Using Indexes
About this module
You have learned how to define both uniqueness and existence constraints for your data. A uniqueness constraint is also an index where the default implementation is a b-tree structure. Next, you will learn about creating property and full-text schema indexes in the graph.
At the end of this module, you will be able to:
-
Describe when indexes are used in Cypher.
-
Create a single property index.
-
Create a multi-property index.
-
Create a full-text schema index.
-
Use a full-text schema index.
-
Manage indexes:
-
List indexes.
-
Drop an index.
-
Drop a full-text schema index.
-
| Because the code examples in this lesson modify the database, it is recommended that you do not execute them against your database as you will be doing so in the hands-on exercises. |
Indexes in Neo4j
The uniqueness and node key constraints that you add to a graph are essentially single-property and composite indexes respectively. Indexes are used to improve initial lookup performance, but they require additional storage in the graph to maintain and also add to the cost of creating or modifying property values that are indexed. Indexes store redundant data that points to nodes or relationships with the specific property value or values. Unlike SQL, there is no such thing as a primary key in Neo4j. You can have multiple properties on nodes that must be unique.
| Starting with Neo4j 4.3, you can create indexes on relationship properties. |
Single-property indexes are used for:
-
Equality checks
= -
Range comparisons
>,>=,<,<= -
List membership
IN -
String comparisons
STARTS WITH,ENDS WITH,CONTAINS -
Existence checks
exists() -
Spatial distance searches
distance() -
Spatial bounding searches
point()
Composite indexes are used only for equality checks and list membership.
In this course, we introduce the basics of Neo4j b-tree indexes, consult the Neo4j Operations Manual for more details about creating and maintaining indexes.
| Because index maintenance incurs additional overhead when nodes are created, Neo4j recommends that for large graphs, indexes are created after the data has been loaded into the graph. |
Indexes for range searches
When you add an index for a property of a node, it can greatly reduce the number of nodes the graph engine needs to visit in order to satisfy a query.
In this query we are testing the value of the released property of a Movie node using ranges:
MATCH (m:Movie)
WHERE 1990 < m.released < 2000
SET m.videoFormat = 'DVD'If there is an index on the released property, the graph engine will find the pointers to all nodes that satisfy the query without having to visit all of the nodes:
