Meet Lenny’s Memory: Building context graphs for AI agents

Senior Product Manager
15 min read

Meet Lenny’s Memory: Complete memory for AI agents
AI agents are transforming how organizations work — but they have a memory problem. Ask an agent about last week’s conversation and you’ll get a blank stare. Deploy multiple agents across your organization and they can’t share what they’ve learned. When something goes wrong, there’s no audit trail explaining why the agent made that decision.
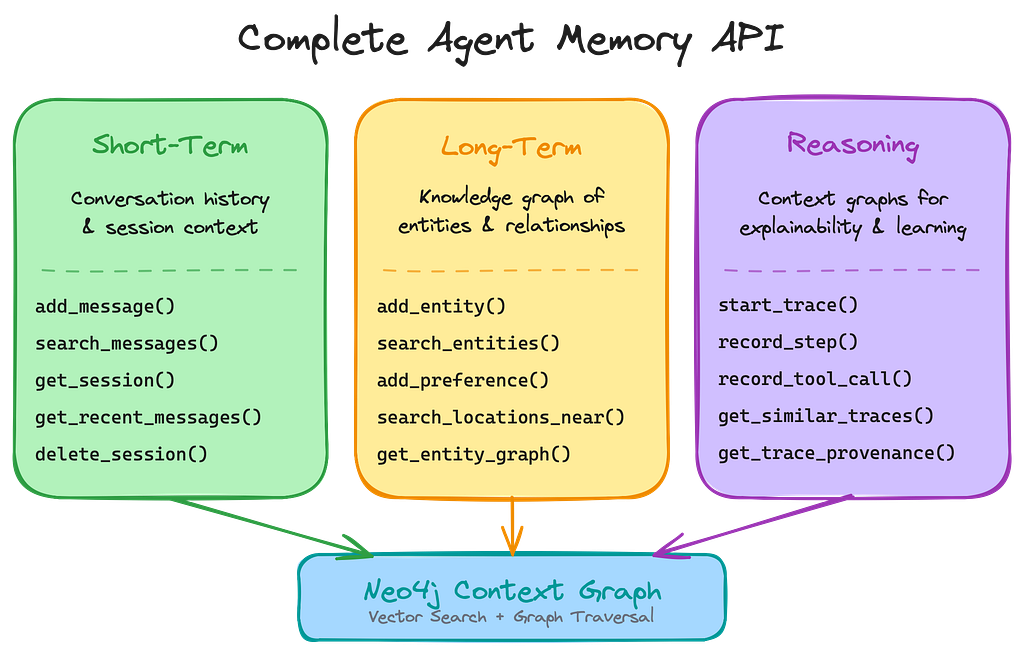
The industry recognizes that graph databases are essential for AI agent memory. Companies like Zep, Cognee, Mem0, and others have built impressive systems using Neo4j to store conversations and entity knowledge. But building effective context graphs requires three memory types working together:
- Short-term memory for conversation history and session state
- Long-term memory for entities, relationships, and learned preferences
- Reasoning memory for decision traces, tool usage audits, and provenance
Most existing implementations cover the first two — but skip reasoning memory. Without it, you can’t explain decisions, learn from experience, or debug unexpected behavior.
