Why AI teams are moving from prompt engineering to context engineering

Head of Product Innovation & Developer Strategy, Neo4j
19 min read

Large language models (LLMs) are text completion models; they predict the next most suitable word (token) in a sequence, which is why the more guiding an existing input sequence is, the more reliable and useful the model’s output. That existing input sequence is called model context.
Context engineering emerged in mid-2025 as the evolutionary successor to prompt engineering. It gained traction because it solved production challenges that prompting alone could not. The basic difference between the two is simple: Prompt engineering focuses on the one-time textual instructions given to an LLM, while context engineering focuses on the contextual information architecture for the ongoing interactions with the model.
Prompt engineers define tasks, provide examples, and guide models toward a particular style or output — and in the early days of LLMs, that was often enough. Most tasks were simple single-turn interactions. All the necessary information had to fit inside the single prompt.
But as soon as you tried to build something more ambitious than a chatbot, the limits of the technique became clear. Models forgot key details, used tools incorrectly, or hallucinated information.
Context engineering, by contrast, rebuilds the information assembly pipeline that feeds the model — what it should know, when it should know it, and how that information should be structured. Larger context windows can handle more information, but they don’t solve the deeper challenge of delivering the right information at the right time. And if that information is unstructured, the model struggles to identify what matters. Its attention becomes diluted and its accuracy drops— a process known as “context rot.”
Modern AI systems, especially agents that plan, observe, and act across multiple steps, need structured and bespoke context at each step to behave reliably. Knowledge graphs can supply that structure by also giving an agent a connected, explainable model of your domain and the situational awareness that complex AI applications depend on.

More in this guide:
The role and limits of prompt engineering
Prompt engineering is the practice of writing instructions that shape how an LLM interprets a task. It includes system messages to define the model’s role, user prompts that specify the task, information from data sources preloaded from a user’s question (RAG), and formatting that encourages certain types of outputs.
Early experimentation also showed that subtle changes in phrasing could improve answers, and prompt engineering proved the best tool for influencing model behavior. For tasks like summarization, email drafting, and rewriting content, it worked impressively well.
But as AI systems grew more capable and more complex, the limitations of low-context, prompt-only approaches became increasingly evident.
Where prompt engineering works
To understand where prompt engineering still excels, consider the types of tasks that remain fully self-contained. Most of the “generative” features of LLMs fall into this space: summarization, extraction, translation, and generation. If you ask an LLM to classify a sentence as a positive or negative sentiment or summarize an article, for example, you can usually rely on a single prompt plus one example. The model already knows enough from pretraining, so you don’t need retrieval, memory, or additional structure.
Prompt engineering performs reliably in scenarios such as these:
- One-shot classification where the model needs only a rule and an example
- Text generation based on general world knowledge (like summarization, translation, extraction)
- Simple chat interactions with minimal history
- Static logic tasks encoded directly in a system prompt (fixed rules that don’t depend on runtime data, memory, or multi-step reasoning)
- Generating answers to user questions that can be directly generated from retrieved back-end information
In these cases, the model either already “knows” the relevant information from its training data or can work from a single comprehensive instruction.
Where prompt engineering breaks down
As soon as your system needs to remember, retrieve, or act in multiple steps, with changing context, prompt engineering starts to feel brittle and reveals its limitations in day-to-day work.
Here’s what usually goes wrong:
- The model doesn’t have the information it needs for the next step or task, as the overall prompt is too generic.
- The prompt grows enormous and unmanageable as you try to compensate.
- The model forgets earlier details (also ones it generated) during long workflows.
- Tool use becomes unreliable because instructions get buried in noise.
If you’ve ever watched an agent lose track of its own plan or repeatedly call the wrong tool, you’ve experienced a context failure. Prompt engineering simply cannot handle dynamic, evolving task states.
The emerging gap prompt engineering cannot fill
As LLMs systems have become more capable, their complexity has grown alongside them. Instead of working with a static prompt, you’re orchestrating an evolving conversation between the model, your tools, your data, and your users. And as in human conversations, the information in focus (the context) needs to change and adjust to progress successfully.