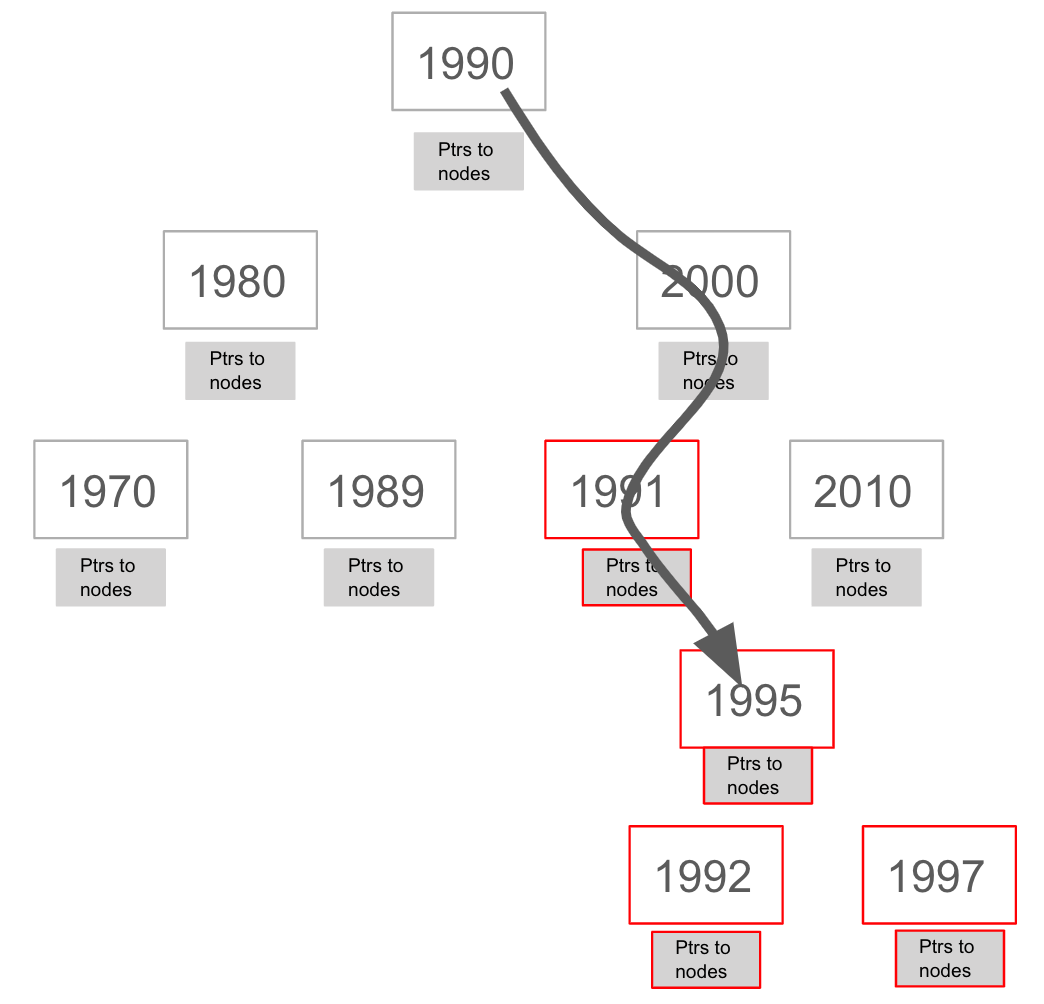
Creating a single-property index
You create an index to improve graph engine performance. A uniqueness constraint on a property is an index so you need not create an index for any properties you have created uniqueness constraints for. An index on its own does not guarantee uniqueness.
Here is an example of how we create a single-property index on the released property of all nodes of type Movie:
CREATE INDEX MovieReleased FOR (m:Movie) ON (m.released)Notice that just as for constraints, a best practice is to specify a name for the index. In this case, the name is MovieReleased.
With the result:

In Neo4j 4.3 or later, here is an example of how you would create an index on all rating properties of the REVIEWED relationships:
CREATE INDEX REVIEWED_rating
FOR ()-[r:REVIEWED]-()
ON (r.rating)Creating composite indexes
If a set of properties for a node must be unique for every node, then you create a constraint as a node key, rather than an index.
If, however, there can be duplication for a set of property values, but you want faster access to them, then you can create a composite index. A composite index is based upon multiple properties for a node.
Suppose we added the property, videoFormat to every Movie node and set its value, based upon the released date of the movie as follows:
MATCH (m:Movie)
WHERE m.released >= 2000
SET m.videoFormat = 'DVD';
MATCH (m:Movie)
WHERE m.released < 2000
SET m.videoFormat = 'VHS'With the result:

Notice that in the above Cypher statements we use the semi-colon ; to separate Cypher statements.
In general, you need not end a Cypher statement with a semi-colon. If you want to execute multiple Cypher statements, you must separate them. You have already used the semi-colon to separate Cypher statements when you loaded the Movie database in the training exercises.
|

Creating full-text schema indexes
A full-text schema index is based upon string values only, but they provide additional search capabilities that you do not get from property indexes. A full-text schema index can be used for:
-
Node or relationship properties.
-
Single property or multiple properties.
-
Single or multiple types of nodes (labels).
-
Single or multiple types of relationships.
Rather than using Cypher syntax to create a full-text schema index, you call a procedure to create the index. The index is not used implicitly when you query the graph. You must call a procedure to start a query that uses the index. By default, the underlying implementation of a full-text schema index is Lucene. You can change the underlying index provider of any index.
