Aura graph analytics: A technical deep dive

Developer Advocate, Neo4j
14 min read
Greetings, graph lovers! If you’ve been working in Neo4j for any amount of time, then you’ve already done the hard part. You’ve built a graph. You’ve modeled the real structure of your domain in your data model. You’re writing Cypher to explore it, running pattern matches, traversing paths. You’re killing your graph game.
Did you know that you’re also sitting on way more power than you’re using? And no, I don’t mean spinning up more infrastructure or rethinking your stack. I mean right now—you could be doing more with the data you’ve already modeled.
Neo4j Aura Graph Analytics is that next layer of power. It runs the algorithms you’ve probably heard about—PageRank, node similarity, community detection, embeddings—but makes them incredibly easy to use. You don’t need to install anything, manage infrastructure, or write custom logic. It’s serverless, session-based, and fits right into your Neo4j workflow.
More in this guide:
Graph analytics basics
You’re already solving hard problems with Cypher. But a few lines of Aura Graph Analytics can get you there faster and with deeper insight. Have you ever written a query like this when you’re trying to identify the most important node in a graph?
MATCH (p:Person)<-[r:FRIEND]-() RETURN p.name, count(r) AS popularity ORDER BY popularity DESC LIMIT 10;
It’s one of the most intuitive ways to measure importance in a social graph: “Who has the most friends?” And that’s exactly what this query gives you. It counts how many incoming FRIEND relationships each person has and sorts them by that total. It’s simple, fast, and useful. But it’s also shallow. It doesn’t care who those friends are. Whether they’re central or peripheral. Whether they themselves are connected to anyone else. You’re just counting edges. You aren’t actually getting to what you really want to know, which is the identity of the most important or influential person in this social graph.
So you might find someone with 12 incoming FRIEND links who tops your list—but all 12 of those people are completely disconnected from the rest of the graph. Meanwhile, someone else is connected to just three people, but those three are hubs—they’re deeply embedded in the network. And that second person on your list? They won’t even show up in the top 10.
That’s where PageRank completely changes the picture. With Aura Graph Analytics, the code looks like this:
gds.graph.project("social-graph", “MATCH (p:Person) OPTIONAL MATCH p-[r:FRIEND]->(p2:Person) RETURN gds.graph.project.remote(source, target)”)
gds.pageRank.write("social-graph", writeProperty='pageRank')
Now, instead of just counting edges, you’re asking:
“Who is important because they’re connected to other important people?”
PageRank is recursive. It doesn’t just look at direct relationships—it looks at the structure of the whole graph. It weights each connection by how central that neighbor is, and then does it again and again, until it stabilizes into a network-wide influence score.
The output isn’t a raw count. It’s a floating-point score that reflects each person’s role in the structure. You’re not just seeing popularity—you’re seeing influence. That one-line shift—from Cypher to gds.pageRank—takes you from local patterns to global context. And the best part? If you’ve already built the graph, you can run this today.
Let’s break down the code.
Graph projections
When you run gdssession.graph.project("social-graph", “MATCH (p:Person) OPTIONAL MATCH p-[r:FRIEND]->(p2:Person) RETURN gds.graph.project.remote(source, target)”),you’re kicking off one of the most important steps in graph analytics: building a projection.
Even though your graph is already sitting in Neo4j, algorithms like PageRank don’t run directly on the database records. The graph you query with Cypher is optimized for things like flexible lookups, fast single traversals, and transactional updates, certainly not for hammering through millions of edges over and over the way graph algorithms do.
So before you can run analytics, you create a projection. A projection is a fast, lightweight, in-memory version of your graph designed purely for mathematical computation. It provides just the subset of the graph you want the algorithm to run on. The first parameter is a string, which is the name assigned to the projection. Next, you have the query call that denotes which nodes and relationships you want to be included in this subgraph. Based on our code example, you’re telling Aura Graph Analytics:
“Pull out all the
Personnodes, and all theFRIENDrelationships between them. Build me a tight, memory-optimized subgraph calledsocial-graph. Ignore everything else.”
You’re not copying your database. You’re not moving your data. You’re staging exactly what you need to analyze. This projected graph now lives in memory. It’s small, fast, isolated from the operational database, and ready for heavy lifting.
Running the algorithm
Once you have that, you can immediately run:
results = gds.pageRank.write(“social-graph”, writeProperty=”pageRank”)
Here, we use the method gds.PageRank.write to run your algorithm. The first parameter gds.pageRank is the name of the algorithm you want to run, followed by graph_name, which denotes that you want to write the output back to the nodes in the instance. The first parameter is the name of the projection you have created and staged in memory, the second is the property name that you are writing the outputs to.
