
A Conversation with Graphs

17 min read

Editor’s Note: This presentation was given by Tatiana Hartinger at GraphConnect New York in September 2018.
Presentation Summary
Tatiana Hartinger is a mathematician and a Cognitive Solutions Consultant specializing in graph theory from Cognitiva. Cognitiva is using graphs to enhance virtual assistants.
Cognitva has combined the technology in IBM’s Watson Assistant with a Neo4j-supported graph database. The problem the virtual assistant is trying to solve is to give fast recommendations to customers based on requests and interests.
Watson Assistant works with intents and entities. Intents represent the purpose of a user’s input. Entities represent a term or an object that is relevant to the intents.
The graphs used for the virtual assistant come with different types of vertices. The vertices are color coded and each vertices has a type value. The type values are possible answers to the questions of the vertices.
To combine the virtual assistant and Neo4j, Cognitiva uses a Python script that goes back and forth between the two.
The code consists of three main parts:
- The creation of the graph in Neo4j
- The functions that are used to create the vertices and edges are used to calculate the weights for the edges
- Part of the code makes it possible for us to connect between dialog in Watson Assistant while making queries in Neo4j
In order to illustrate how the solution works, Hartinger uses a movie recommendation example and summarizes with benefits and the potential of this solution.
This technology could one day expand to sales of a specific product, preliminary medical diagnosis, patient assistance and other fields where interaction is a key step in problem solving.
Full Presentation
My name is Tatiana Hartinger, I’m a mathematician, and during my PhD studies, I specialized in graph theory. I currently work as a cognitive solutions expert in the technical area at Cognitiva in Buenos Aires, Argentina. We implement solutions related to artificial intelligence.
One of the solutions that we implement is that of virtual assistants for different types of companies. This is for telecommunications companies, financial services and health-related industries.
My talk is based on joint work with Federico Costa and Javier Portillo.
Our solution came up when our team leader had the idea of enhancing virtual assistants with the use of graphs. That’s when we started investigating ways to do this, and finally we came up with the solution.
Introduction
We combined the technology of IBM’s AI Watson Assistant with the use of a graph database supported by Neo4j. We wanted to be able to make a recommendation to a customer – based on their preferences or desires – and we wanted this in the shortest time possible.
The specific example I’m sharing is a movie recommendation, but of course, it could be applied to all different types of recommendations or search. The graph database will contain all the information that we need in order to be able to make a recommendation.
What’s important is that our graph will be provided with weights on certain ages that we will calculate using a metric of our choice. These edge weights are the key ingredients that make it possible for us to do this process of recommendation in the fastest way possible.
The Problem We Want to Solve

Our goal was to, in the context of a virtual assistant, give a fast recommendation to a customer based on a request and/or interests.
We may assume that this is the first time we’re interacting with the customer. We have no previous knowledge about their preferences or their likes. We would like to gather that information, and that’s where our virtual assistant comes into action.
We would like our assistant to ask the questions in order to get to know the user’s preferences. We would like this to be a good user experience. Besides the part of having a chat in natural language, which happens because of Watson Assistant, we would like the process to take the minimum amount of time possible.
This is where our graph with Neo4j comes in.
Watson Assistant Tool
I’m going to talk a little bit about the IBM Watson tool, which is where we developed our virtual assistant.
With IBM Watson Assistant, you build a solution that understands an input in natural language and then use machine learning in order to respond to the customer’s questions in a way that simulates a conversation between humans.
These types of solutions are implemented with the technology of IBM Watson Assistant, and are capable of providing answers to the queries that users may have in a specific domain.

Watson Assistant analyzes unstructured data and processes natural language. To understand grammar and context, we trained the solution to understand complex questions and evaluate all possible meanings in each case.
The Watson virtual assistant applies learning techniques to make predictions about the best classes, predefined for sentences or phrases.
This “thinking” service done by the virtual assistant interprets an intention behind a text and returns a classification which corresponds to certain confidence levels.
Whatever value is chosen is then used to trigger a corresponding action. This corresponding action could be redirecting an application or answering a question.
Our bot is trained in a specific domain, in each case, according to the specific knowledge of the AI trainers, which would be us at Cognitiva, as well as the domain specialist, which would be the companies that hired us to do this virtual assistant.
Intents and Entities
Watson Assistant works with intents and entities.
What is an intent? It represents the purpose of a user’s input. For example, the request for a movie recommendation, or for the best product for their needs – it could be anything.
An entity represents a term or an object that is relevant to your intents. These are pieces of information we obtain from the user. In our case, we define all possible answers to the different questions that may arise as values of an entity.

