Implementing DRIFT search with Neo4j and LlamaIndex

Graph ML and GenAI Research, Neo4j
12 min read

Microsoft’s GraphRAG implementation was one of the first GraphRAG systems and introduced many innovative features. It combines both the indexing phase, where entities, relationships, and hierarchical communities are extracted and summarized, with advanced query-time capabilities. This approach enables the system to answer broad, thematic questions by leveraging pre-computed entity, relationship, and community summaries, going beyond the traditional document-retrieval limitations of standard RAG systems.
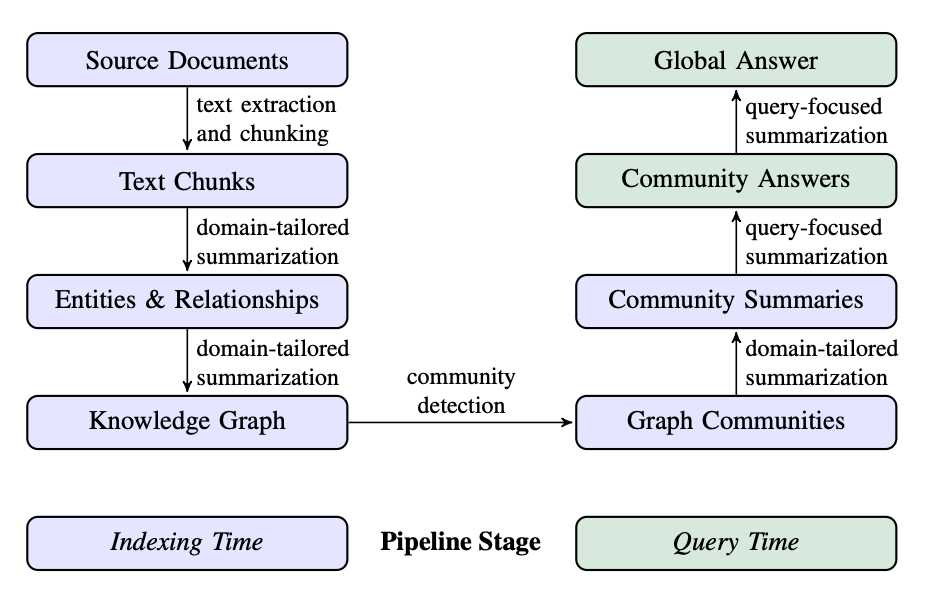
I’ve covered the indexing phase along with global and local search mechanisms in previous blog posts (here and here), so we’ll skip those details in this discussion. However, we haven’t yet explored DRIFT search, which will be the focus of this blog post. Dynamic Reasoning and Inference with Flexible Traversal (DRIFT) is a newer approach that combines characteristics of both global and local search methods. The technique begins by leveraging community information through vector search to establish a broad starting point for queries, then uses these community insights to refine the original question into detailed follow-up queries. This allows DRIFT to dynamically traverse the knowledge graph to retrieve specific information about entities, relationships, and other localized details, balancing computational efficiency with comprehensive answer quality.