PageRank doesn’t just count how many friends each person has. It recursively figures out who matters most, based on who they’re connected to and how important those connections are. And because it’s running against the in-memory projection, the computation is ridiculously fast — even if your graph has millions of nodes and billions of edges. Now, rather than a number of edges, the output gives you the float PageRank score of how influential each node is within the projection.
Let’s take a look at this in a full code example using MTA subway data.
Putting it all together
Imports
Required imports (include these at the top of your script):
from graphdatascience.session import GdsSessions, AuraAPICredentials, DbmsConnectionInfo, AlgorithmCategory
Sessions
Before you can run graph algorithms with Aura Graph Analytics in a managed session, you’ll need two sets of credentials: one for the Aura API and one for the Neo4j database itself.
Aura session management API
Aura API Credentials authenticate you to the Aura Session Management API, which allows you to create isolated, serverless graph analytics sessions programmatically.
You’ll need:
CLIENT_ID = os.getenv("AURA_CLIENT_ID")
CLIENT_SECRET = os.getenv("AURA_CLIENT_SECRET")
TENANT_ID = os.getenv("AURA_TENANT_ID")
You can get these in the Neo4j Aura Console:
- Go to console.neo4j.io and log in.
- Click your user icon (top right) → My Profile → API Keys.

- Click Create API Key.
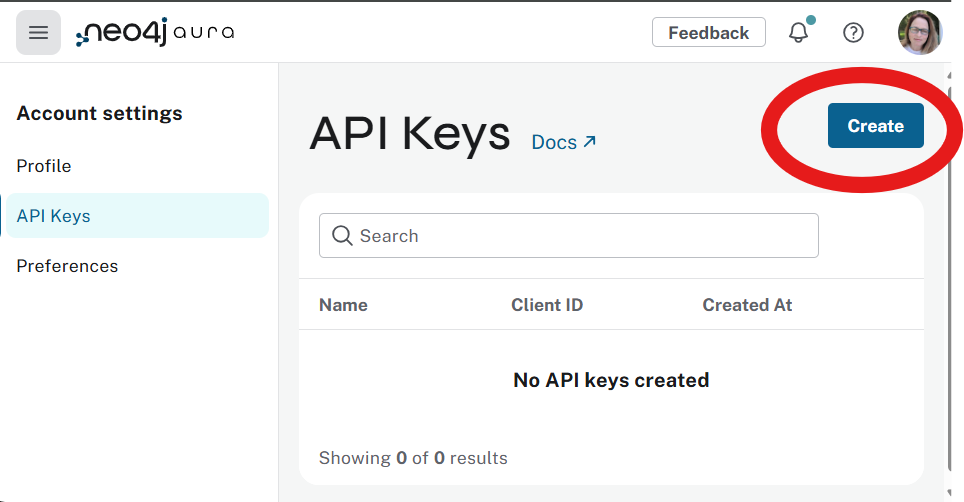
- Copy the Client ID, Client Secret, and Tenant ID.

Neo4j instance connection
When working with Aura Graph Analytics, you can either connect to a specific Neo4j database instance or use pandas dataframes as your data source. In our case, we will connect to a specific Neo4j database instance. These three variables provide everything your script needs to authenticate and talk to that database:
NEO4J_URI = os.getenv("NEO4J_URI", "neo4j+s://<your-db>.databases.neo4j.io")
NEO4J_USERNAME = os.getenv("NEO4J_USERNAME", "neo4j")
NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD")
Here’s what each one does:
NEO4J_URI: The full encrypted URI of your AuraDB instance. Theneo4j+s://protocol ensures TLS encryption—required by Aura.NEO4J_USERNAME: The database username. Defaults to “neo4j” for most Aura setups.NEO4J_PASSWORD: The password for your Neo4j database user. You set this when you created the database; you can reset it in the Aura Console.
Create a session
Next, you need to authenticate with the Aura Session Management API. That’s what this line does:
sessions = GdsSessions(api_credentials=AuraAPICredentials(CLIENT_ID, CLIENT_SECRET, TENANT_ID))
Here’s what’s happening:
GdsSessions: This is the session manager from thegraphdatasciencelibrary. It handles everything around creating, estimating, and managing isolated analytical sessions.AuraAPICredentials(...): This wraps the credentials you get from the Aura Console’s API Key section—your:CLIENT_ID,CLIENT_SECRET,TENANT_ID.