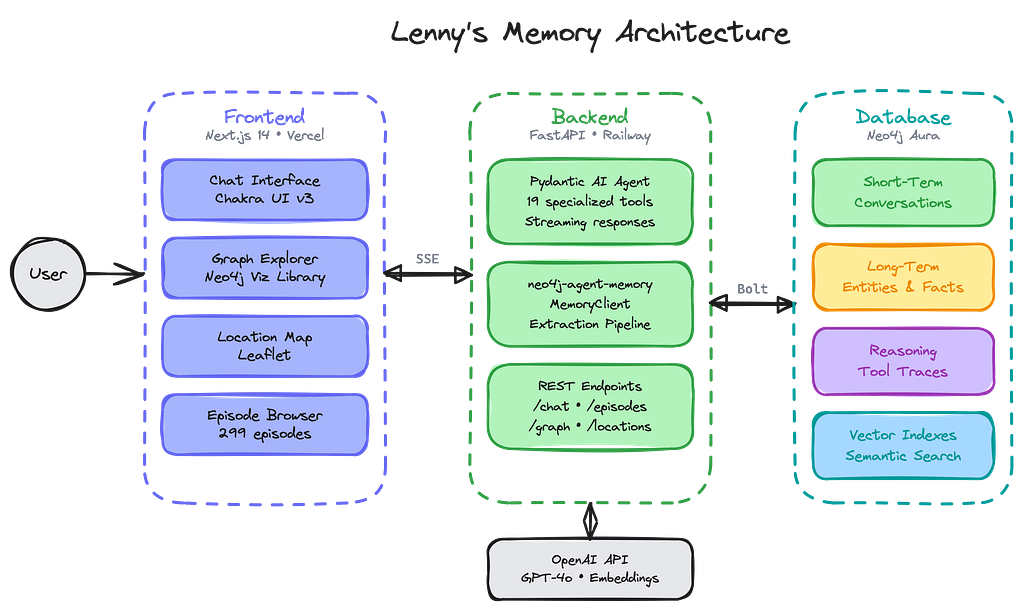
Today we’re releasing neo4j-agent-memory, a Neo4j Labs project that provides all three memory types. Drawing from best practices we’ve developed working directly with customers building AI agents in production, it’s an open-source Python library that integrates with modern agent frameworks — LangChain, Pydantic AI, LlamaIndex, OpenAI Agents, CrewAI, etc — and stores your entire context graph in Neo4j.
See it in action: Lenny’s memory
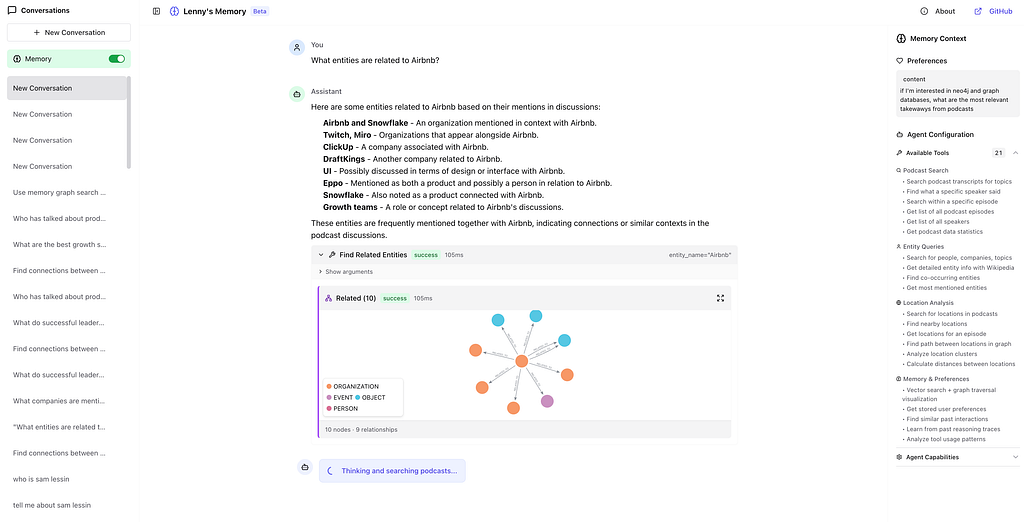
To demonstrate the project with a concrete example, we built Lenny’s Memory, a demo app that loads 300+ podcast episodes from the popular Lenny’s Podcast and lets you explore them through an AI agent with complete memory.
We loaded the episodes into neo4j-agent-memory, extracting guests, companies, topics, locations, and their relationships. Then we built a chat agent with Pydantic AI, with 19 specialized tools that uses all three memory types.
Ask about people and their ideas:
“What has Brian Chesky said about hiring?”
The agent searches across every episode where Brian Chesky appeared, finds his quotes about hiring, and synthesizes an answer — with episode references so you can dig deeper.
Explore connections:
“Which guests have talked about both product-market fit and pricing?”
This isn’t just keyword search. The agent traverses a knowledge graph of entities (people, companies, concepts) and their relationships to find meaningful intersections.