If we consider the entity Genre in the case of a movie recommendation, we would have values: drama, sci-fi, comedy, romance, etc.
Below on the right, you see an image of how a dialog in Watson Assistant looks like. You see it has a tree-like structure. It always starts with a welcome node and it ends with an anything-else node, to which everything that doesn’t correspond to the condition of all the other nodes goes.

Whenever a user enters an input, Watson Assistant verifies whether this input corresponds to one of the conditions of the nodes and whether this condition in the node is satisfied or not. If it is, it will continue with whatever we establish in said node; we will give an answer and maybe jump to another specific node or anything else that we would like it to do.
Design of our Graph
Let me tell you about the design of our graph using Neo4j.
This graph will contain different types of vertices. We define these vertices by type of question, which are the ones that you see below in blue on the second layer.
For example, if we consider the movie recommendation, this would be genre, favorite actor, favorite director, maybe the release date of the film. These are all things we will ask the user about.
Below those, we have the vertices of type value. Each value doubles as a possible answer to one of our questions.
Below in pink, we have all the possible directors, which are adjacent to a vertex of type question director. In red, we have all the possible genres of the movie. In green, we have the different types of dates the movie could have.

In our case, we separated into modern and classic. And then we have in gray all the vertices of type actor, and these are adjacent, of course, to the vertex actor.
On the bottom in yellow are our recommendation vertices, which are all the movies from our database. The results are on the top. You see a dummy vertex, which we named Start, and this vertex will be adjacent to all the vertices of type question.
As I mentioned before, each type question will be adjacent to all the vertices corresponding to the possible answers to said questions.
Finally, we have the recommendation vertices on the bottom and the adjacencies for this type of vertices will correspond to the characteristics of the vertex.
Let’s say we see the movie Sleepless in Seattle marked in red.
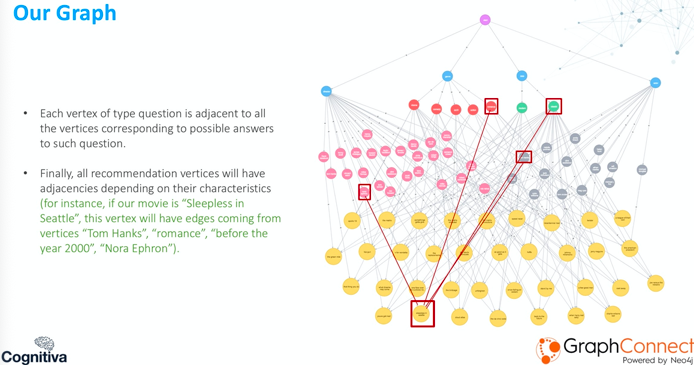
Then it will have edges coming from Tom Hanks, because he’s an actor in the movie. It will have an edge coming from Classic, because it’s before the year 2000. Then it has an edge coming from Romance, because that’s the genre of the movie. Finally, we have an edge coming from Nora Ephron, who is the director of the film.
Of course, for this example, we are showing a really small graph. We decided to keep it simple and only have movies adjacent to one actor, one director and one genre. Of course, this could have many adjacencies in real life.
The edges between the vertex Start and the vertices of type question are the ones that will have the edge weights. These weights correspond to the minimum number of potential recommendations that would be ruled out if we were to ask the user for that question.

Our aim is to ask the question of which corresponding edge has the maximum weight. This will guarantee that, even in the worst-case scenario, we will get to our recommendation vertex faster.
Let me explain this in more detail.
What we do is first, for each possible answer B to a question Q, we calculate the number of movies that would be ruled out if we were to ask question Q to the user and the response to that would be B.
Then we take the minimum amongst those answers B to question Q as the weight of the edge between our dummy node Start and the question-type node Q.

Finally, we take the question whose edge has the maximum weight. This is the one that we will choose as the best question to ask.
Now, once we ask the question to the user and we obtain an answer from the user, the graph will be updated. Then we will delete all the vertices and edges that will no longer be relevant to us and calculate the edge weights.
How to Combine the Two
Now, let me tell you how we combine the two aspects of our solution; our virtual assistant in Watson Assistant and our graph in Neo4j.
In order to do this, we wrote a Python script that will go back and forth between Watson Assistant and Neo4j. We used the following libraries: JSON, Watson Developer Cloud and Py2neo.
The code consists of three main parts.
The first one is for the creation of the graph in Neo4j. As we described it before, we used some functions to create the vertices and edges.
Then we have some functions that will be required in order to calculate the weights for the edges that I mentioned between Start and the questions. We defined this metric that we have seen before, and we create a function that determines the best question to ask in each step of the solution. We will also have some functions that will be able to modify the graph by Cypher queries in Neo4j.

