







Introducing the Fine-Tuned Neo4j Text2Cypher (2024) Model

Machine Learning Engineer, Neo4j
4 min read

Authors: Makbule Gulcin Ozsoy, Leila Messallem, Jon Besga

We’re excited to share one of the fine-tuned Neo4j Text2Cypher (2024) models with you. This model serves as a demonstration of how fine-tuning foundational models using the Neo4j Text2Cypher (2024) Dataset can enhance performance on Text2Cypher tasks. Please note that this is part of ongoing research and exploration aimed at highlighting the dataset’s potential rather than a production-ready solution.
The Text2Cypher task aims to translate natural language questions into Cypher queries. While foundational models can tackle this directly with the right prompts, our benchmark analysis revealed performance boosts with fine-tuning techniques. After testing several alternatives, we’re excited to share one of our fine-tuned models.
Baseline Models and Fine-Tuning
We’ve already taken a deep dive into how different fine-tuned and foundational LLM-based models perform on the Neo4j-Text2Cypher (2024) Dataset and shared the results in Benchmarking Using the Neo4j Text2Cypher (2024) Dataset.
Based on those findings and the availability of the models for fine-tuning, we selected the following baseline models for our next steps:

For fine-tuning the models, we used the training split of the Neo4j Text2Cypher (2024) Dataset. We used vendor APIs to fine-tune the closed models, and we relied on servers from RunPod and APIs from HuggingFace (HF) for the open models. We used the same prompts for fine-tuning as the ones shared previously.

