Neo4j Vector Index and Search
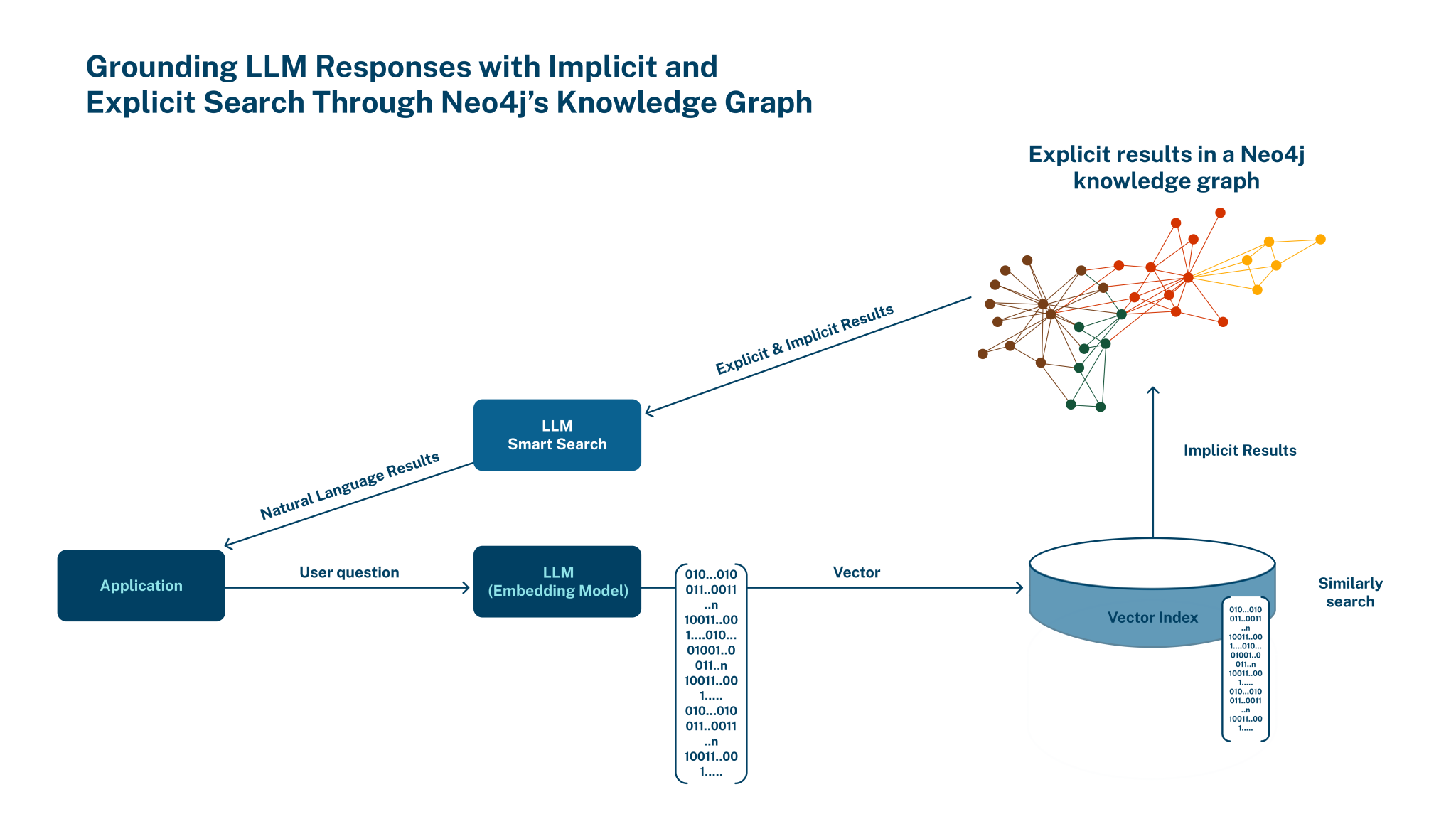
The Neo4j Vector index implements HNSW (Hierarchical Navigatable Small World) for creating layers of k-nearest neighbors to enable efficient and robust approximate nearest neighbor search. The index is designed to work with embeddings, such as those generated by machine learning models, and can be used to find similar nodes in a graph based on their embeddings.