Get personalized recommendations:
“Based on what I’ve asked about, which episodes should I listen to next?”
The agent remembers your conversation history and learned preferences, using them to tailor recommendations.
See the knowledge graph:
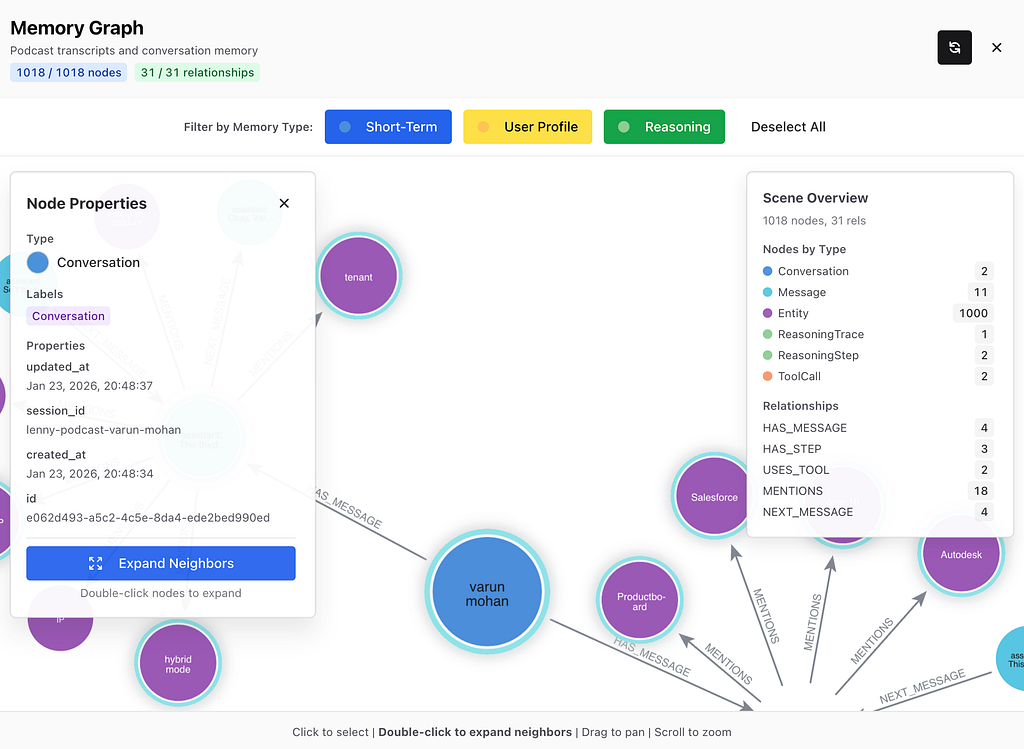
An interactive visualization lets you explore how guests, companies, and topics connect. Double-click nodes to expand relationships. Filter by entity type. View Wikipedia-enriched cards for context.
Three types of memory for your context Graph
Context graphs need all three memory types to be complete. Most existing solutions cover the first two — but skip reasoning memory, which is essential for explainability and learning from experience.
Short-term memory: What just happened
Every message in your conversation is stored with its context — who said it, when, what came before. This lets the agent maintain coherent multi-turn conversations and reference earlier parts of your chat.
# The agent stores each message as you chat
await memory.short_term.add_message(
session_id="user-123",
role="user",
content="What did Brian Chesky say about culture?",
metadata={"source": "chat"}
)
# And can search across your conversation history
results = await memory.short_term.search_messages(
"startup culture",
session_id="user-123",
limit=10
)
In Lenny’s Memory, this powers the conversational flow — the agent knows what you asked two messages ago and can build on it.
Long-term memory: What the agent knows
This is where things get interesting. Long-term memory extracts and stores a knowledge graph of entities and their relationships. Every guest, company, topic, and location mentioned in the podcast becomes a node. Relationships connect them: Brian Chesky FOUNDED Airbnb. Airbnb is LOCATED_IN San Francisco. Brian DISCUSSED “hiring” in Episode 45.