You’re often working with agents that:
- Plan multiple steps ahead
- Execute tools and call APIs to retrieve or act
- Analyze long documents
- Follow reasoning chains
- Operate within enterprise constraints
- Need to be trustworthy and explainable
Once your system reaches this level of complexity, single prompts alone can’t provide the dynamic, structured context required to support it. To understand why, it helps to look at the specific limitations that prompt engineering cannot overcome.
1. The Model’s Capabilities Outpace Prompt Engineering
LLMs can consume massive context windows and perform sophisticated reasoning, but more space doesn’t automatically mean better performance. Transformers have a limited ability to attend to information, and when you overload the window with long, unstructured text, the model struggles to identify what matters.
This is context rot. The more you cram in, the harder it becomes for the model to find the relevant parts.

2. You Need Reliable, Current, Domain-Specific Information
Your model is trained on a static dataset. It doesn’t include your proprietary processes or the latest events happening inside your product or platform. But once you move into production, your agent doesn’t need hypothetical context; it needs the same information your operational systems rely on every day.
A real system must have access to:
- Live service states and status information
- Internal documentation that reflects how things actually work
- Customer histories and account details
- Policies and constraints that govern acceptable actions
- Explicit tool definitions, including valid inputs and outputs
- Session-specific memory that captures everything learned so far
When this information is missing, outdated, or incomplete, the model is forced to guess — and guessing leads directly to hallucinations. Most production issues stem from gaps in context, not limits in the model itself.
3. You Need Governance, Compliance, and Traceability
If you work in finance, healthcare, insurance, or security, you aren’t just trying to get a good answer. You must control:
- What the agent can see
- How it makes decisions
- What sources it uses
- Whether you can justify its output
While prompt engineering alone can’t guarantee any of these, structured context can.
4. Static Prompts Can’t Deliver Dynamic Context
Your system operates in an evolving environment where every tool call produces new data, and each step updates your understanding of the task. To stay reliable, the model must receive the smallest, most relevant slice of information at every turn, and only context engineering can deliver that.
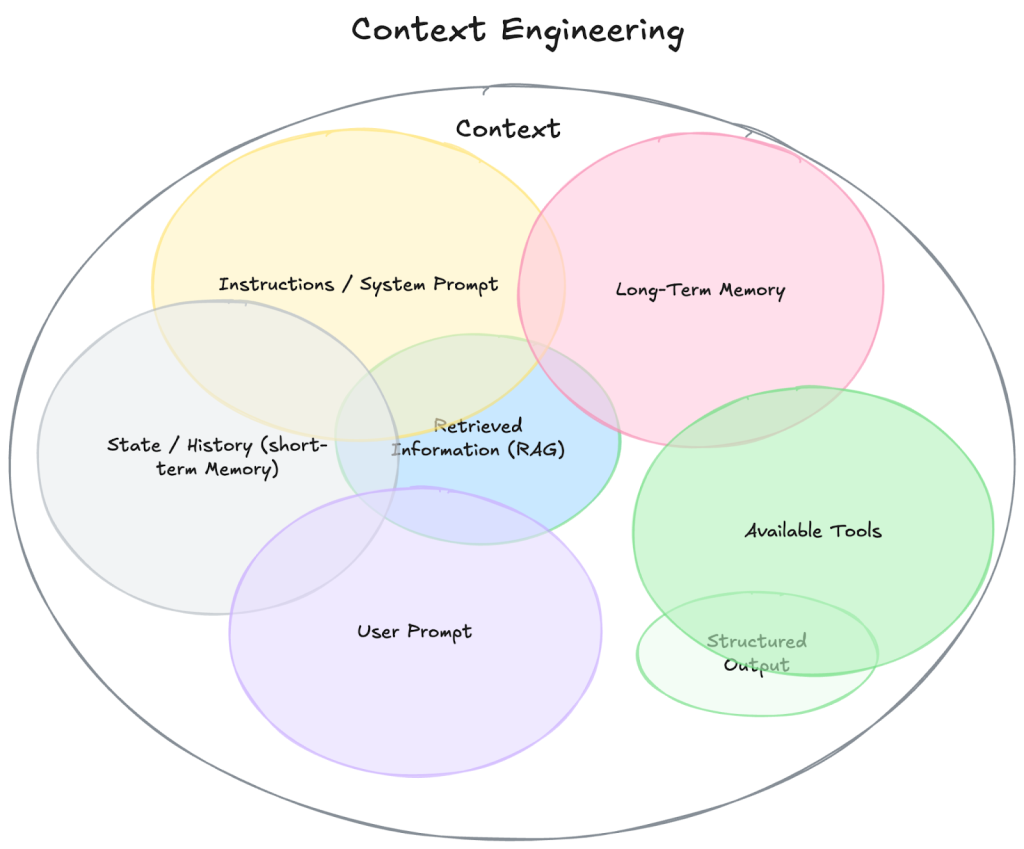
What is context engineering?
Instead of trying to push prompting beyond its limits, start shaping the world the model sees — that’s the heart of context engineering
Instead of asking, “How do I phrase this prompt?” you start asking, “What information does the model need to succeed and how do I supply that information clearly?”
Context engineering manages:
- Retrieval
- Memory
- Tool definitions
- Task state
- Policies
- Reasoning history
- Observations
- Output constraints
Prompt engineering still matters, but it’s a subset of context engineering, not a replacement for it.
The architecture behind good decisions