Functionality Includes
-
Create a vector index with a specified number of dimensions and similarity function (euclidean, cosine) for both nodes and relationships
-
Query a vector index with an embedding and top-k, returning nodes and similarity score
-
Functions and procedures in the GenAI plugin to compute text embeddings with OpenAI, Azure OpenAI, Google Vertex AI, Amazon Bedrock, and other supported providers
-
Vector similarity functions to compute cosine similarity and Euclidean distance between vectors

Usage
This page covers Neo4j 5.11+.
The tabs below separate the current recommended approach using Cypher 25 from the compatibility approach for earlier Neo4j 5.x releases using Cypher 5.
For current Neo4j releases, prefer the Cypher 25 approach, using the SEARCH clause for vector search and ai.text.embed() and ai.text.embedBatch() for generating embeddings.
In both approaches, explicitly set vector.dimensions to match the embedding model you use.
This is recommended because it ensures only embeddings of the expected size are indexed and causes mismatched-dimension queries to fail clearly.
// create vector index
CREATE VECTOR INDEX `abstract-embeddings`
FOR (n:Abstract) ON (n.embedding)
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}};
// set embedding as parameter
MATCH (a:Abstract {id: $id})
CALL db.create.setNodeVectorProperty(a, 'embedding', $embedding);
// generate an embedding with the GenAI plugin
MATCH (a:Abstract {id: $id})
WITH a, ai.text.embed(a.text, "OpenAI", { token: $token, model: 'text-embedding-3-small' }) AS embedding
CALL db.create.setNodeVectorProperty(a, 'embedding', toFloatList(embedding));
// query the vector index in Cypher 25
CYPHER 25
MATCH (title:Title)<--(:Paper)-->(abstract:Abstract)
WHERE title.text CONTAINS 'hierarchical navigable small world graph'
WITH abstract.embedding AS queryVector
MATCH (similarAbstract:Abstract)
SEARCH similarAbstract IN (
VECTOR INDEX `abstract-embeddings`
FOR queryVector
LIMIT 10
)
SCORE score
MATCH (similarAbstract)<--(:Paper)-->(similarTitle:Title)
RETURN similarTitle.text AS title, score;
// use cosine similarity for exact nearest neighbor search
// pre-filter vector search
MATCH (venue:Venue)<--(paper:Paper)-->(abstract:Abstract)
WHERE venue.name CONTAINS 'NETWORK'
WITH abstract, paper,
vector.similarity.cosine(abstract.embedding, $embedding) AS score
WHERE score > 0.9
RETURN paper.title AS title, abstract.text, score
ORDER BY score DESC LIMIT 10;// create vector index
CREATE VECTOR INDEX `abstract-embeddings`
FOR (n: Abstract) ON (n.embedding)
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}};
// set embedding as parameter
MATCH (a:Abstract {id: $id})
CALL db.create.setNodeVectorProperty(a, 'embedding', $embedding);
// use the GenAI plugin to compute the embedding
MATCH (a:Abstract {id: $id})
WITH a, genai.vector.encode(a.text, "OpenAI", { token: $token }) AS embedding
CALL db.create.setNodeVectorProperty(a, 'embedding', embedding);
// query vector index for similar abstracts
MATCH (title:Title)<--(:Paper)-->(abstract:Abstract)
WHERE title.text CONTAINS 'hierarchical navigable small world graph'
CALL db.index.vector.queryNodes('abstract-embeddings', 10, abstract.embedding)
YIELD node AS similarAbstract, score
MATCH (similarAbstract)<--(:Paper)-->(similarTitle:Title)
RETURN similarTitle.text AS title, score;
// use cosine similarity for exact nearest neighbor search
// pre-filter vector search
MATCH (venue:Venue)<--(paper:Paper)-->(abstract:Abstract)
WHERE venue.name CONTAINS 'NETWORK'
WITH abstract, paper,
vector.similarity.cosine(abstract.embedding, $embedding) AS score
WHERE score > 0.9
RETURN paper.title AS title, abstract.text, score
ORDER BY score DESC LIMIT 10;