# Entities are automatically typed using the POLE+O model
# (Person, Organization, Location, Event, Object)
entity, dedup = await memory.long_term.add_entity(
name="Brian Chesky",
type="PERSON",
description="Co-founder and CEO of Airbnb"
)
# Geospatial queries find locations within a radius
nearby = await memory.long_term.search_locations_near(
latitude=37.7749,
longitude=-122.4194,
radius_km=50
)
Reasoning memory: The missing piece
This is what most memory implementations lack. Every time the agent reasons through a problem — planning steps, calling tools, evaluating results — that trace is recorded. The next time it faces a similar task, it can reference what worked.
from neo4j_agent_memory import StreamingTraceRecorder
# Record the agent's reasoning process
async with StreamingTraceRecorder(
memory.reasoning,
session_id="user-123",
task="Find episodes about pricing strategy"
) as recorder:
step = await recorder.start_step(
thought="I should search for pricing-related content",
action="search_episodes"
)
await recorder.record_tool_call(
tool_name="search_episodes",
arguments={"query": "pricing strategy"},
result=[{"title": "Ep 45: Pricing Your Product"}],
status=ToolCallStatus.SUCCESS,
duration_ms=145
)
# Later: find similar successful reasoning
similar = await memory.reasoning.get_similar_traces(
task="Find episodes about monetization",
success_only=True
)
In Lenny’s Memory, before answering each question, the agent checks if it’s solved something similar before. If it found a good approach for “pricing strategy” questions, it can reuse that pattern for “monetization” questions.
Why reasoning memory enables explainability
Reasoning memory does more than help agents learn — it makes AI decision-making transparent and auditable.
Every reasoning trace captures the full chain:
- which message triggered the task,
- what the agent thought,
- which tools it called (with arguments and results), and
- whether the approach succeeded.
This structure enables powerful queries:
// Find the reasoning behind a specific answer
MATCH (m:Message {content: "What did Brian say about hiring?"})
-[:TRIGGERED]->(t:ReasoningTrace)
-[:HAS_STEP]->(s:ReasoningStep)
-[:USED_TOOL]->(tc:ToolCall)
RETURN s.thought, tc.tool_name, tc.arguments, tc.result
// Audit which data sources influenced a decision
MATCH (t:ReasoningTrace)-[:HAS_STEP]->()-[:USED_TOOL]->(tc:ToolCall)
WHERE t.task CONTAINS "recommendation"
RETURN tc.tool_name, count(*) AS usage, avg(tc.duration_ms) AS avg_latency
Data provenance is built in. When the agent makes a claim, you can trace it back through the reasoning steps to the specific tool calls and data sources that informed it. This matters for regulated industries, debugging unexpected behavior, and building user trust.
Explainability becomes queryable. Instead of treating the agent as a black box, you can ask: “Why did you recommend this episode?” and get a concrete answer — not a post-hoc rationalization, but the actual reasoning trace that led to the decision.
Reasoning memory also enables continuous improvement. By analyzing patterns in successful vs. failed traces, you can identify which tools work best for which tasks, where the agent struggles, and how to optimize prompts or tool designs.
The entity extraction pipeline
Loading the podcast episodes means extracting thousands of entities — guests, companies, concepts, locations. Doing this with LLM calls alone would be slow and expensive.