These values are used to authenticate against the Aura control plane, not the Neo4j database itself. That means this session object is what actually talks to the cloud infrastructure to spin up your analytics workspace.
This setup is required once per script or workflow, and it gives you full access to create named sessions, allocate memory, run algorithms, and clean up—all programmatically.
Estimate memory
Before launching a managed analytics session in Aura, you need to know how much memory your session will require. Neo4j makes this easy—you don’t have to guess or overprovision.
estimated_memory = sessions.estimate(
node_count=475,
relationship_count=800,
algorithm_categories=[
AlgorithmCategory.CENTRALITY,
AlgorithmCategory.COMMUNITY_DETECTION,
AlgorithmCategory.PATH_FINDING
])
Here’s what each piece does:
node_count: The number of nodes in the graph you plan to analyze.relationship_count: The number of relationships (edges) connecting them.algorithm_categories: A list of the types of graph algorithms you plan to run in the session. This helps Aura estimate how much in-memory space you’ll need.
CENTRALITYcovers things like PageRank, betweenness, etc.COMMUNITY_DETECTIONcovers things like Louvain, WCC, etc.PATH_FINDINGcovers things like Dijkstra, etc.
Here’s why this matters: Aura’s analytics engine runs in a high-performance, memory-optimized environment. This estimate ensures you provision just enough memory—keeping sessions fast, efficient, and cost-effective. The result (estimated_memory) is passed into your session creation step to allocate resources accordingly.
Important: Estimate Based on Your Projected Graph, Not the Whole Database
When using sessions.estimate(...), you’re not sizing for your entire Neo4j database—you’re sizing for the specific subgraph you’ll project into memory. Once you’ve authenticated with the Aura API and estimated the memory you need, you’re ready to create your named graph analytics session:
Create named session
db_connection_info = DbmsConnectionInfo(NEO4J_URI, NEO4J_USERNAME, NEO4J_PASSWORD) gds = sessions.get_or_create( name="mta-subway-session", db_connection_info=db_connection_info, memory=estimated_memory)
The DbmsConnectionInfo(...) defines how your session will connect to the Neo4j database that holds the graph data. It uses:
NEO4J_URI: The secure Aura connection string (e.g.,neo4j+s://...)NEO4J_USERNAME: Usually just “neo4j”NEO4J_PASSWORD: The password you set in the Aura Console
These are the credentials for the graph database, not the API.
The sessions.get_or_create(...) actually provisions the graph analytics session. It:
- Spins up a secure, ephemeral session workspace
- Attaches it to the specified Neo4j DB
- Allocates memory based on your earlier estimate
- Assigns a name to your session (“mta-subway-session”), so you can manage it, reuse it, or monitor it later
Once this runs, you’re inside a fully isolated workspace where you can project graphs, run algorithms, and analyze results—without touching the production transactional DB.
Tip: Use meaningful names for your sessions like “recommendation-sandbox” or “fraud-graph-test.” This helps track usage and manage environments across teams.
Project the graph
session.graph.project(
"subway-graph",
node_labels=["Station"],
relationship_types=["CONNECTED_TO"]
)
Run the algorithms
Now that the projection has been created, you can run the algorithm of your choice.
Run PageRank, a centrality algorithm:
gds.pageRank.write("subway-graph", writeProperty=”pageRank”)
Run Louvain, a community detection algorithm:
gds.louvain.write("subway-graph", writeProperty=”clusterID”)
Run Dijkstra’s shortest path:
gds.shortestPath.dijkstra.write("subway-graph",
sourceNode: "Washington Sq",
targetNode: "Astoria Blvd",
relationshipWeightProperty: "cost"
}
)
Drop the graph projection
gds.graph.drop("subway-graph")
This removes the in-memory graph projection you created earlier. Think of projections as temporary analytical views—optimized for algorithm performance but stored in memory.
Why drop it?
- Frees up resources inside your session
- Keeps your environment clean for the next workload
- Prevents memory overuse if you’re running multiple projections in a loop
You can keep the session open and drop projections independently if you plan to reuse the same session.
Close the session
sessions.delete(‘my-session-name’)
This shuts down your entire named session in the Aura Graph Analytics environment:
- De-allocates memory
- Releases compute resources
- Ends the audit trail for that session ID
Once closed, the session no longer appears in your active session list and cannot be reused—you’d need to create a new one.
Closing the loop
Always wrap up with:
gds.graph.drop(...)→ to clean memorygds.delete()→ to clean infrastructure
This gives you full control of your cloud analytics footprint, so you’re not leaving resources running (and racking up cost) after your analysis is done.