Example: Creating a full-text schema index
Here is an example where we create a full-text schema index on data in title property of Movie nodes and data in the name property of Person nodes:
CALL db.index.fulltext.createNodeIndex(
'MovieTitlePersonName',['Movie', 'Person'], ['title', 'name'])The result returned shows nothing exceptional:
Retrieving configured indexes
After creating a full-text schema index, you can always get of listing of all existing indexes:
CALL db.indexes()And here we see our newly-created full-text schema index:
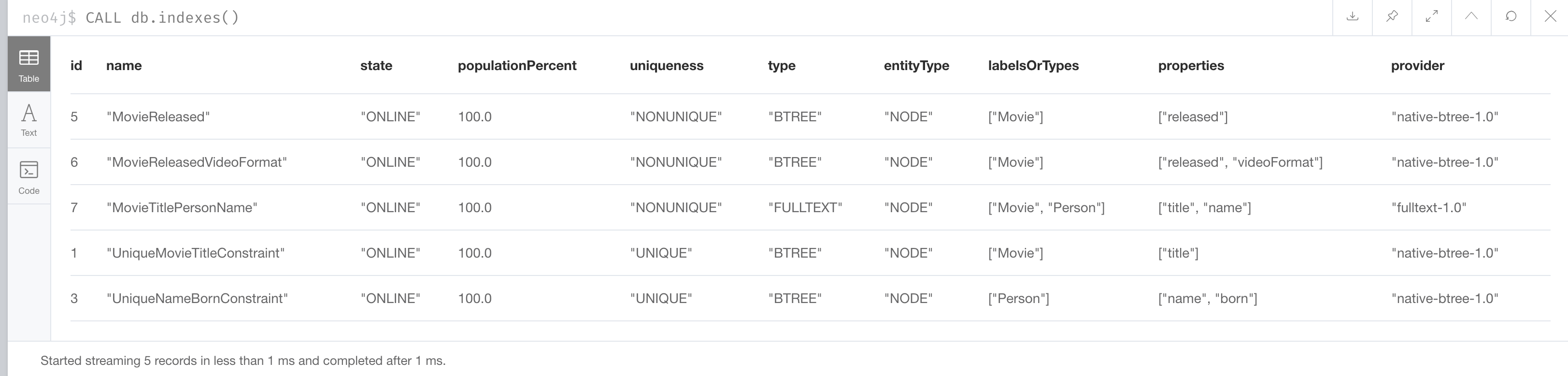
In Neo4j 4.2 and later you can use SHOW INDEXES.
|
Just as you can create a full-text schema index on properties of nodes, you can create a full-text schema index on properties of relationships.
To do this you use CALL db.index.fulltext.createRelationshipIndex().