So we built a multi-stage pipeline:
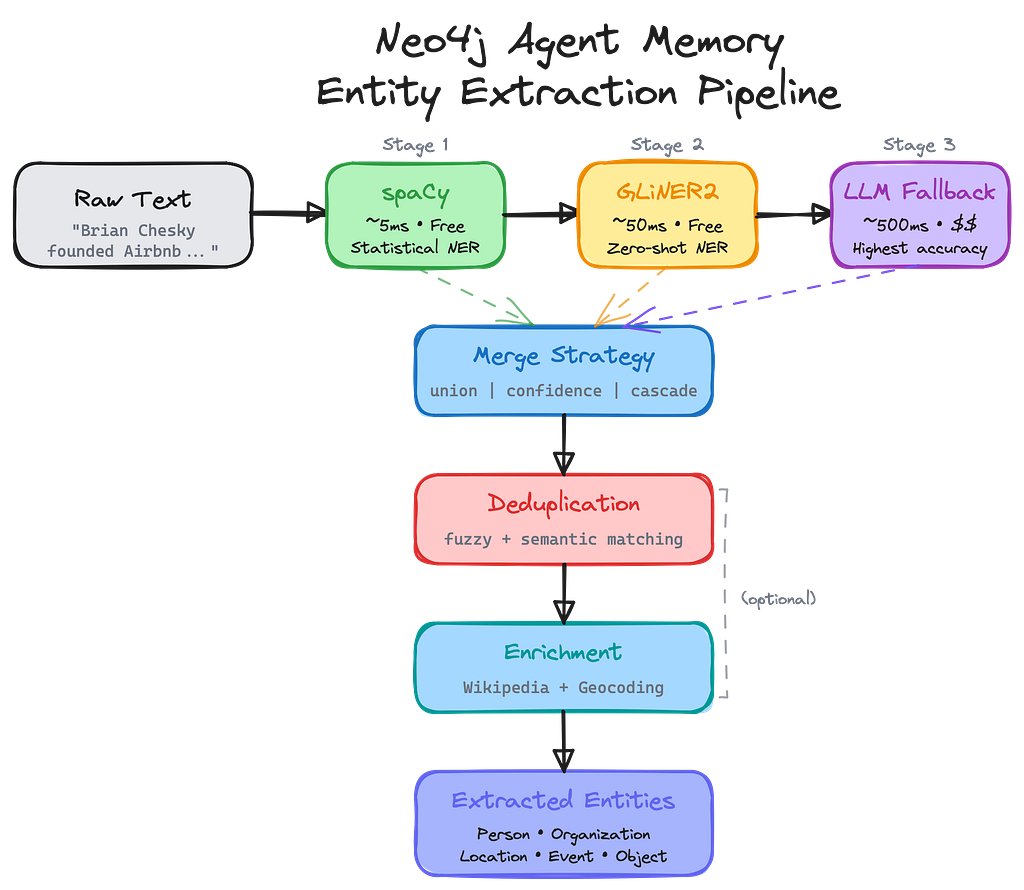
- spaCy (~5ms, free): Fast statistical NER catches common entities
- GLiNER2 (~50ms, free): Zero-shot NER with domain-specific schemas
- LLM fallback (gpt-4o-mini) (~500ms, cost): Highest accuracy for complex cases
The pipeline also handles deduplication (is “Brian” the same as “Brian Chesky”?), relationship extraction, and optional Wikipedia enrichment.
from neo4j_agent_memory.extraction import ExtractorBuilder
extractor = (
ExtractorBuilder()
.with_spacy(model="en_core_web_sm")
.with_gliner_schema("podcast", threshold=0.5) # 8 domain schemas available
.with_llm_fallback(model="gpt-4o-mini")
.with_merge_strategy("confidence")
.build()
)
result = await extractor.extract(
"Brian Chesky founded Airbnb in San Francisco in 2008"
)
# Extracts: Person(Brian Chesky), Organization(Airbnb),
# Location(San Francisco), Event(founding, 2008)
The graph schema
Here’s how the three memory types connect in Neo4j:
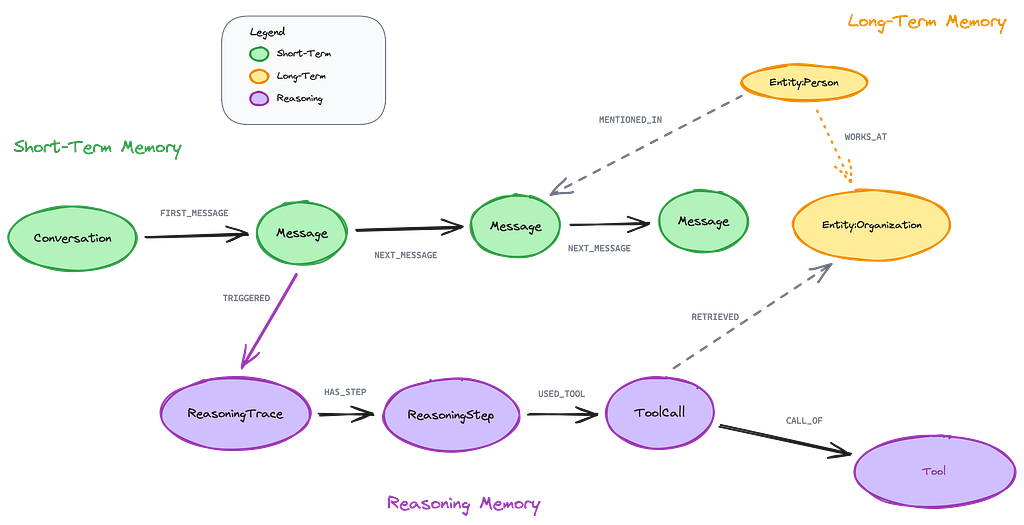
The power of this schema is that all three memory types connect through shared nodes. A message triggers a reasoning trace, which uses tools that retrieve entities, which were mentioned in other messages.
