How a Neo4j semantic layer makes your Text-to-SQL agent smarter and cheaper
12 min read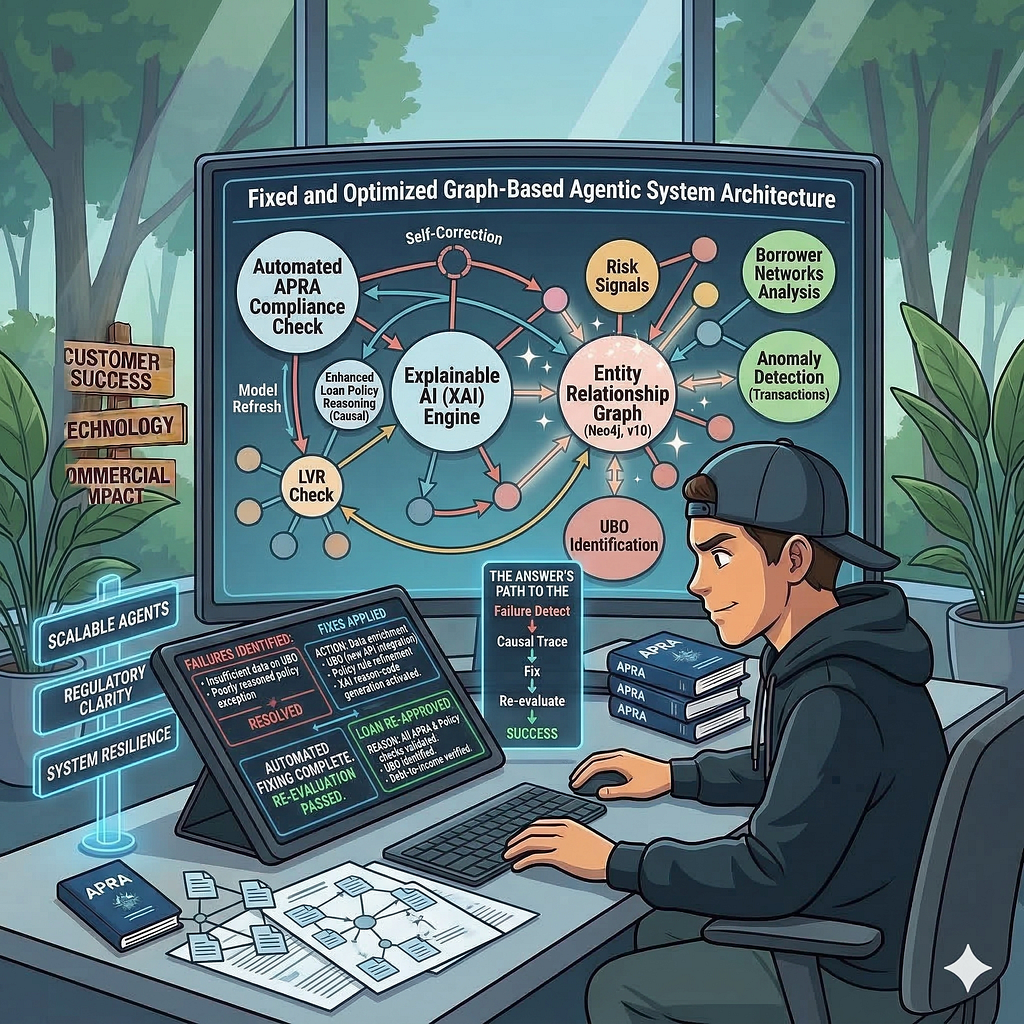
Building graph-based agentic systems: Failures, fixes, and how the answer gets there — Part 2
19 min read

Getting started with Neo4j Aura: A guide to the leading cloud graph database
3 min read