A Graph-Aware Finance Churn Prediction Model
The Challenge
Customer Churn (customer attrition) refers to the phenomenon where customers stop doing business with a company. In finance and retail banking, acquiring a new customer is significantly more expensive than retaining an existing one, making churn prediction a critical imperative.
However, financial churn presents unique challenges compared to subscription-based industries (like Netflix or Spotify):
-
Silent Churn (Dormancy): In banking, churn is often non-contractual. A customer rarely calls to say, "I am leaving." Instead, they simply stop using a card, move their direct deposit, or leave an account dormant for an extended period. Therefore, financial churn prediction is really about detecting dormancy, identifying users whose activity has dropped to a level where they are effectively gone.
-
Class Imbalance: In a healthy financial institution, the vast majority of customers (95% to 99%) are active. This extreme "Class Imbalance" makes it difficult for traditional Machine Learning models to learn what a churner looks like (finding a needle in a haystack).
-
Behavioral vs. Structural: Traditional methods (like RFM analysis) often view customers in isolation. They miss the network effects - for example, if a user’s household moves banks, or if a user stops shopping at key "sticky" merchants (like a daily commuter train), these structural changes are strong predictors of churn that tabular data often misses.
The Solution
This solution leverages Neo4j Graph Data Science (GDS) to predict customer churn by analyzing transaction patterns as a graph. Unlike traditional methods that only look at individual user demographics, this approach uses graph features to understand the relationships between users, cards, and merchants.
By identifying active users who exhibit the structural patterns of those who have previously churned, financial institutions can take proactive measures, such as targeted campaigns or personalized offers, to retain high-value customers before they become dormant.
Data Model and Network Structure
The foundation of the solution is a graph data model that captures the flow of money. The dataset includes User, Card, Merchant, and Transaction nodes.
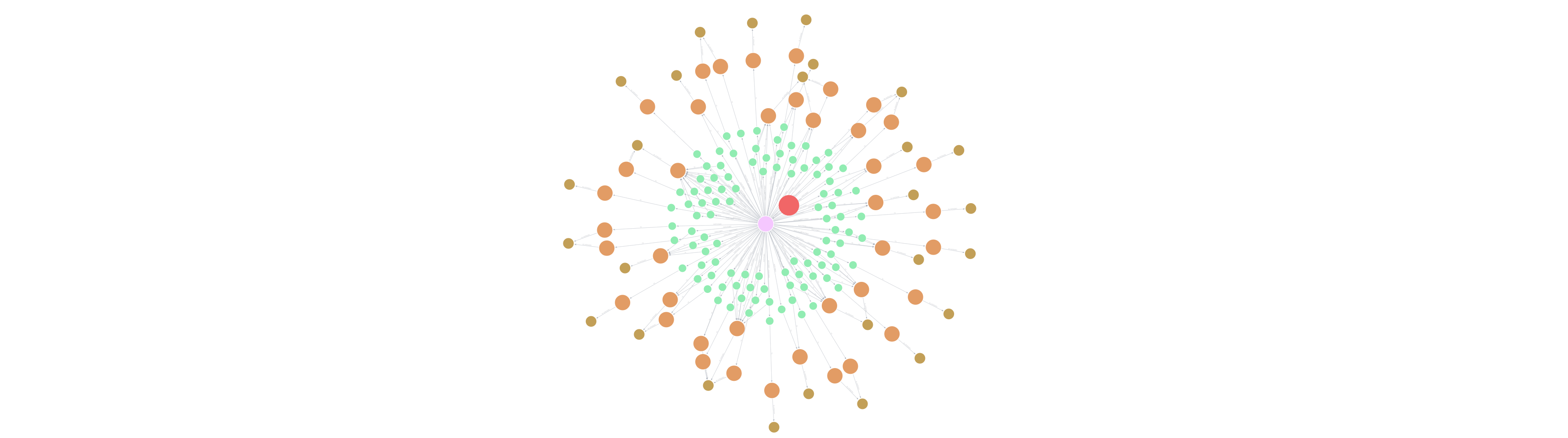
The primary relationships driving the analysis are:
-
(:User)-[:OWNS]→(:Card) -
(:Card)-[:PERFORMED]→(:Transaction) -
(:Transaction)-[:TO]→(:Merchant)
To optimize for Graph Data Science algorithms, the pipeline projects a simplified, weighted network:
(:User)-[:SHOPPED_AT {weight: count}]→(:Merchant)
This projection allows the algorithms to analyze the strength of user loyalty to specific merchants and the similarity between users based on their shared shopping habits.