Graph analytics lifecycle
| Step | Code Example | What It Does |
|---|---|---|
| 1. Authenticate | GdsSessions(AuraAPICredentials(...)) | Authenticates you to the Aura Session API using your Client ID, Client Secret, and Tenant ID. |
| 2. Estimate Memory | sessions.estimate(node_count, relationship_count, algorithm_categories) | Calculates how much memory your session will need based on graph size and algorithm types. |
| 3. Connect to Neo4j DB | DbmsConnectionInfo(NEO4J_URI, NEO4J_USERNAME, NEO4J_PASSWORD) | Specifies the database your session will connect to and analyze. |
| 4. Create Session | sessions.get_or_create(name, db_connection_info, memory) | Provisions a named session with the right memory and DB connection. |
| 5. Project Graph | gds.graph.project(...) | Builds an in-memory projection of your subgraph for analytics (faster, isolated from live DB). |
| 6. Run Algorithms | gds.pageRank… gds.louvain… | Runs graph algorithms on the projected graph—returns results in milliseconds. |
| 7. Drop Projection | gds.graph.drop("subway-graph") | Frees up memory by removing the in-memory graph projection once you’re done. |
| 8. Close Session | sessions.delete() | Shuts down the session to release cloud resources and complete the lifecycle cleanly. |
With this understanding of the foundational elements, what additional use cases can be enhanced by Aura Graph Analytics?
Algorithms by use case
What’s most exciting is that the super-booster of Aura Graph Analytics can be applied to so many use cases.
| Use Case | Graph Analytics Algorithm | How Graph Algorithms Extend What Cypher Starts |
|---|---|---|
| Fraud Detection | gds.labelPropagation, gds.wcc | Cypher finds patterns you describe; Graph Analytics discovers hidden structures—emergent fraud rings you didn’t define up front. |
| Influence/Leadership Ranking | gds.pageRank, gds.betweennessCentrality | Cypher surfaces direct connections; Graph Analytics measures global influence across the full network. |
| Customer 360/Identity Resolution | gds.nodeSimilarity, gds.graphSage | Cypher matches on explicit fields; Graph Analytics finds behavioral or relational similarity—even when data is messy. |
| Supply Chain Risk Management | gds.shortestPath.dijkstra, gds.pageRank | Cypher finds shortest paths; Graph Analytics optimizes weighted paths—based on cost, delay, or risk. |
| Product Recommendations | gds.nodeSimilarity, gds.louvain | Cypher matches co-purchases; Graph Analytics uncovers latent product communities and deeper cross-sell signals. |
| IT Asset Risk Mapping | gds.betweennessCentrality, gds.minimumSpanningTree | Cypher traverses asset trees; Graph Analytics highlights chokepoints and critical dependencies based on structural risk. |
| Internal Talent Mobility (HR Graphs) | gds.pageRank, gds.scc | Cypher models reporting lines; Graph Analytics finds hidden influencers and emergent career clusters. |
| Recommendation Embeddings | gds.fastRP, gds.graphSage, gds.hashgnn | Cypher organizes product graphs; Graph Analytics turns behavior into embeddings for smarter ML recommendations. |
| Behavioral Segmentation | gds.louvain, gds.labelPropagation | Cypher clusters by attributes; Graph Analytics reveals organic communities based on real interaction patterns. |
| Entity Deduplication at Scale | gds.nodeSimilarity, gds.knn | Cypher merges on matching rules; Graph Analytics scores relational similarity without rigid rules. |
This is such a powerful moment for Neo4j users. We’ve walked through the foundations here: how to project a graph, how to run your first algorithms, how to start thinking differently about the structure you’ve already built. Now the question is: How far can you go with the power you have?
Aura Graph Analytics isn’t the destination. It’s the start of a new path, one where you can discover clusters, influences, risks, opportunities—the patterns hiding in your data that Cypher alone can’t easily surface. And if you want to go deeper (and you should), there’s a lot to explore. Learn the math behind the algorithms — PageRank, community detection, and centrality measures aren’t magic; they’re beautiful, understandable systems. Experiment with building different projections, try different scoring strategies, run what-if analyses across your graph. Keep leveling up. Graph science isn’t about syntax tricks; it’s about seeing structure others miss.
If you’re ready to take the next steps, you can start with the Aura Graph Analytics documentation or get hands-on with free GraphAcademy courses.
You’ve already done the hardest part. Now it’s time to see what’s really possible. Let’s go.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



