GraphRAG
Introduction to GraphRAG
TL;DR
GraphRAG is an advanced RAG pattern that combines an ingestion process for extracting entities and relationships from unstructured text and further using graph algorithms for enrichment and summarization. The retrieval step then uses the knowledge graph in combination with vector search to navigate to more relevant information than just the initial text chunks.
GraphRAG refers to RAG architectures where the Retrieval part makes use of graph structures (and graph databases) to improve answer quality and explainability.
LLMs & RAG
Traditional LLMs excel in conversational behavior and generative language skills but struggle with recent, private, or low-represented information, often leading to hallucinations, due to the focused training on helpfulness instead of factuality.
RAG architectures mitigate this by grounding LLM responses in trusted, current, and private information, improving factual correctness.
While LLMs show impressive results in tasks that require language skills, they are not trustworthy when it comes to answering factual questions even more so in business critical applications that rely on the correct and secure usage of private information.
They need a powerful companion data source that can capture real-world information at high fidelity and make the context-relevant direct and indirect facts available quickly and in a transparent manner. Knowledge Graphs managed in graph databases present that "memory" (left-brain) companion to the language (right-brain) models capabilities.
GraphRAG covers a set of advanced techniques for GenAI applications that improve quality and explainability of answers and task completions. GraphRAG applies to data preparation and retrieval (the R in RAG) that involve graph (connected) data structures (and graph databases).
Basic RAG architectures rely on vector retrieval of text chunks based on the vector embedding of the user’s question. Those retrieved chunks are then presented with the question to an LLM to generate a human answer. In most cases the quality and explainability of the basic approach is not sufficient so that more advanced RAG patterns are required.

Advanced RAG Patterns
In RAG architectures there are different patterns that are applied at different phases of the process to improve quality of the answer.
Some are listed below
-
query pre-processing like query rewriting or multi-query generation
-
improved embedding generation and augmentation with metadata for vector or hybrid search
-
improved retrieval e.g. with additional filtering or re-ranking, this is also where GraphRAG comes into effect
-
retrieval result judging, eval and iterative agentic approaches
-
LLM fine-tuning for specific use-cases
-
LLM prompt tuning e.g. with additional few-shot examples
Advanced RAG Pattern Datastructures
Many advanced RAG patterns rely on connecting pieces of information to each other and using those references during retrieval for fetching additional related information. In a non-graph system that means both storing a lot of extra lookup ids and writing and maintaining the large amount of extra code to resolve those during retrieval.
In a graph system it is enough to add relationships between pieces of information and following the relationships directly or indirectly during retrieval as part of a query and using them during extraction for additional clustering and relating information. So this is the most natural operation in a graph while it is a bolted on, high effort activity in other systems.
There are a number of different techniques involved that all rely on linking relevant pieces of information in a way that they capture the real-world relationships to support answering questions by navigating this graph of knowledge.
Trust and Explainability
To reach the trust level required for critical applications besides quality explainability and transparency is key - with graph data structures and graph queries during execution, the "black box" vector only search is replaced by a detailed trace of querying and a detailed set of results that go into answering the question. The facts use for answers can also be linked to the answer and question in the graph model to be used for auditing and future improvements (e.g. re-ranking based on user feedback for this class of questions).
For answering involved questions, vector and structural graph search are combined to capture relevant clusters of information so that the LLM has all the facts (and their origins) to answer the questions. Additionally at every stage this architecture allows digging deeper and expanding the search into adjacent areas.
GraphRAG Structures
GraphRAG is based on structuring information into relevant pieces and connecting them, this allows for making these specific elements accessible and addressable and make them part of a navigation across a network of information
-
e.g. documents to chunks and chunks to each other
-
or entities to each others and their originating chunks
-
or entities to the clusters that they are part of
While documents mostly represent a vertical (and sometimes temporal) structure of a flow of segments of information, GraphRAG with entity extraction and clustering captures the horizontal re-occurrence and enhancement of topics across documents.

Implementation Techniques
GraphRAG is based on structuring information into relevant pieces and connecting them, this allows for making these specific elements accessible and addressable and make them part of a navigation across a network of information
-
e.g. documents to chunks and chunks to each other
-
or entities to each others and their originating chunks
-
or entities to the clusters that they are part of
While GraphRAG is used during the Retrieval phase it relies on graph data structures to work with during retrieval
Data Processing
That’s why the first part of GraphRAG is in the data processing i.e. building, enriching and updating a knowledge graph * this can use existing KGs and augment them * or build new KGs from scratch using structured and unstructured information
Unstructured Document Processing
Text attributes of structured data or unstructured documents are structured into chunks (can be document hierarchies). This is also referred to as the lexical graph
-
chunks are connected to each other via sequential links and to their documents
-
chunks are vector embedded and stored in an vector index
-
chunks are connected via a similarity relationships to the most similar other chunks
Entity Extraction
Entities of different types and their typed relationships are extracted from text chunks with a given graph schema (or automatic)
This is also referred to as the domain graph or entity graph
-
additional entity and relationship attributes (besides name and description) can be extracted as well
-
relationships between entities are stored in the graph
-
entity name and description are vector embedded and stored in an vector index
-
entities are de-duplicated with a variety of techniques (entity resolution, entity linking, vector similarity)
-
similarity relationships between entities capture the semantic similarity of their text embeddings
Topic clustering with graph algorithms
As extracted entities form clusters of information in the graph these clusters can be determined with graph algorithms (WCC, Louvain, Leiden) and used to aggregated larger set of entities into "topic" clusters that can both be named but also summarize entities and their relationships
-
the topic clusters are connected to their entities
-
those cluster summaries are also vector embedded and stored in an vector index
GraphRAG Retrieval
Text based retrieval (vector+graph)
This retrieval pattern combines scored vector search with structural graph search, with vector search text chunks are identified that are relevant to the question, then entities related to these chunks are extracted and from these entities relationships are followed further out (multi-hop) to find farther away, but related information
Entity based retrieval (local retrieval)
Here entities are retrieved by vector and/or full-text search based on the user’s question and then related information (text chunks, cluster summaries, claims, facts, …) is retrieved
Possible Applications
Enhanced Chatbots and Question-Answering Systems
Benefits of using GraphRAG for better summarization and retrieval of information
-
structure of the KG allows for high quality contextual information retrieved to answer questions factually and in a traceable manner
-
for each category of questions a different sub-graph of the KG is relevant (e.g. in Retail: product vs. catalog vs. shipping vs. billing vs. returning items)
-
more relevant information retrieved
-
and made available to the LLM for summarization
-
while still retaining the trail of where that information came from in high detail
Democratization of of access to information in a structured, trustworthy and explainable way, esp. useful for pre-existing knowledge graphs.
