
Reposted with permission by Brian Underwood
In my last two posts I covered the process of importing data from StackOverflow and GitHub for the purpose of creating a combined MDM database. Now we get to the really fun stuff: today I show you how I tied the data together!
Tying the data together
The most obvious entities to link between StackOverflow and GitHub is the user profiles. Unfortunately users don’t always have two profiles, don’t fill out both profiles, or just don’t have perfectly matching information between the two. To this end I built record linkage tools which helped me make links between users.
My goal is to create a Person label which ties together nodes from GitHub and StackOverflow (and potentially other sites) as seen below:
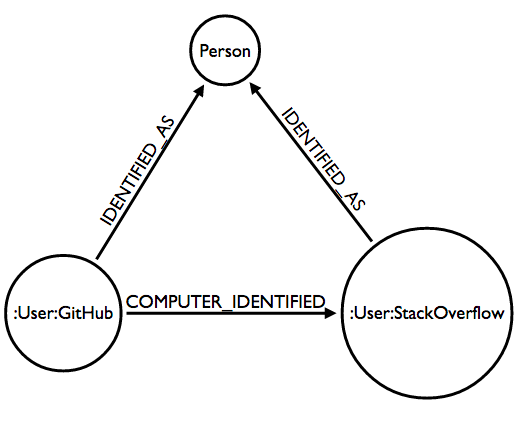
Standardization
My first step to linking records is to standardize data as much as possible. To this end I do a number of things:
StackOverflow users
- From the
website_urlandabout_meproperties:- Pull the Twitter username to a
twitter_usernameproperty if there is a URL which points to twitter - Pull the GitHub username to a
github_usernameproperty if there is a URL which points to twitter - Extract all URIs to the
urisproperty as an array (no URI protocol orwww.)
- Pull the Twitter username to a
- Extract any E-Mail addresses from the
about_meproperty to theemailsproperty - Further reduce
urisandemailsto thedomainsproperty (no paths) - Make a
usernamesproperty with the GitHub and Twitter usernames as well as the StackOverflowdisplay_name
GitHub users
- Extract the Twitter username from the
blogproperty if it points to twitter - Standardize the
blogproperty to theurisproperty as an array (no URL protocol orwww.) - Further reduce
uristo thedomainsproperty (no paths) - Make a
usernamesproperty with the GitHub and Twitter usernames
Post-processing
All of the above generated properties get downcased, stripped of extra whitespace, and stored without duplicates.
After all domains have been looked for, I run the followed to extract any domains which have been used more than once to find and eliminate domains like gmail.com, github.com, neo4j.com, etc…
query.match(u: :User).unwind(domain: 'u.domains').
with(:domain, count: 'count(domain)').where('count > 1').
pluck(:domain)Linkage
With the data standardized we can now easily do record comparison and scoring. Here I go through the millions of combinations of user pairings and give each of them a score. For each pairing I want to create a relationship in the database so that I don’t need to calculate the score again. Since I don’t want to have millions of relationships connecting every single user to every other user, I only create relationships above a score threshold.
I created a class called ObjectIdentifier which allows me to create rules for comparing and scoring records.
identifier = ObjectIdentifier.new do |config|
config.default_threshold = 0.8
config.default_weight = 1.0
config.add_matcher :name, :display_name, &fuzzy_string_matcher
config.add_matcher :login, :display_name, &fuzzy_string_matcher