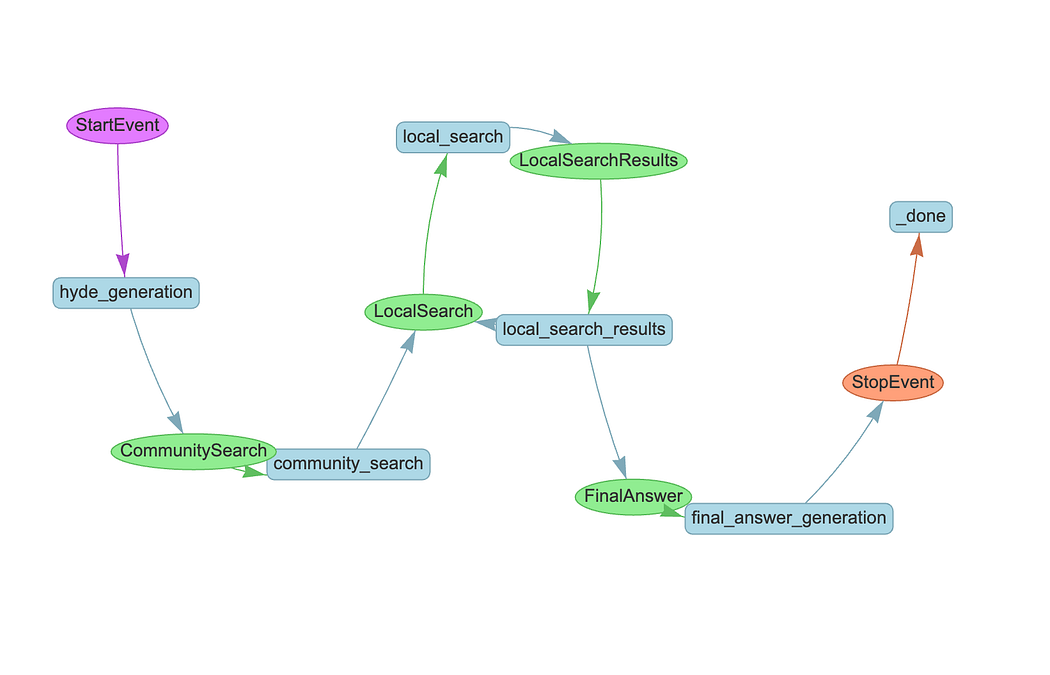
The implementation uses LlamaIndex workflows to orchestrate the DRIFT search process through several key steps. It begins with Hypothetical Document Embeddings (HyDE) generation, creating a hypothetical answer based on a sample community report to improve query representation.
The community search step then uses vector similarity to identify the most relevant community reports, providing broad context for the query. The system analyzes these results to generate an initial intermediate answer and a set of follow-up queries for deeper investigation.
These follow-up queries are executed in parallel during the local search phase, retrieving targeted information including text chunks, entities, relationships, and additional community reports from the knowledge graph. This process can iterate up to a maximum depth, with each round potentially spawning new follow-up queries.
Finally, the answer generation step synthesizes all intermediate answers collected throughout the process, combining broad community-level insights with detailed local findings to produce a comprehensive response. This approach balances breadth and depth, starting wide with community context and progressively drilling down into specifics.
This is my implementation of DRIFT search, adapted for LlamaIndex workflows and Neo4j. I reverse-engineered the approach by examining Microsoft’s GraphRAG code, so there may be some differences from the original implementation. The code is available on GitHub.
Dataset
For this blog post, we’ll use “Alice’s Adventures in Wonderland” by Lewis Carroll, a classic text that’s freely available from Project Gutenberg. This richly narrative dataset with its interconnected characters, locations, and events makes it an excellent choice for demonstrating GraphRAG’s capabilities.
Ingestion
For the ingestion process, we’ll reuse the Microsoft GraphRAG indexing implementation I developed for a previous blog post, adapted into a LlamaIndex workflow.
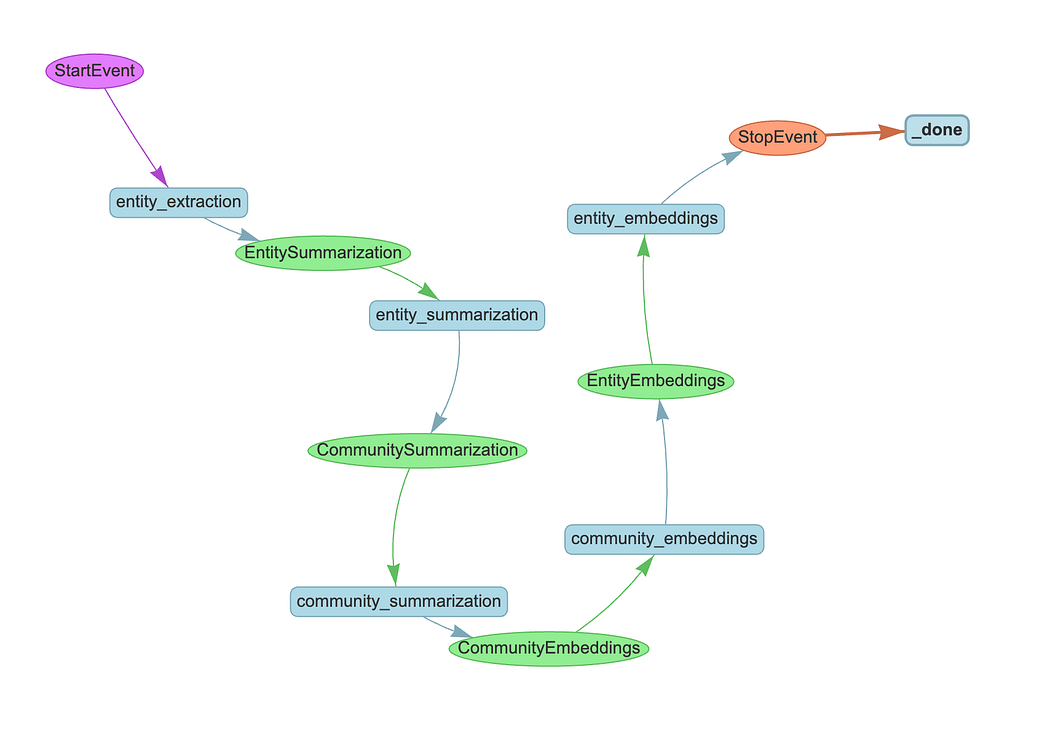
The ingestion pipeline follows the standard GraphRAG approach with three main stages:
class MSGraphRAGIngestion(Workflow):
@step
async def entity_extraction(self, ev: StartEvent) -> EntitySummarization:
chunks = splitter.split_text(ev.text)
await ms_graph.extract_nodes_and_rels(chunks, ev.allowed_entities)
return EntitySummarization()
@step
async def entity_summarization(
self, ev: EntitySummarization
) -> CommunitySummarization:
await ms_graph.summarize_nodes_and_rels()
return CommunitySummarization()
@step
async def community_summarization(
self, ev: CommunitySummarization
) -> CommunityEmbeddings:
await ms_graph.summarize_communities()
return CommunityEmbeddings()The workflow extracts entities and relationships from text chunks, generates summaries for both nodes and relationships, and creates hierarchical community summaries.