Methodology: The Graph Data Science Pipeline
The solution implements a complete end-to-end pipeline entirely within Neo4j, orchestrated by the Neo4j Python Client.
1. Handling Class Imbalance
To address the scarcity of churn examples, the pipeline creates a balanced Training Cohort. It selects 100% of the historically churned users and undersamples the active users (e.g., taking only 5% of them) to create a balanced dataset. This allows the classifier to learn the specific features of churners without being overwhelmed by the majority class.
2. Graph Feature Engineering
Instead of relying solely on static demographics (Income, Debt, Credit Score), the model enriches the data with topological features calculated via GDS algorithms:
-
FastRP (Fast Random Projection): This algorithm generates 32-dimensional node embeddings for Users and Merchants. These embeddings capture the complex graph topology, effectively translating "where a user shops" and "who they shop like" into numerical vectors that the machine learning model can process. This captures latent communities of users who behave similarly.
-
PageRank & Centrality: PageRank is used to measure the influence and centrality of nodes within the transaction network. A user with high centrality in a specific merchant community might be a "trendsetter" or a "whale" whose behavior is highly indicative of broader trends.
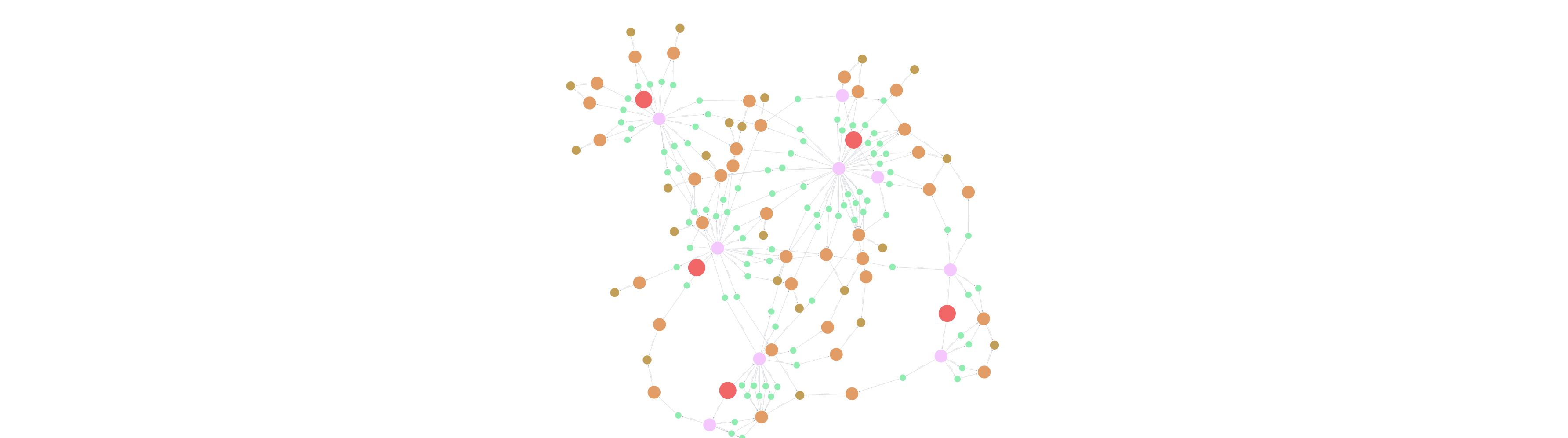
-
Geospatial & Temporal Features: The model also incorporates geospatial data (
user_latitude,user_longitude) and temporal trends (comparing transaction counts and amounts from the most recent 30 days against the previous 30 days) to detect sudden drops in activity.