config.add_matcher :blog, :website_url, &fuzzy_string_matcher
config.add_matcher :location, :location, &fuzzy_string_matcher
config.add_matcher :login, :github_username, weight: 2.0, &exact_string_matcher
config.add_matcher :twitter_username, :twitter_username, weight: 2.0, &exact_string_matcher
config.add_matcher :domains, :domains, threshold: 0.98, &array_fuzzy_string_matcher
config.add_matcher :usernames, :usernames, threshold: 0.98, &array_exact_string_matcher
endYou can see that there are anonymous functions for both fuzzy and exact string matching.
With the identifier object I can call identifier.classify_hash(ghu, sou) to get the following result:
{
[ :name, :display_name ] => 0.9769319492502884,
[ :login, :display_name ] => 0.9769319492502884,
[ :blog, :website_url ] => 0.0,
[ :location, :location ] => 1.0,
[ :login, :github_username ] => 0.0,
[ :twitter_username, :twitter_username ] => 0.0,
[ :domains, :domains ] => 0.0,
[ :usernames, :usernames ] => 0.0,
}Using the identifier object, I then compare every combination of users between GitHub and StackOverflow. With 2,312 StackOverflow users and 6,255 GitHub users there are 14,461,560 potential pairs, which can take some time.
For each pairing my script gets the result hash and calculates a score as the sum of the Hash values. If that score is above a threshold, it creates a COMPUTER_IDENTIFIED Neo4j relationship to represent a hit. The relationship stores the score as well as a hash property with a JSON representation of the result for debugging.
pHash
While comparing strings to strings I realized there was another aspect of the profile that I was missing: The profile photo.
If I could do fuzzy comparisons against the user images I could narrow down the results even further. Fortunately the phashion gem provides an implementation of the pHash algorithm to do just that. So I wrote a quick script to download the profile photos locally and then another to compare the millions of combinations. With all of that downloading and pHashing, I found that I also needed to use the parallel gem to complete in a reasonable amount of time.
So that I didn’t need to compare photos during my ObjectIdentifier process, I simply created aSIMILAR_IMAGE_TO relationship between users to store the result of the pHash (a value between 1 and 15 where 1 is the closest perceived match).
Using Neo4j I don’t need to worry about table structure or if I should create a collection or embed in existing objects. I can create whatever links between users that I need as I play with algorithms that will work for my purpose.
Man vs. Machine
To help guide my algorithms I used the only thing that I had available to me that could do a reasonable comparison of profiles: me. I turned my project into a Rails app which could show my two profiles side-by-side:
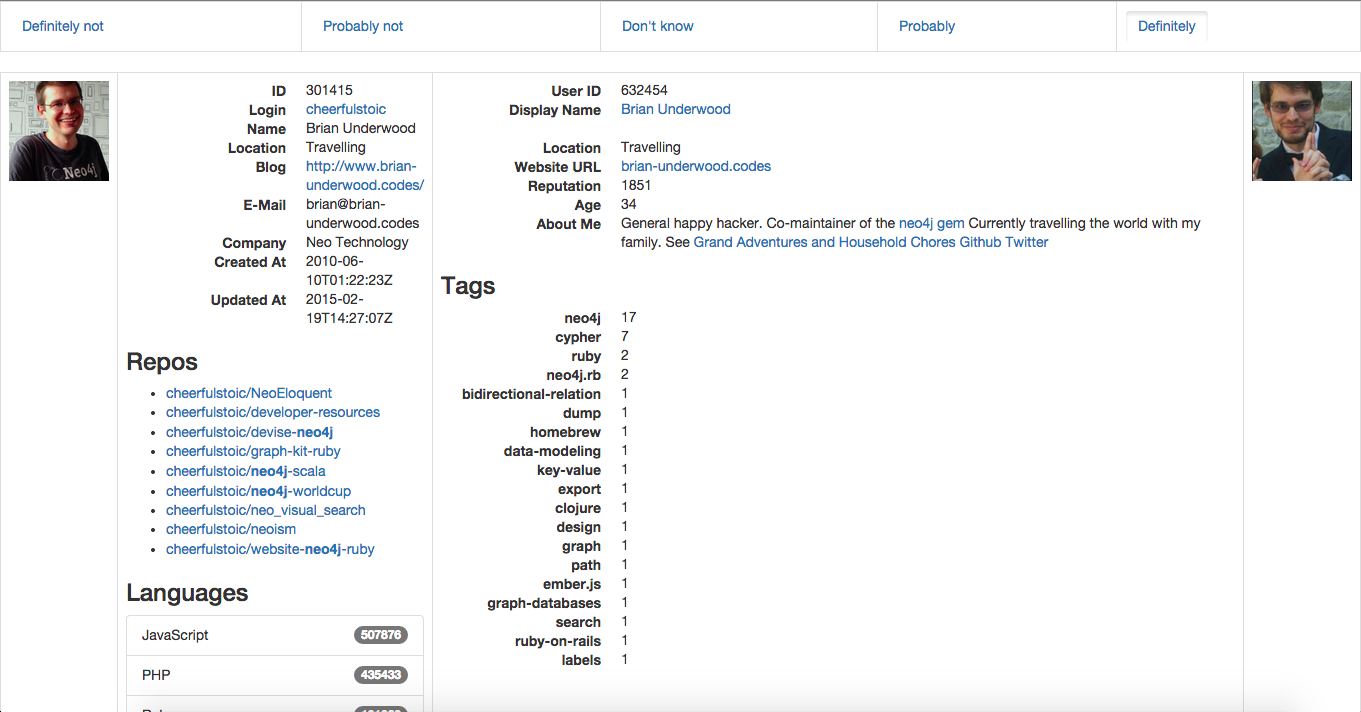