After summarization, we generate vector embeddings for both communities and entities to enable similarity search. Here’s the community embedding step:
@step
async def community_embeddings(self, ev: CommunityEmbeddings) -> EntityEmbeddings:
# Fetch all communities from the graph database
communities = ms_graph.query(
"""
MATCH (c:__Community__)
WHERE c.summary IS NOT NULL AND c.rating > $min_community_rating
RETURN coalesce(c.title, "") + " " + c.summary AS community_description, c.id AS community_id
""",
params={"min_community_rating": MIN_COMMUNITY_RATING},
)
if communities:
# Generate vector embeddings from community descriptions
response = await client.embeddings.create(
input=[c["community_description"] for c in communities],
model=TEXT_EMBEDDING_MODEL,
)
# Store embeddings in the graph and create vector index
embeds = [
{
"community_id": community["community_id"],
"embedding": embedding.embedding,
}
for community, embedding in zip(communities, response.data)
]
ms_graph.query(
"""UNWIND $data as row
MATCH (c:__Community__ {id: row.community_id})
CALL db.create.setNodeVectorProperty(c, 'embedding', row.embedding)""",
params={"data": embeds},
)
ms_graph.query(
"CREATE VECTOR INDEX community IF NOT EXISTS FOR (c:__Community__) ON c.embedding"
)
return EntityEmbeddings()The same process is applied to entity embeddings, creating the vector indices needed for DRIFT search’s similarity-based retrieval.
DRIFT search
DRIFT search is an intuitive approach to information retrieval: Start by understanding the big picture, then drill down into specifics where needed. Rather than immediately searching for exact matches at the document or entity level, DRIFT first consults community summaries, which are high-level overviews that capture the main themes and topics within the knowledge graph.
Once DRIFT identifies relevant higher-level information, it intelligently generates follow-up queries to retrieve precise information about specific entities, relationships, and source documents. This two-phase approach mirrors how humans naturally seek information: We first get oriented with a general overview, then ask targeted questions to fill in the details. By combining the comprehensive coverage of global search with the precision of local search, DRIFT achieves both breadth and depth without the computational expense of processing every community report or document.
The code is available on GitHub.
Let’s walk through each stage of the implementation.
Community search
DRIFT uses HyDE to improve vector search accuracy. Instead of embedding the user’s query directly, HyDE generates a hypothetical answer first, then uses that for similarity search. This works because hypothetical answers are semantically closer to actual community summaries than raw queries are.