Using a full-text schema index
To use a full-text schema index, you must call the query procedure that uses the index.
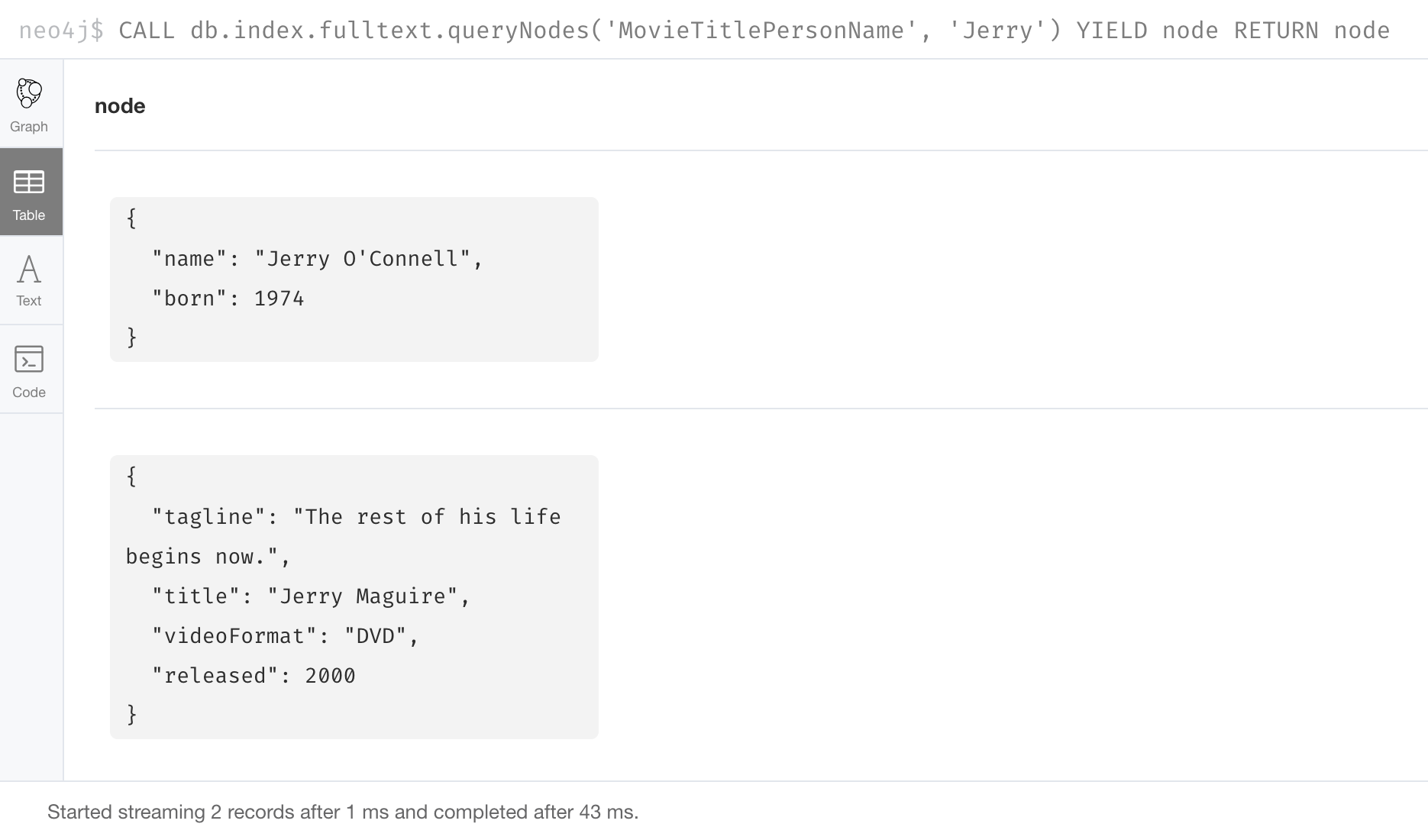
Here is an example where we want to find all movies and person names that contain the string Jerry:
CALL db.index.fulltext.queryNodes(
'MovieTitlePersonName', 'Jerry') YIELD node
RETURN nodeNotice that we specify YIELD node after calling the procedure. This enables us to access the property values in the nodes that are returned by the procedure.
In this case, we return all nodes that are found in the graph that have either a title property or name property containing the string, Jerry.
And here is the result:
Retrieving the score for a full-text search