This interconnection enables provenance queries like “show me all entities that influenced this recommendation” or “which reasoning patterns led to the highest user satisfaction.”
Integrating with AI agent frameworks
A key design goal of neo4j-agent-memory is seamless integration with the frameworks and platforms teams are already using. Rather than forcing you to rewrite your agent architecture, it plugs into existing workflows.
Pydantic AI (used in Lenny’s Memory):
from neo4j_agent_memory.integrations.pydantic_ai import create_memory_tools
tools = create_memory_tools(client)
agent = Agent(model="gpt-4o", tools=tools)
from neo4j_agent_memory.integrations.langchain import Neo4jAgentMemory
memory = Neo4jAgentMemory(client, session_id="user-123")
chain = ConversationChain(llm=llm, memory=memory)
from neo4j_agent_memory.integrations.openai_agents import Neo4jMemoryTool
tool = Neo4jMemoryTool(client)
agent = Agent(tools=[tool])
Also supported: LlamaIndex, CrewAI, and any framework that accepts custom tools or memory backends.
The integrations handle the complexity of
- async operations,
- streaming responses,
- and context management
so you can focus on your agent’s logic rather than memory plumbing.
Why graph-based memory matters for organizations
Vector databases solve part of the AI memory problem — they enable semantic search over past interactions. But they treat each piece of information as an isolated embedding, missing the connections that make knowledge valuable.
Graph-based memory captures what vectors can’t:
Relationships are first-class citizens. When Brian Chesky mentions Airbnb’s culture, that’s not just text — it’s a Person connected to an Organization through a FOUNDED relationship, with the conversation stored as provenance. Query the graph to find “all companies mentioned by guests who also discussed pricing strategy” and you get precise answers, not fuzzy similarity matches.
Knowledge compounds across agents. When one agent learns that a user prefers detailed technical explanations, that preference is stored in the graph. Other agents querying the same database inherit that knowledge without retraining or prompt engineering.
Decisions become auditable. This is where reasoning memory pays off. Regulated industries need to explain AI decisions. With all three memory types in a graph, you have the complete audit trail: which data sources informed the decision, what reasoning steps the agent took, and whether similar approaches succeeded in the past.
Insights emerge from structure. Graph analytics reveal patterns invisible in flat data: which topics cluster together, which entities bridge different conversations, where knowledge gaps exist.
These insights inform both agent behavior and business strategy.
Neo4j-agent-memory provides all three memory types with the graph modeling, vector indexing, and query optimization handled for you.
Why graphs are winning for AI agent memory
The market has validated graph databases as the foundation for AI agent memory.
Look at the emerging landscape.
- Zep builds long-term memory for AI assistants using knowledge graphs to connect users, sessions, and facts.
- Graphiti from Zep creates temporal knowledge graphs that track how information evolves over time.
- Cognee uses graphs to build structured memory layers that agents can reason over.
- Mem0 provides personalized AI memory with graph-based entity relationships.
- LangMem from LangChain stores agent experiences as connected memory graphs.
These tools recognized that flat storage — whether relational tables or vector embeddings — can’t capture the interconnected nature of knowledge.