@step
async def hyde_generation(self, ev: StartEvent) -> CommunitySearch:
# Fetch a random community report to use as a template for HyDE generation
random_community_report = driver.execute_query(
"""
MATCH (c:__Community__)
WHERE c.summary IS NOT NULL
RETURN coalesce(c.title, "") + " " + c.summary AS community_description""",
result_transformer_=lambda r: r.data(),
)
# Generate a hypothetical answer to improve query representation
hyde = HYDE_PROMPT.format(
query=ev.query, template=random_community_report[0]["community_description"]
)
hyde_response = await client.responses.create(
model="gpt-5-mini",
input=[{"role": "user", "content": hyde}],
reasoning={"effort": "low"},
)
return CommunitySearch(query=ev.query, hyde_query=hyde_response.output_text)Next, we embed the HyDE query and retrieve the top five most relevant community reports via vector similarity. It then prompts the LLM to generate an intermediate answer from these reports and identify follow-up queries for deeper investigation. The intermediate answer is stored, and all follow-up queries are dispatched in parallel for the local search phase.
@step
async def community_search(self, ctx: Context, ev: CommunitySearch) -> LocalSearch:
# Create embedding from the HyDE-enhanced query
embedding_response = await client.embeddings.create(
input=ev.hyde_query, model=TEXT_EMBEDDING_MODEL
)
embedding = embedding_response.data[0].embedding
# Find top 5 most relevant community reports via vector similarity
community_reports = driver.execute_query(
"""
CALL db.index.vector.queryNodes('community', 5, $embedding) YIELD node, score
RETURN 'community-' + node.id AS source_id, node.summary AS community_summary
""",
result_transformer_=lambda r: r.data(),
embedding=embedding,
)
# Generate initial answer and identify what additional info is needed
initial_prompt = DRIFT_PRIMER_PROMPT.format(
query=ev.query, community_reports=community_reports
)
initial_response = await client.responses.create(
model="gpt-5-mini",
input=[{"role": "user", "content": initial_prompt}],
reasoning={"effort": "low"},
)
response_json = json_repair.loads(initial_response.output_text)
print(f"Initial intermediate response: {response_json['intermediate_answer']}")
# Store the initial answer and prepare for parallel local searches
async with ctx.store.edit_state() as ctx_state:
ctx_state["intermediate_answers"] = [
{
"intermediate_answer": response_json["intermediate_answer"],
"score": response_json["score"],
}
]
ctx_state["local_search_num"] = len(response_json["follow_up_queries"])
# Dispatch follow-up queries to run in parallel
for local_query in response_json["follow_up_queries"]:
ctx.send_event(LocalSearch(query=ev.query, local_query=local_query))
return NoneThis establishes DRIFT’s core approach: Start broad with HyDE-enhanced community search, then drill down with targeted follow-up queries.
Local search
The local search phase executes follow-up queries in parallel to drill down into specific details. Each query retrieves targeted context through entity-based vector search, then generates an intermediate answer and potentially more follow-up queries.
@step(num_workers=5)
async def local_search(self, ev: LocalSearch) -> LocalSearchResults:
print(f"Running local query: {ev.local_query}")
# Create embedding for the local query
response = await client.embeddings.create(
input=ev.local_query, model=TEXT_EMBEDDING_MODEL
)
embedding = response.data[0].embedding
# Retrieve relevant entities and gather their associated context:
# - Text chunks where entities are mentioned
# - Community reports the entities belong to
# - Relationships between the retrieved entities
# - Entity descriptions
local_reports = driver.execute_query(
"""
CALL db.index.vector.queryNodes('entity', 5, $embedding) YIELD node, score
WITH collect(node) AS nodes
WITH
collect {
UNWIND nodes as n
MATCH (n)<-[:MENTIONS]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN {chunkText: c.text, source_id: 'chunk-' + c.id}
ORDER BY freq DESC
LIMIT 3
} AS text_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY*]->(c:__Community__)
WHERE c.summary IS NOT NULL
WITH c, c.rating as rank
RETURN {summary: c.summary, source_id: 'community-' + c.id}
ORDER BY rank DESC
LIMIT 3
} AS report_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[r:SUMMARIZED_RELATIONSHIP]-(m)
WHERE m IN nodes
RETURN {descriptionText: r.summary, source_id: 'relationship-' + n.name + '-' + m.name}
LIMIT 3
} as insideRels,
collect {
UNWIND nodes as n
RETURN {descriptionText: n.summary, source_id: 'node-' + n.name}
} as entities
RETURN {Chunks: text_mapping, Reports: report_mapping,
Relationships: insideRels,
Entities: entities} AS output
""",
result_transformer_=lambda r: r.data(),
embedding=embedding,
)
# Generate answer based on the retrieved context
local_prompt = DRIFT_LOCAL_SYSTEM_PROMPT.format(
response_type=DEFAULT_RESPONSE_TYPE,
context_data=local_reports,
global_query=ev.query,
)
local_response = await client.responses.create(
model="gpt-5-mini",
input=[{"role": "user", "content": local_prompt}],
reasoning={"effort": "low"},
)
response_json = json_repair.loads(local_response.output_text)
# Limit follow-up queries to prevent exponential growth
response_json["follow_up_queries"] = response_json["follow_up_queries"][:LOCAL_TOP_K]
return LocalSearchResults(results=response_json, query=ev.query)The next step orchestrates the iterative deepening process. It waits for all parallel searches to complete using collect_events, then decides whether to continue drilling down. If the current depth hasn’t reached the maximum (we use max depth=2), it extracts follow-up queries from all results, stores the intermediate answers, and dispatches the next round of parallel searches.