When you move from model-centric thinking to architecture-centric thinking, your focus changes. Rather than crafting clever wording, you concentrate on:
- What the model should know
- How to store that information
- How to retrieve it efficiently
- How to maintain consistency
- How to prevent drift over time
Context engineering is fundamental for modern agents because it gives them the information they need to understand the task, choose the right tools, and execute a multi-step plan.
When context engineering becomes necessary
To understand when you need context engineering, consider the types of tasks that push beyond what a prompt can handle:
- Long-horizon tasks where the conversation exceeds your context window
- Enterprise workflows with specific governance requirements
- Multi-agent systems that share memory
- Complex diagnostic work like incident management
- Research workflows that evolve as new information appears
- Any agent that must plan, act, and revise based on new evidence
If the problem requires the model to maintain continuity, access structured facts, or operate safely with tools, context engineering is no longer optional.
Why AI agents depend on context
An AI agent isn’t just a chatbot with a longer prompt, but rather a system that uses an LLM to reason, use tools, learn from the results, and repeat this loop until it completes a task.
For example, if you ask an agent to fix an API outage, it might:
- Analyze logs to identify patterns
- Form a hypothesis
- Call a diagnostic tool
- Observe the output
- Update its understanding
- Generate an action plan
- Execute the next step
While this loop is powerful, it only works if the agent has the right context at each step. Without it, the reasoning chain collapses.
Why prompt engineering fails for agents
To understand why prompts alone break down, consider what they can’t do:
- Store new discoveries
- Maintain continuity across long workflows
- Manage tool instructions that change over time
- Restructure context in response to new information
Prompt engineering treats context as static, but agents can only behave reliably when their context keeps pace with the decisions they make and the data they uncover.
How context engineering supports agents
Context engineering gives an agent the structural backbone it needs to remain grounded, consistent, and intelligent. To deliver that structure in practice, you need a representation of your domain the model can reliably navigate. This is where knowledge graphs become essential: They turn scattered information into organized, connected context agents can reason over.
Let’s break down the core components.
Structured information for reasoning
A structured system, like a knowledge graph, gives your agent an organized view of data in your domain. If your agent is trying to diagnose a system outage, the knowledge graph can help it see:
- Which services depend on which
- Which teams own each service
- Which components changed recently
- Which incidents followed similar patterns
This structure lets the agent perform multi-step reasoning that would be impossible with text alone.
External memory
Most tasks exceed the model’s built-in memory. You can support the agent using:
- Compaction, which summarizes earlier steps
- Structured note-taking, which stores key information outside the context window
- Persistent files that track long-term tasks