Finally, we have the part of the code that makes it possible for us to connect between dialog in Watson Assistant while making queries in Neo4j.
We created this dialog in Watson Assistant which contains all the intents, entities and context variables that we’ll need for this task. Once the intent is detected, Watson will proceed to ask the necessary questions in order to obtain a recommendation for the user in the shortest time possible.
After each question, the user’s response will be stored in a context variable and will be used to modify the graph. What’s important to note is that we also consider the case when the user does not have a clear answer for one or more of the questions.
In that case, we will modify the graph accordingly.
Here we see a small diagram of our solution:

On the one hand, we have Watson Assistant. We have the conversation with the user, and then we have our code connecting the two parts.
On the other side, we have our graph database in Neo4j, which contains all the information we need to make a recommendation for a user.
Whenever we detect an intent, we start a conversation. The user writes down something, then Watson detects an intent – this will tell us which graph we need to look at. Then we will proceed with calculating the best question to ask in this step.
This information will travel back to Watson Assistant. The assistant will ask the user that question, obtain the answer and use that answer to modify the graph. We will continue with the same procedure.
A movie recommendation example
Let me show you an example of a movie recommendation of how this solution would work.
First, we have Start vertex at the top. Then we have those four vertices of type question. The questions that we considered for this example are the director, the genre, the date and the actor of the movie.
We then have the vertices of type value in pink. All of the directors are in red, all the genres for the movies are in green. We have the release dates, separated by the year 2000 between classic and modern. Then in gray we have all the possible actors.
Finally, at the bottom, we have our recommendation vertices. Recommendation vertices are the movies from our database. We are trying to get to one of these movies as a recommendation for a user.

Let’s check what the current status of the graph is in this part of the solution, at the beginning.

We have 14 vertices of type actor, two vertices of type date, 26 directors and five genres. We are starting with 46 movies in our database. We have four possible questions to ask the user. We have our dummy vertex named Start.
Since we have these four possible questions to ask, we will have the weights on the edges between our dummy node Start and those question vertices. We will calculate them using the metric that I mentioned.
We will calculate the number of possible movie recommendations that would be ruled out if we were to ask about the actor of the movie to our user, and there we obtain that the edge weight between Start and actor is 27.
We do the same for the other three questions and obtain that the weight of the edge between Start and date is nine, the weight of the edge between Start and director is 32, and the weight of the edge between Start and genre is 23.

Since we are looking for the maximum, the best question to choose in this first step would be the director. This is virtual assistant what Watson will ask the user. Here, we see how the graph looks in the first step and we have all the corresponding edge weights between Start and all the question-type vertices.
This is how the conversation may happen. First of all, the assistant says, “Hello there, what can I do for you?” The user may reply something like, “Can you recommend a good movie for this weekend?”
In that case, Watson Assistant will detect the intention, which is movie recommendation. This will trigger a response, which is, “Sure, I’m here to help.”

That is when we will have a look at the graph that we had before, and we go to the graph and obtain the best question to ask in this case.
We determined that this question is about the director of the movie. “Do you have any favorite director?” To which the user may reply, “Not really.” It’s possible to not have a preference, and that’s fine.
In that case, Watson Assistant will detect the entity Director and the value will be “I don’t know.” This will trigger a response.

“Okay, no problem, “I’ll choose for you then,” and we will save this information that we obtain from the user in a context variable, which is director.
We will use this context variable in order to modify our graph. Now, let’s have a look at how the graph is looking in this step.

If we look at the current status of the graph, we have 14 vertices of type Director, two of type Date, five Genres and the number of Movies is still 36 in this case. We couldn’t rule out any of those because we didn’t obtain any information from the user, but the number of questions has been reduced to three.
Now we have these three possible questions, we need to calculate the edge weights between Start and the three remaining questions.
We do this, and we obtain a weight of 27 for the edge between Start and Actor, we obtain a weight of nine between Start and Date, and a weight of 23 between Start and Genre.
Since we are looking for the maximum one, we will choose as the best question in this step to ask about the actor of a film.

Here, we see how the graph looks in this step.
The vertices of type Director has disappeared because this will no longer be relevant information for us. We already asked the user about it so we will not ask again, and we have three possible question vertices.
The dialog continues. We know we need to ask about the actor, so the assistant will ask, “Who’s your favorite actor?” To which the user may respond, “I’m a big fan of Tom Hanks.”