When a full-text schema index is used, it calculates a "hit score" that represents the closeness of the values in the graph to the query string.
Here is an example:
CALL db.index.fulltext.queryNodes(
'MovieTitlePersonName', 'Matrix') YIELD node, score
RETURN node.title, scoreThe nodes returned have a Lucene score based upon how much of Matrix was part of the title:
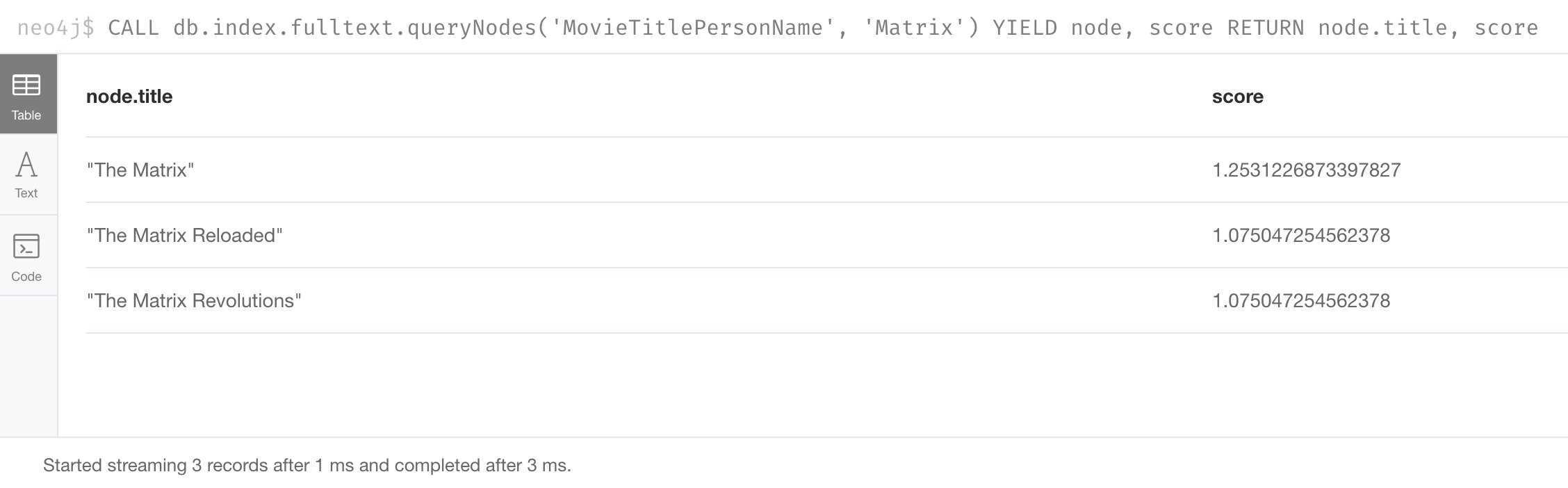
Example: Searching on a particular property
With full-text indexes created, you can also specify which property you want to search for. Here is an example where we are looking for Jerry, but only as a name property of a Person node:
CALL db.index.fulltext.queryNodes(
'MovieTitlePersonName', 'name: Jerry') YIELD node
RETURN nodeHere is what is returned:
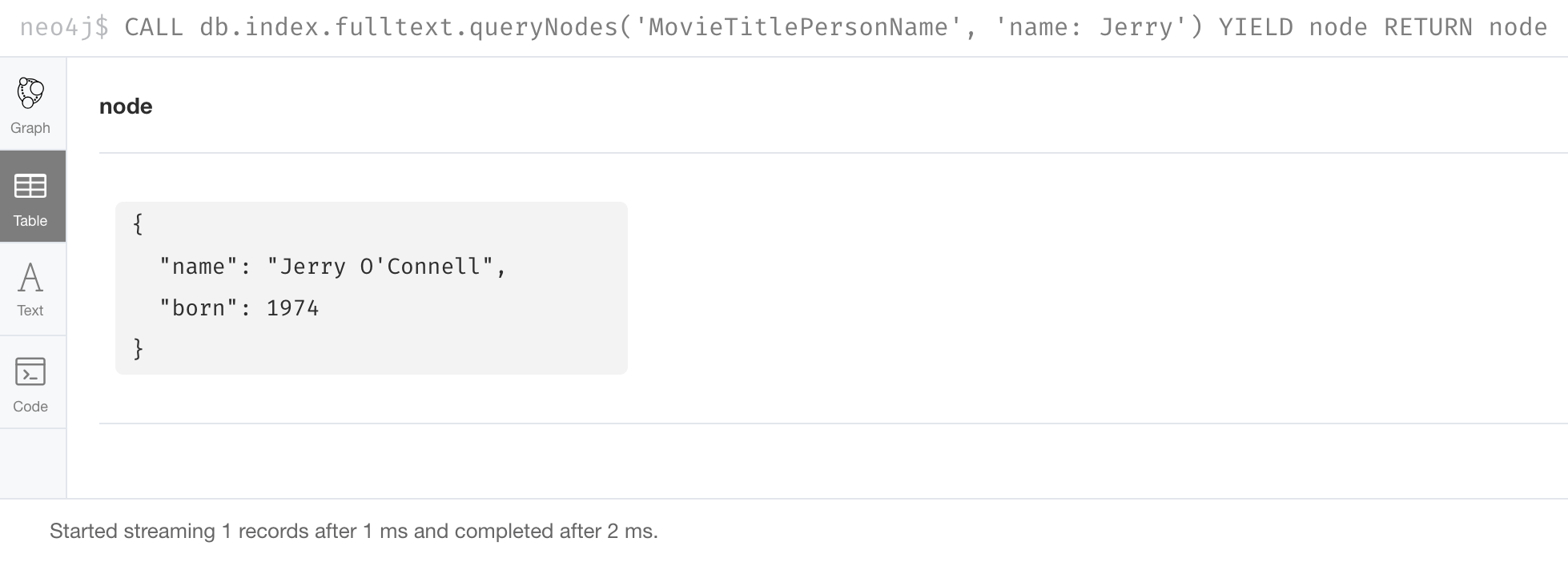
Please see the Cypher Reference Manual for more on using full-text schema indexes.