3. Model Training and Inference
A Random Forest Classifier (50 trees, max depth 5) is trained using the enriched feature set.
-
Training: The model learns to distinguish between the "Churned" and "Active" labels using the balanced cohort.
-
Inference: The trained model is then applied to the Full Graph (all currently active users). It assigns a "Risk Probability" to every active user.
Visualizing Fraud and Risk Patterns
While the primary goal is churn, the graph approach also highlights potential fraud or anomalous behavior, such as "Smurfing" (structuring large transactions into smaller ones to avoid detection), which creates distinct graph patterns.
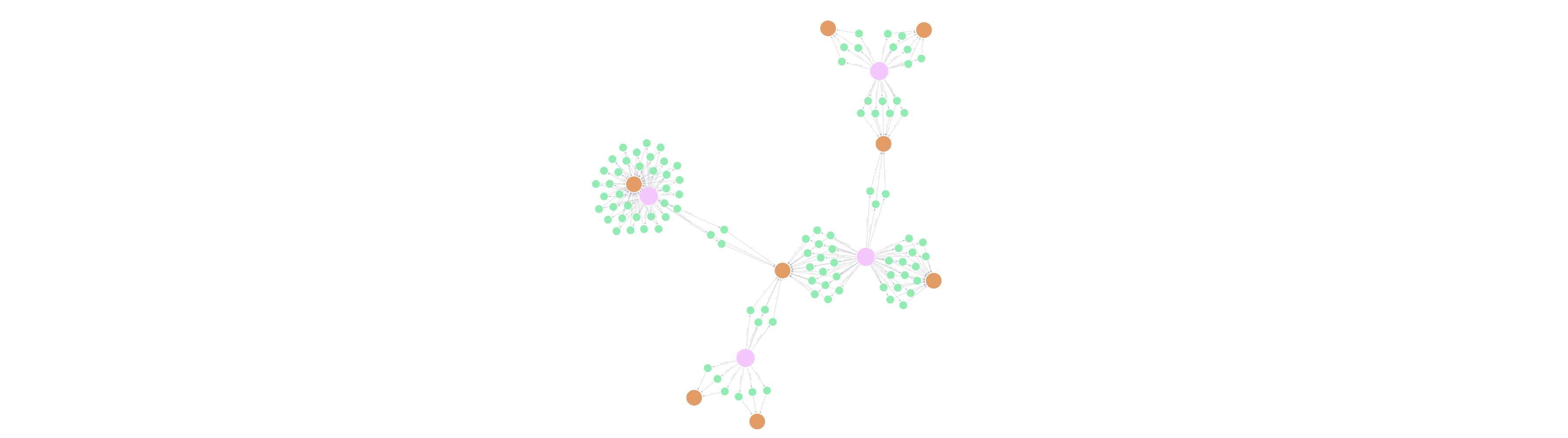
Business Benefits
-
Early Detection: Identifies "at-risk" customers who are still active but exhibiting behavioral patterns similar to those who have churned (e.g., breaking links with key merchants).
-
Holistic Customer View: Moves beyond simple "account balance" metrics to understand the structural health of the customer relationship.
-
Operational Efficiency: By running the entire pipeline (ETL, Feature Engineering, Training, and Inference) within Neo4j, data movement is minimized, allowing for more frequent re-training and real-time risk scoring.
Resources
-
Repository: pedroleitao-neo4j/finance-churn
-
Graph Data Science Library: Neo4j GDS Documentation