We get this information. We detect the entity actor, and this time the value will be Tom Hanks.
We store this information into a context variable that we will use in order to modify the graph. Let’s have a look at how the graph looks like now:

We have two vertices of type Date, five of type Genre. Notice that in this step, the number of possible recommendations have reduced significantly. We have nine films remaining, and the number of questions that remain is two.
In this step, we need to calculate the edge weights for the two edges between Start and these two possible questions.
We calculate the edge weight between Start and Date, which is three. Then we calculate the edge weight between Start and Genre, which is four. We are interested in the maximum, so we will take the genre of the movie.
Let’s look at the graph now.

The graph is much smaller in this step. We no longer have the vertices of type Actor, and the question vertex Actor has disappeared as well. These are no longer relevant to us. We have these two questions remaining: Genre and Date of the movie, and we established that the best question to ask is about the Genre of the movie.
That’s how the conversation will proceed. The assistant will ask, “What type of genre would you prefer?” The user may say, “I feel like watching a romantic movie.” In that step, we will detect the entity genre with value Romance.

Once more, we will save this information into a context variable genre, which we will use to modify the graph again.
In this step, if we look at the current status of the graph, we have two vertices of type Date, one vertex of type Movie.

We are now in the position of making our recommendation for a user, and we still have one question remaining. There is a question that we didn’t need to ask. If we would have done this in the traditional way, we would have asked all the questions, but with this solution, we saved one question.
This was a really small example, we wanted to keep it simple so that the solution could be seen easily. This is where we gain the most if we have a huge amount of data, we rule out a lot of possible recommendations.
This is our graph now.

We have one remaining vertex type called Recommendation. That’s the movie that we will recommend. It’s also possible to want more than one recommendation; we could have a list of three, five or any number of recommendations that we give to the user and they could be ordered according to some ranking that we decide.
The assistant will recommend this movie.

The movie is Sleepless in Seattle. We know it’s a classic, it’s a romance movie from the year 1993, it features Tom Hanks and Meg Ryan, and is directed by Nora Ephron.
We got our recommendation in the end.
Summary
Our main goal was to use a virtual assistant in order to give a fast recommendation to a customer, which is based on their interest or requests. We model all the information that we need to solve this problem in the form of a Neo4j graph database.
We create an instance of Watson Assistant that will make our conversation possible. We combine these two aspects of the solution; whenever the assistant detects a certain intent, it will start making questions to the user to find out about their preferences in an order which is determined by our graph via edge weights.
Once it obtains an answer from the user, it will store this information in order to modify the graph, and continue with the conversation in the same way until we have all the necessary information in order to make our recommendation.
To sum up this solution, what we obtain is a recommendation through a process that simulates a conversation between humans and using a model in Neo4j that allows us to get to a solution in the shortest time possible.

Benefits/Potential of the Solution
Usual virtual assistants have the limitation of being trained uniquely for answering a user’s questions. In general, they are reactive, the dialog tends to be unidirectional and their intelligence consists only on interpreting a user’s request and giving an answer to it.
What we think is the next step for this type of technology is to establish an interactive and bidirectional dialog, where the virtual assistant is the expert in a specific domain and provides useful guidance to the user by making the most relevant questions appear first. Ultimately, the goal is to help users to come to the best answer as quickly and efficiently as possible.
We added another layer of intelligence to the virtual assistant through one or more graphs containing all the information that an expert in the field might have.
What we think are some possible applications for this type of solutions could be a sales advisor or an expert salesman on a specific product.
We could have graphs corresponding to different types of products. We could have a graph for a refrigerator recommendation, one for microwave ovens, one for TVs and et cetera. The recommendation vertices in those cases would be the products that we have available. Then the questions could correspond to the size, the price, or any type of characteristics from these products.
Then it could also be applied to preliminary medical diagnosis or assistance for patients. Our nodes could be all the possible diseases, and then we could ask about the different symptoms that the patient has.
Finally, for problem resolution for technical support, we would like the assistant to ask questions to the user in order to guide him in the best direction to get to the specific malfunction of the device that we’re interested in helping with.
I’d also like to mention that this same solution might have graphs on different themes or subjects, so the assistant could be able to give guidance to the user in more than one topic at once, and it will detect all these different types of intents from it.
At Cognitiva, we enhanced our virtual assistant with the use of the Neo4j graph database by making them reactive and making them able to ask the best questions in each step. This process helps to know the user preferences and do this in the fastest way possible so that we are able to provide valuable advice for the user.
Share Article



Explore
Related Articles



How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs


Beyond Vector Search: Unleashing the Power of GraphRAG for Smarter Recommendations