This allows the agent to remember important details without overloading the context window.
Reduced hallucinations and more grounded outputs
When your retrieval pipeline uses GraphRAG — a graph-based extension of RAG that retrieves structured, relationship-aware context — the model stays anchored to authoritative information instead of guessing. This grounding is crucial in operational environments where correctness matters.
Improved explainability
Because structured context is retrieved through explicit graph paths, you always know why the model produced a particular output. This improves safety, governance, and user trust.
Knowledge graphs as the foundation for high-quality context
Before we look at how knowledge graphs help, it’s worth revisiting how most teams deliver external information to LLMs today: retrieval-augmented generation (RAG). Traditional RAG pipelines retrieve snippets of unstructured text, usually document chunks ranked by vector similarity, and pass them into the model as context. This works well for simple lookup tasks, but it begins to break down as the complexity of your domain and reasoning requirements increases.
Limitations of unstructured RAG
Unstructured RAG treats documents as isolated chunks, which introduces several issues:
- Vector search retrieves text that looks relevant but lacks deeper meaning.
- Multi-hop questions fail because relationships aren’t encoded.
- Long-text retrieval introduces noise and context poisoning.
- Explainability is limited because embedding similarity is opaque.
- Governance is difficult because metadata and policies aren’t first-class.
In short, unstructured RAG can tell you which paragraphs sound similar, but it can’t tell you how things connect. If your use case requires multi-step reasoning, situational awareness, or compliance, you need relationships, not just text.
Benefits of knowledge graphs for RAG (GraphRAG)
Knowledge graphs solve this problem by giving your system a structured model of your domain.
They model:
- Entities, such as customers, services, products, teams
- Relationships, such as
DEPENDS_ONorOWNED_BY - Metadata, such as timestamps, owners, or sources
With this structure, GraphRAG allows your system to:
- Retrieve only the relevant slice of context
- Traverse multi-hop relationships to gather insight
- Apply policy-aware filtering at retrieval time
- Produce explainable, grounded outputs
In practice, this means your system retrieves information in a way that reflects real domain logic rather than disconnected text fragments.
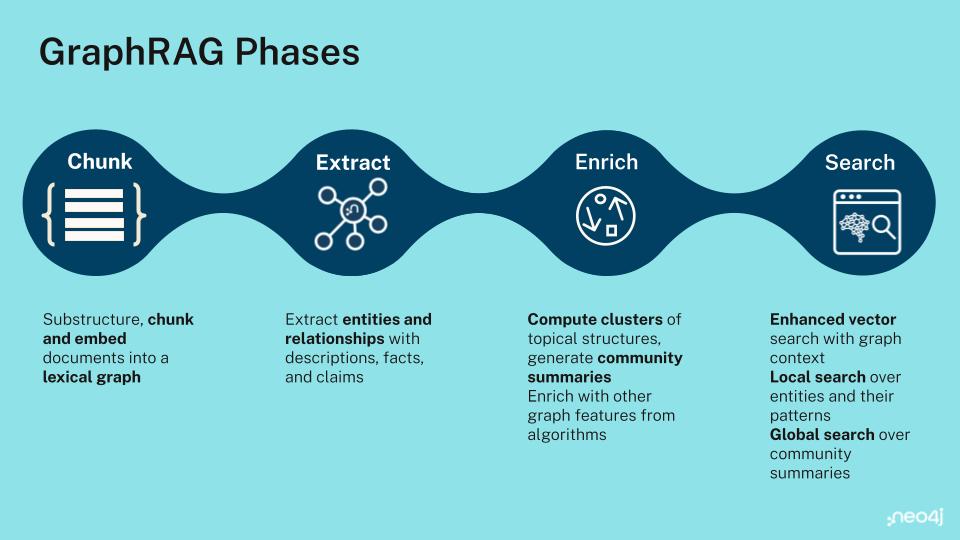
How context engineering comes to life in practice
So how do you actually build a context engineering pipeline that works in the real world? This is where graph-based context becomes especially powerful. When you begin designing context-aware systems, one of the first challenges you face is finding a place to store structured knowledge your agent can navigate and reason about.
A graph database gives you that foundation by letting you represent entities, relationships, and metadata in a way that reflects how your environment actually works. Neo4j supplies the graph model, infrastructure, and ecosystem you need to turn scattered information into a living context layer an AI system can rely on.
With that foundation in place, you can break the work into clear steps.
1. Give Your Agent a Structured, Living Memory