Knowledge Graph Construction and Enrichment
-
Most organizations sit on a large volume of unstructured text data, e.g. research documents, legislation, reports, patient histories, …
-
which is not accessible for processing except for full-text search
-
the GraphRAG approach allows to surface the entities (facts) and their relationships from these documents, and make them available to both natural language and structured questioning
-
documents are correlated/linked via content similarity but additionally also by shared entities that allows for better document navigation (related docs) and also (hierarchical) clustering
-
extracted entities and relationships form a knowledge graph that can be used in conjunction with or separately from the documents
-
it also surfaces topic clusters across all documents and summarizes them
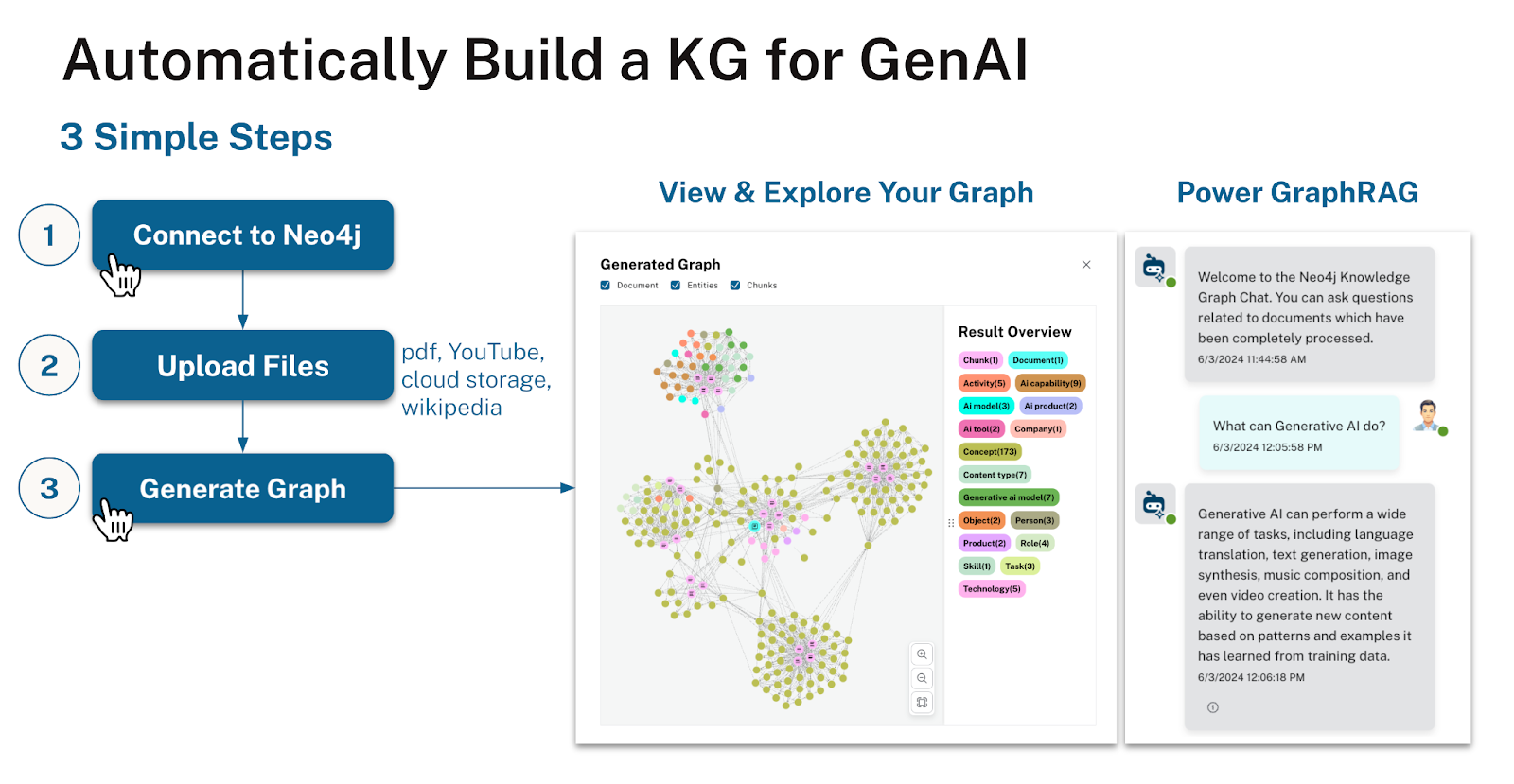
Neo4j LLM Knowledge Graph Builder
With the Neo4j LLM Knowledge Graph Builder we provide an online tool based on our open-source GenAI framework integrations, that allows you to turn your own documents into a knowledge graph and then use it for high-quality Querstion-Answering and further GraphRAG applications.