When an agent needs to answer “What did the customer say about pricing in the context of their Q3 budget concerns?”, you need to traverse relationships, not just find similar text.
But building effective context graphs requires all three memory types. Most implementations cover short-term (conversations) and long-term (entities) — but skip reasoning memory. Without recording how agents think through problems, you’re left with a context graph that can’t:
- Explain why the agent made a specific decision
- Learn from successful (and failed) approaches
- Debug unexpected behavior with full provenance
- Improve agent performance based on what actually worked
Neo4j-agent-memory provides all three. Short-term, long-term, and reasoning memory — connected in a single graph with full provenance from question to answer.
From customer patterns to open-source building blocks
We’ve been working directly with teams building AI agents in production. The patterns we saw repeated across implementations inspired neo4j-agent-memory:
Everyone builds the same three layers. Whether it’s a customer service bot or a research assistant, production agents need conversation history (short-term), entity knowledge (long-term), and reasoning traces. Rather than each team reinventing this architecture, we packaged it.
Reasoning memory is an afterthought — until it isn’t. Teams start with conversations and entities, then realize they can’t debug agent behavior or explain decisions. Adding reasoning memory later means retrofitting provenance into an existing schema. Building it in from day one is much cleaner.
Entity extraction is a bottleneck. Teams either over-rely on expensive LLM calls or under-invest in extraction quality. The multi-stage pipeline — fast statistical NER, zero-shot models, LLM fallback — represents the cost/quality tradeoff we’ve seen work best.
Framework integration is table stakes. No one wants to rewrite their agent architecture to add memory. Integrations with LangChain, Pydantic AI, LlamaIndex, OpenAI Agents, and CrewAI mean you can adopt neo4j-agent-memory incrementally.
Neo4j-agent-memory isn’t a proprietary platform — it’s an open-source library that encodes these best practices. Use it as-is, fork it, or treat it as a reference implementation for your own architecture. The goal is to lower the barrier to building production-quality AI agent memory on Neo4j. And please provide feedback to the repository.
Run it yourself
Try the live demo
The fastest way to experience neo4j-agent-memory is the hosted demo:
Use the library in your own project
The neo4j-agent-memory project is available via pip and other popular Python package managers.
pip install neo4j-agent-memory
# With optional dependencies
pip install neo4j-agent-memory[extraction] # Entity extraction
pip install neo4j-agent-memory[langchain] # LangChain integration
pip install neo4j-agent-memory[all] # Everything
Quick start:
from neo4j_agent_memory import MemoryClient, MemorySettings
settings = MemorySettings() # Reads from environment
async with MemoryClient(settings) as memory:
# Store a conversation
await memory.short_term.add_message(
session_id="demo",
role="user",
content="I'm interested in product-market fit"
)
# Learn a preference
await memory.long_term.add_preference(
category="topics",
preference="product-market fit",
context="User expressed interest"
)
# Get context for your LLM prompt
context = await memory.get_context("startup advice")
Help shape the roadmap
We’re building neo4j-agent-memory in the open and want your feedback on what would be most valuable!
- What’s missing? Tell us features you need that aren’t on this list.
- What’s most urgent? Which roadmap items would unblock your use case.
- What’s confusing? Documentation gaps, unclear APIs, or unexpected behavior.
- What works well? Patterns you’ve found effective (we’ll add them to examples)
Create a GitHub issue to share your feedback, request features, or report bugs. You can also join the discussion in the Neo4j Community Forum (tag posts with agent-memory).
Graph-based AI agent memory is the pattern production systems are adopting and the added requirements when introducing context graphs means your agent system needs all three memory types to be effective: short-term, long-term, and reasoning.
Neo4j-agent-memory gives you all three, with the provenance and explainability that production systems demand.
>>>> ⚠️ Neo4j Labs Project — This project is part of Neo4j Labs and is actively maintained, but not commercially supported. APIs may change. For questions and support, please use the Neo4j Community Forum and GitHub issues.
Meet Lenny’s Memory: Building Context Graphs for AI Agents was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Connected Intelligence: Operationalizing Production-Grade Graph Solutions Across Enterprise Networks


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


