique.
2. Basic Counts
How many emails were sent in this dataset?
MATCH (n)-[r]->()
RETURN type(r), count(*)How many unique email address are the dataset?
MATCH (n) RETURN COUNT(n)3. Query the Emails
Overall, what email addresses appear most frequently in the dataset?
MATCH (From)-[r]-() WITH From, COUNT(r) as c RETURN From, c ORDER BY c DESC LIMIT 10Who are sending the most emails??
MATCH (From)-[r]->() WITH From, COUNT(r) as c RETURN From.name, c ORDER BY c DESC LIMIT 10Who are receiving the most emails??
MATCH ()-[r]->(To) WITH To, COUNT(r) as c RETURN To.name, c ORDER BY c DESC LIMIT 10Note that it’s pretty obvious there are data quality issues. A lot of my effort has been spent on cleaning up the data, but a discussion of that is outside the focus of this gist. Suffice to say it is an ongoing pain in my side.
4. Network Topology
What does the local graph of popular individuals look like?
MATCH (m)-[r]->(n)
WHERE m.name IN ["h", "mills, cheryl d", "mills, cheryl d ", "abedin, huma ", "abedin, huma", "h ", "h ", "h ", "'[email protected]'", "cheryl mills"]
AND n.name IN ["h", "mills, cheryl d", "mills, cheryl d ", "abedin, huma ", "abedin, huma", "h ", "h ", "h ", "'[email protected]'", "cheryl mills"]
RETURN m, r, n;A broader view of popular actors in the network:
MATCH (n)-[r]-() WITH n, count(r) as cr ORDER BY cr DESC LIMIT 5
MATCH (m)-[r2]-() WITH m, count(r2) as cr2 ORDER BY cr2 DESC LIMIT 5
MATCH (n)-[r3]-(m) RETURN n, m, r3 LIMIT 10Is this page helpful?