@step
async def local_search_results(
self, ctx: Context, ev: LocalSearchResults
) -> LocalSearch | FinalAnswer:
local_search_num = await ctx.store.get("local_search_num")
# Wait for all parallel searches to complete
results = ctx.collect_events(ev, [LocalSearchResults] * local_search_num)
if results is None:
return None
intermediate_results = [
{
"intermediate_answer": event.results["response"],
"score": event.results["score"],
}
for event in results
]
current_depth = await ctx.store.get("local_search_depth", default=1)
query = [ev.query for ev in results][0]
# Continue drilling down if we haven't reached max depth
if current_depth < MAX_LOCAL_SEARCH_DEPTH:
await ctx.store.set("local_search_depth", current_depth + 1)
follow_up_queries = [
query
for event in results
for query in event.results["follow_up_queries"]
]
# Store intermediate answers and dispatch next round of searches
async with ctx.store.edit_state() as ctx_state:
ctx_state["intermediate_answers"].extend(intermediate_results)
ctx_state["local_search_num"] = len(follow_up_queries)
for local_query in follow_up_queries:
ctx.send_event(LocalSearch(query=query, local_query=local_query))
return None
else:
return FinalAnswer(query=query)This creates an iterative refinement loop where each depth level builds on previous findings. Once the max depth is reached, it triggers final answer generation.
Final answer
The final step synthesizes all intermediate answers collected throughout the DRIFT search process into a comprehensive response. This includes the initial answer from community search and all answers generated during the local search iterations.
@step
async def final_answer_generation(self, ctx: Context, ev: FinalAnswer) -> StopEvent:
# Retrieve all intermediate answers collected throughout the search process
intermediate_answers = await ctx.store.get("intermediate_answers")
# Synthesize all findings into a comprehensive final response
answer_prompt = DRIFT_REDUCE_PROMPT.format(
response_type=DEFAULT_RESPONSE_TYPE,
context_data=intermediate_answers,
global_query=ev.query,
)
answer_response = await client.responses.create(
model="gpt-5-mini",
input=[
{"role": "developer", "content": answer_prompt},
{"role": "user", "content": ev.query},
],
reasoning={"effort": "low"},
)
return StopEvent(result=answer_response.output_text)Summary
DRIFT search presents an interesting strategy for balancing the breadth of global search with the precision of local search. By starting with community-level context and progressively drilling down through iterative follow-up queries, it avoids the computational overhead of processing all community reports while still maintaining comprehensive coverage.
However, there’s room for several improvements. The current implementation treats all intermediate answers equally, but filtering based on their confidence scores could improve final answer quality and reduce noise. Similarly, follow-up queries could be ranked by relevance or potential information gain before execution, ensuring the most promising leads are pursued first.
Another promising enhancement would be introducing a query refinement step that uses an LLM to analyze all generated follow-up queries, grouping similar ones to avoid redundant searches and filtering out queries unlikely to yield useful information. This could significantly reduce the number of local searches while maintaining answer quality.
The full implementation is available on GitHub for those interested in experimenting with these enhancements or adapting DRIFT for their own use cases.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