Managing Indexes
You have already seen the three types of indexes in our database thus far using this Cypher statement:
CALL db.indexes()Here is what is returned:
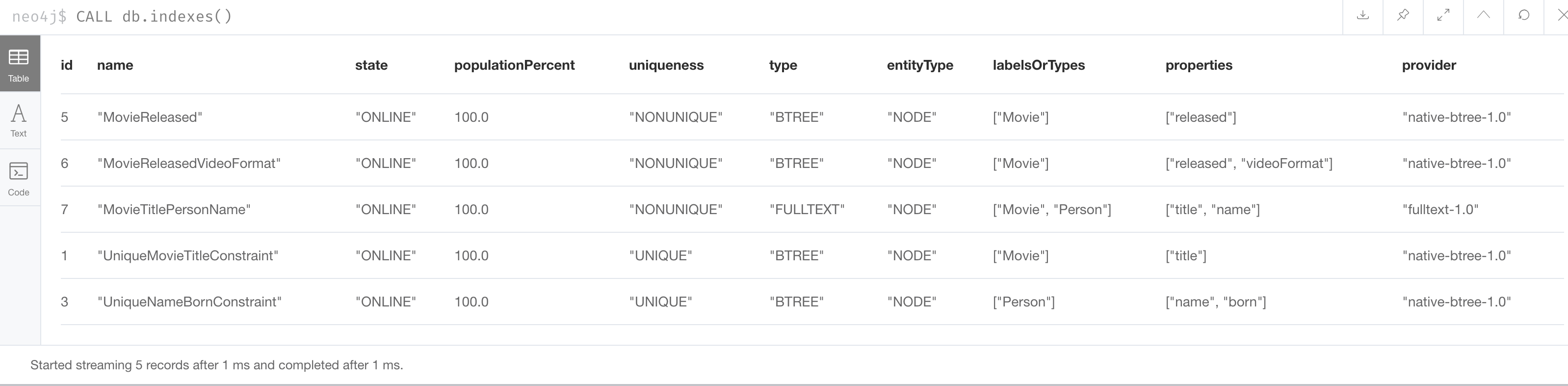
In Neo4j 4.2 and later you can use SHOW INDEXES.
|
Dropping an index
To drop an index on a property, you simply use the DROP INDEX clause, specifying the name of the index:
DROP INDEX MovieReleasedVideoFormatWith the result:

Dropping a full-text schema index
To drop a full-text schema index, you must call the procedure. Here we drop the index that we created earlier:
CALL db.index.fulltext.drop('MovieTitlePersonName')With the result:

Exercise 14: Creating indexes
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-intro-neo4j-exercises
and follow the instructions for Exercise 14.
| This exercise has 7 steps. Estimated time to complete: 30 minutes. |
Check your understanding
Question 1
What Cypher code below will create a unique index on the name property of the Person node?
Select the correct answer.
-
CREATE INDEX PersonNameIndex FOR (p:Person) ON (p.name) -
CREATE INDEX PersonNameIndex FOR (p:Person) ON (p.name) ASSERT p.name IS UNIQUE -
CREATE CONSTRAINT PersonNameConstraint ON (p:Person) ASSERT p.name IS UNIQUE -
CALL db.index.full-text.createNodeIndex('PersonName',['Person'], ['name'])
Question 2
What makes creating a full-text schema index different from creating a property index?
Select the correct answers.
-
Full-text schema indexes can use relationship properties.
-
Full-text schema indexes can check for uniqueness.
-
Full-text schema indexes can use multiple types of nodes for the index.
-
Full-text schema indexes can be used to ensure the existence of a property.
Summary
You can now:
-
Describe when indexes are used in Cypher
-
Create a single property index
-
Create a multi-property index
-
Create a full-text schema index
-
Use a full-text schema index
-
Manage indexes
-
List indexes
-
Drop an index
-
Drop a full-text schema index
-
Need help? Ask in the Neo4j Community