Evaluation Results
For the evaluation, we followed the same procedures as outlined in our benchmark analysis. We used the test split of the Neo4j Text2Cypher (2024) Dataset, using two types of evaluation procedures:
- Translation — Textual comparison of the predicted Cypher queries with reference Cypher queries.
- Execution — After running both the predicted and reference Cypher queries on the target database, we collect the execution outputs and compare them using the same evaluation metrics as the ‘translation’ is computed.
Although we calculated results for various evaluation metrics, in this post we’re focusing on the Google BLEU score for translation-based evaluation and an ExactMatch score for execution-based evaluation.
The evaluation results for all models, including the previously benchmarked ones, are shown below. The last group in the figure highlights the fine-tuned models on the Neo4j Text2Cypher (2024) Dataset. To make comparison easier, we used red shapes to match each fine-tuned model with its baseline version.
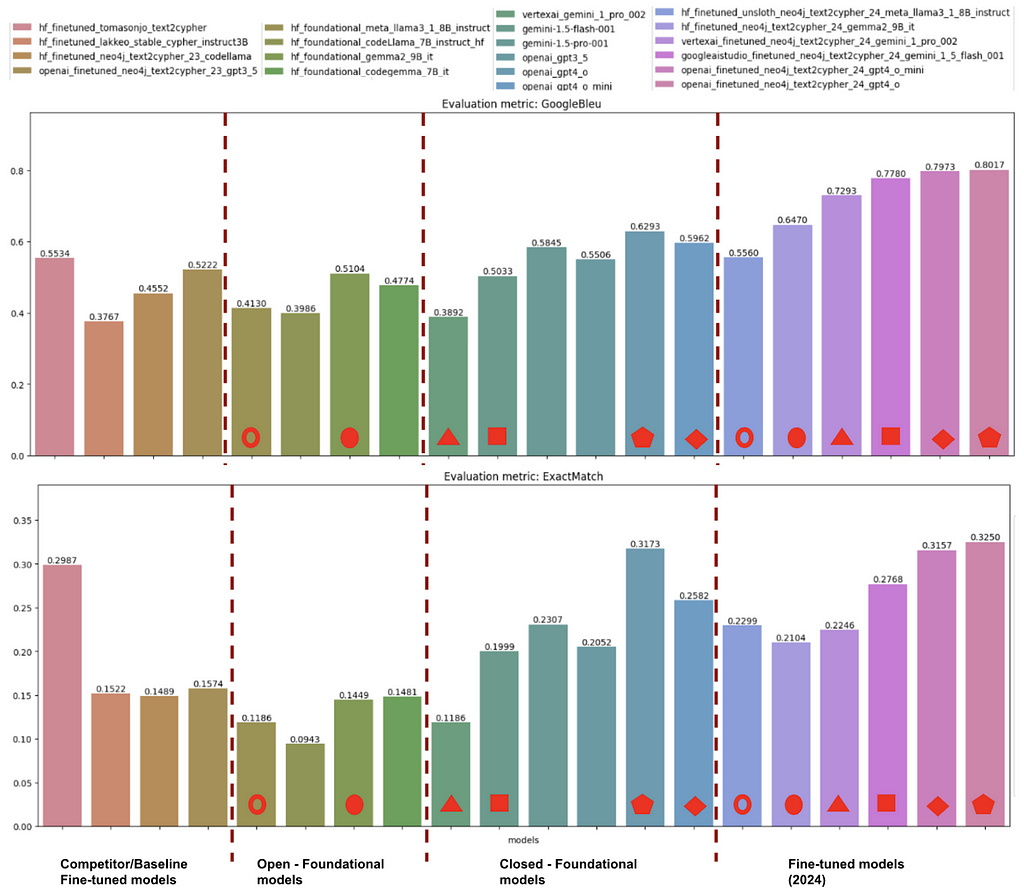
The improvements of fine-tuned models over their baselines are shown below.
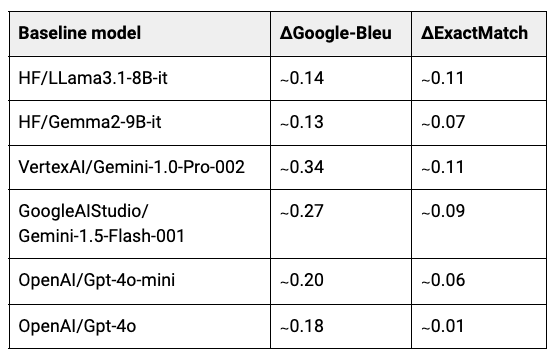
All the fine-tuned models showed improvements both in Google BLEU and ExactMatch scores. The fine-tuned models were trained without any hyperparameter tuning. With better-tuned parameters, we could potentially see even stronger results.
The best-performing fine-tuned models:
- Translation-based evaluation — Finetuned’24-OpenAI/Gpt4o, followed by Finetuned’24-OpenAI/Gpt4o-mini and Finetuned’24-GoogleAIStudio/Gemini-1.5-Flash-001
- Execution-based evaluation — Finetuned’24-OpenAI/Gpt4o and Finetuned’24-OpenAI/Gpt4o-mini, achieving more than 30 percent of match ratio.
Risks and Pitfalls of Fine-Tuning
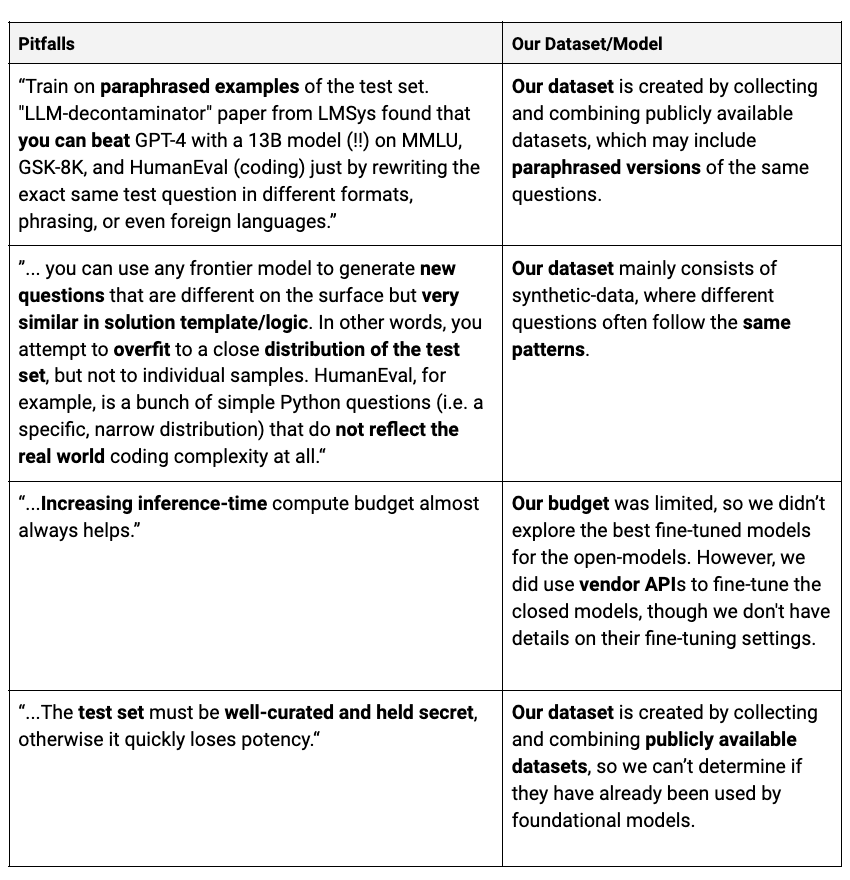
While all the fine-tuned models showed improvements, it’s important to stay mindful of the potential risks and pitfalls that come with fine-tuning.
The previous sections highlighted how fine-tuned models significantly boost performance. However, we need to be cautious about a few risks:
- In our evaluation setup, the training and test sets come from the same data distribution (sampled from a larger dataset). If the data distribution changes, the results may not follow the same pattern.
- The datasets used were gathered from publicly available sources. Over time, foundational models may access both the training and test sets, potentially achieving similar or even better results.
We might encounter some pitfalls, as discussed in Jim Fan’s LinkedIn post.
Summary
With our newly released Neo4j Text2Cypher (2024) Dataset, we’ve dived into the impact of fine-tuning models for the Text2Cypher task of transforming natural language questions to Cypher queries. And guess what? Fine-tuning really makes a difference! But we also discovered some important risks and pitfalls that can arise from the data and the fine-tuning process itself, so we’re staying alert.
Stay tuned as we dive deeper into our analysis and share fresh insights. We’re eager to explore a wide range of models, test the impact of different prompts, and uncover new findings. Have ideas or insights? Join the journey — we’d love your contributions!
In the meantime, explore the power of one of the fine-tuned Neo4j Text2Cypher (2024) models on HuggingFace.
Introducing the Fine-Tuned Neo4j Text2Cypher (2024) Model was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