Instead of relying on loose collections of documents, you can model customers, services, incidents, dependencies, and teams as connected nodes and relationships. An agent can then follow these connections to understand how a failing service relates to upstream components, what changed recently, or which runbook applies.
If you want to explore how this works in practice, Neo4j AuraDB gives you an always-on graph environment without the overhead of running infrastructure yourself.
2. Retrieve Context the Same Way You Reason About It
Graph-based retrieval helps your system assemble context the way a person would. You find a relevant starting point, then expand outward through related concepts, dependencies, or policies. Tools like the GraphRAG Python library help combine vector search with graph traversal so that every piece of retrieved context is connected and meaningful.
3. Keep Your System Safe, Explainable, and Governed
When your context lives in a structured store rather than scattered documents, you can apply fine-grained access control, audit trails, and query-level filtering. That means your agent will never accidentally retrieve sensitive data it shouldn’t see. And because graph queries reveal exactly how information was retrieved, you gain a transparent decision trail that’s often required in regulated industries.
To see how governance and explainability work within a graph environment, explore the security and role-based access features built into the platform.
4. Reduce the Heavy Lifting With Tools That Speed Up Workflows
If you have unstructured documents and want to turn them into a graph, Neo4j’s LLM Knowledge Graph Builder automates the process of extracting entities and relationships and makes it easier to start building domain knowledge graphs without custom ETL. And once you have your graph, AuraDB gives you the persistent and scalable storage needed to support production agents.
This combination of structured memory, meaningful retrieval, strong governance, and a smooth developer workflow lets you shift from prompt-centered prototypes to real, scalable context-engineered systems.
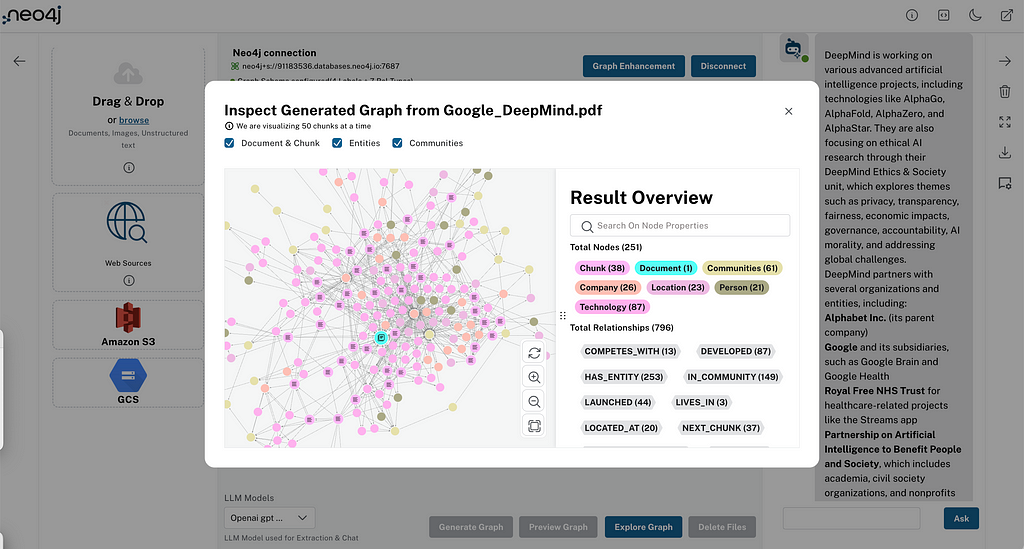
Transitioning from prompt engineering to context engineering
Think of the pivot from prompt engineering to context engineering as a mindset shift. Instead of asking how to phrase instructions, you begin asking what information the model needs in order to act correctly.
A helpful way to picture this is the context pyramid:
- The base is your persistent knowledge and policies.
- The middle is your dynamic memory and examples.
- The top is the immediate user query and tool output.
Your goal is to send the smallest, most relevant set of high-signal tokens into the context window.
Minimum viable context
Minimum viable context (MVC) ensures that your model sees exactly what it needs — no more and no less.
Here’s what belongs in an ideal invocation:
- The user’s goal
- Only the most relevant retrieved information
- Tool definitions if they’re needed for the next step
- Relevant policies
- A compacted memory summary
When any part of this is missing, you’ll see mistakes. When there’s too much, you’ll see confusion: irrelevant information that crowds the context window, reduces attention on what matters, and drives up token usage without improving accuracy.