This view would show me a randomly chosen pair of users. 80% of the time those users were chosen because I had algorithmically determined some linkage between them. 20% of the time it would just show me a randomly chosen set of two users which hadn’t already been matched to acts as a control group. I created five links along the top of the page (“Definitely not”, “Probably not”, “Don’t know”, “Probably”, and “Definitely”) and threw in a bit of CoffeeScript to let me choose them via arrow keys.
In making decisions on hundres of pairs of profiles, a number of questions occurred to me:
- How should do I choose between the five levels?
- I made some rules to describe how I evaluate the evidence. By evidence I mean comparing name, location, photo, etc…
- two pieces of matching evidence mean “Probably”
- three pieces of matching evidence mean “Definitely”
- two pieces of contradictory evidence means “Probably not”
- three pieces of contradictory evidence means “Definitely not”
While I placed “Not sure” in the middle, that was a special case which means that I don’t have enough evidence.
- Should I follow links and otherwise research the users?
- No. If I want to determine how well my matching algorithms work, I should use only same data that they have.
- What about pictures?
- I happen to be a human and humans are pretty good at comparing photos, particularly photos of people. I was torn about this, but decided that if two photos were obviously not the same person, I should classify the profiles as different.
Analyzing the result
To figure out how well my classification algorithm worked I turned, of course, to R. Using RNeo4j I run a query to get the human score (from -2 as ‘Definitely not’ and 2 as ‘Definitely’) and the computer score (for the rules I specified this runs from 0 to about 6):
query <- "MATCH
(ghu:User:GitHub)-[ci:COMPUTER_IDENTIFIED]-(u:User),
MATCH ghu-[i:IDENTIFIED]-u
RETURN ci.score, toInt(i.index)"
result <- cypher(graph, query)
plot(result[[2]], result[[1]], xlab = "Human Score", ylab = "ObjectIdentifier score")…and plot the results…
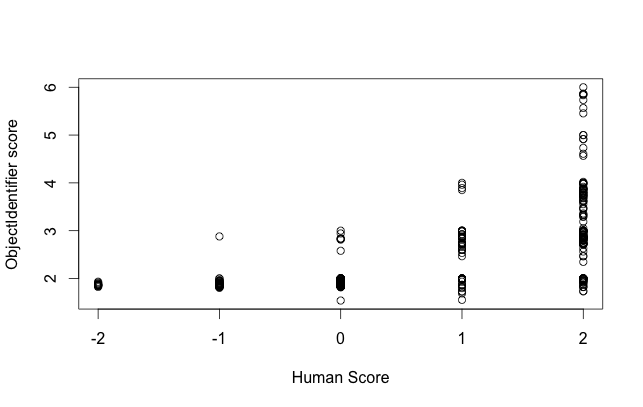
This shows me that I should be able to relatively safely classify an ObjectIdentifier score of around 3 and up as the same user. A score of 2.5 and above looks promising, though looking in that range for users with a human classification of Not sure there are some false positives. I suspect I can improve the correlation between the two by adjusting the algorithm scoring/weights.
That’s plenty to digest for now, so next time I’ll show the sorts of queries that can be run on the linked database! You can see all the code on the GitHub repository.
If you want to talk more in person, feel free to drop by one of my upcoming speaking engagements!
Update!
Making Master Data Management Fun with Neo4j – Part 1
Making Master Data Management Fun with Neo4j – Part 2
Share Article



Explore
Related Articles

Top 10 graph database use cases (with real-world case studies)

Connecting data across the enterprise: The 5-minute interview with Simone Novali


Neo4j as an embedded database: The key use cases of graph databases

Neo4j as an embedded database: When does embedding a graph DB make sense?