Practical steps to adopt context engineering
Context engineering becomes real when you turn it into a reliable pipeline that delivers clean, structured, high-signal context at the moment the model needs it.
1. Identify key knowledge domains and relationships
Define the important entities and how they relate — services, incidents, teams, runbooks, and dependencies, for example.
2. Build a knowledge graph
Store this information in a graph so your agent can navigate your domain naturally.
3. Move from basic RAG to GraphRAG
Combine vector search with graph traversal to gather the right information.
4. Evaluate your retrieval pipeline
Test whether you’re delivering MVC. Look for signs of context rot, hallucinations, or missing details.
Skills for modern AI developers
AI work now requires skills that go beyond prompt engineering. You’re no longer just shaping how a model responds. You’re shaping what the model knows, how it learns new information, and how it uses that information to make decisions in real systems.
To do that well, you need a broader foundation of capabilities:
- Prompt engineering
- Graph modeling
- Retrieval and indexing
- Context orchestration
- Agent design and tool-use frameworks
These skills give you the ability to build systems that reason clearly, act with confidence, and behave consistently across long workflows.
But what does that look like in practice?
A context engineer designs the pipeline that controls what information the model sees at every step. You decide what gets retrieved, how it gets organized, and how it reaches the model in a usable format. Your work becomes the difference between an agent that stays grounded and one that drifts or hallucinates.
Here are the responsibilities you take on as a context engineer:
- Translating business domains into knowledge graphs that reflect how your world actually works
- Designing retrieval pipelines that surface the right context at the right moment
- Defining memory strategies so your system can preserve important details without overwhelming the context window
- Creating tool schemas that help the model understand how to interact with your system
- Setting policies and constraints to keep your system safe and predictable
- Monitoring context quality so the information flowing into the model remains accurate, current, and relevant
- Refining how context is assembled at runtime as your system learns and evolves
This is the work that turns a generative model into an operationally reliable AI system that prepares you to build agents that operate safely in enterprise environments.
Why context engineering defines the next era of AI systems
Prompt engineering still matters. It helps you set the right expectations and tone. But on its own, it can’t support complex reasoning or safe tool use.
Context engineering solves the deeper challenges of reliability, scalability, and governance. Knowledge graphs provide the structured backbone that gives agents situational awareness, reduces hallucination, and makes decision paths explainable.
If your goal is to build AI applications that go beyond simple interactions and behave reliably in real environments, context engineering is the path that gets you there. It gives your system the structure, grounding, and clarity it needs to perform well under pressure. Neo4j simplifies the task by giving you a graph-native foundation for modeling entities, relationships, and policies your AI can use for real reasoning.
Take a deeper dive into GraphRAG
For a practical, in-depth guide on how to design context engineering systems using knowledge graphs, Manning’s Essential GraphRAG is a helpful resource. It walks you through the process of modeling your domain, designing retrieval pipelines, and implementing context that scales.
Context engineering FAQs
Prompt engineering focuses on wording. Context engineering focuses on supplying the right knowledge for the model to work with. Prompts shape how the model thinks. Context shapes what the model actually knows. If you keep refining prompts and still get inconsistent results, it usually means the model never received the right context in the first place.
LLMs only reason over the information present in the context window. If that information is incomplete, outdated, or noisy, the model fills the gaps with guesses. When the context is structured and relevant, the model performs with far more accuracy. Strong context gives the model clear ground to stand on, which improves reasoning without requiring a higher-end model.
Prompt AI focuses on controlling responses through wording. Context AI focuses on building systems that supply the right knowledge at the right time, which results in more stable behavior.
If you want reliability, you need a system that shapes the model’s understanding, not just its phrasing.
Prompt engineering is still useful, but it’s no longer the center of AI development. Context engineering now plays that role because modern agents depend on accurate retrieval, memory, and tool use. The shift reflects a larger trend: Reliable AI comes from architecture, not clever phrasing.
A context engineer designs how information flows into the model. This includes structuring knowledge, building retrieval pipelines, creating tool schemas, defining memory strategies, enforcing rules, and refining context at runtime. Their job is to make sure the model always sees the right information in the right structure so the system behaves with confidence.
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

Share Article



Explore
Related Articles

1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers

3 of 3: The graph ecosystem: Bringing connected context to enterprise AI

Digital twins that learn: connected asset intelligence with Neo4j and Databricks

Building retail assistants customers can trust with Databricks and Neo4j