
Accelerating Towards Natural Language Search with Graphs

Associate Sales Engineer, Neo4j
5 min read

Natural language processing (NLP) is the domain of artificial intelligence (AI) that focuses on the processing of data available in unstructured format, specifically textual format. It deals with the methods by which computers understand human language and ultimately respond or act on the basis of information that is fed to their systems.
According to analysts, 80 to 85 percent of business-relevant information originates in text format, which gives rise to the necessity of computational linguistics and text analytics in extracting meaningful information from a large collection of textual data.
In order to analyze large amounts of text, having a convenient structure to store the data is essential. One critical metric in text analysis is understanding the context and relationships between occurrences of words. A convenient data storage should intend to store the extracted meaning in a connected way.
Neo4j – a graph database platform – is able to connect bodies of text and establish context as to how they relate to each other. This also applies to words, sentences and documents. Such relationships are very useful when drawing inferences and insights quickly from the text at scale, which makes Neo4j suitable for NLP.
In this article, we’ll look at how graphs can be leveraged for NLP. We’ll learn how to load text data, process it for NLP, run NLP pipelines and build a knowledge graph from the extracted information in the Neo4j database. We’ll also take a look at how you can take a pre-existing graph and build a natural language query feature on top of it.
(Note: if you’re unfamiliar with the basic NLP terms, check out this glossary of basic NLP terms by KDNuggets.)
Neo4j and Natural Language Processing
Natural language processing is achievable by leveraging the power of graphs with Neo4j.
From a high-level perspective, elements of text are stored as nodes in the database and the connections between those words are stored as relationships. Tags and named entities are also stored as nodes connected to their respective elements or words of the text.
What you’ll need:
- Neo4j graph database
- Py2neo – Python driver for Neo4j
- GraphAware libraries (jar file)
- Stanford CoreNLP (jar file)
- Natural Language Toolkit (NLTK)
- SpaCy
- Python editor or environment (i.e. Jupyter Notebook)
The power of NLP can be unlocked in Neo4j by using the GraphAware platform plugin, which is a NLP platform that supports Stanford CoreNLP and OpenNLP under the hood.
With the plugin, all the text is broken down into tokens, then tagged and stored as nodes in the database. The occurrences of tags are stored as relationships.
In Neo4j, GraphAware allows users to create a pipeline in which they can select steps such as tokenization, stop-words removal and named-entity recognition (NER), among others. Users can also select which processor to use for the same (Stanford CoreNLP or OpenNLP).
After running the pipeline on the corpus (i.e article nodes), the pipeline annotates all parts of the text by separating elements of the sentences into tags, where each tag becomes a separate node and the tag relation becomes the relationship in the database.
Setting Up Your Database
Let’s walk through the process of loading the corpus into a Neo4j database. Here, our corpus is a collection of news stories from BBC business articles that were initially stored as text files. To work on it, we’ll need to include this text in our database. Moreover, we recommend adding the original file path as a property of every article node so that we can keep track of each article.
A simple Python program can iteratively grab all the text from each file and dump it into a Neo4j database. To do this, we’ll need the py2neo driver package, which is a community driver used to connect to the Neo4j database. We’ll also need a database to connect to in order to provide authentication details to the driver for database access.
We’ll first connect to the database using py2neo:
graph = Graph(host='localhost', user='neo4j',password='password') tx = graph.begin()
After, you will need to enter your database’s username and password in the respective fields, get all the articles and place them in the database:
for filename in glob.glob(folder_path):
with open(filename, 'r') as f:
file_contents = f.read()
Nodes = Node("Article",Text=str(file_contents),path=filename)
print(Nodes)
graph.create(Nodes)
tx.merge(Nodes)
You’ll need to specify your folder path in the glob() function.
In the Node() function, we specify a label – “Article” – for the nodes. Text in the documents is added to those nodes as property “Text”, and path also becomes a property called “path”.
graph.create() will create a graph with all the nodes, and tx.merge() will actually load it into our database.
Now let’s go back in the database and check if our text has been loaded.

Bingo! We have an article as a node in the Neo4j database.
We now need to create something called an NLP pipeline, which is a series of operations that are performed on the text. GraphAware has provided a set of functions that can be programmed with Cypher to perform a variety of operations on the text, such as tokenization, entity recognition and dependency parsing.
This is how we’ll create a pipeline:
CALL ga.nlp.processor.addPipeline({
name:"pipeline_name",
textProcessor: 'com.graphaware.nlp.processor.stanford.ee.processor.EnterpriseStanfordTextProcessor',
processingSteps: {tokenize:true, ner:true, dependencies:true, relations:true, open:true, sentiment:true}
})
Please refer to the GraphAware documentation in order to explore and understand the methods of the GraphAware library for Neo4j.
Now, let’s check if our pipeline has been created:
CALL ga.nlp.processor.getPipeline()
You should have a pipeline created, with the name pipeline”, and all the steps included.
Now that we have our pipeline, let’s run all the text we have through it and tokenize and tag it. The structure of graphs gives us an advantage of storing “what-goes-where” as the relationships and is very helpful for lookup.
In order to annotate all the text we have, we’ll run annotation function. For larger sizes of data, we recommend using a function from the APOC library from Neo4j (apoc.periodic.iterate) to produce faster results.
CALL apoc.periodic.iterate(
'MATCH (n:Article) RETURN n',
'CALL ga.nlp.annotate({
text: n.Text,
id: id(n),
pipeline: "pipeline_name",
checkLanguage:false
})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)',
{batchSize:1, iterateList:false})
This will break down the text, annotate it with respective identifiers and create necessary relationships.
By annotating everything and identifying what our content is, we can check how the text has been broken down from sentences to words to tags.
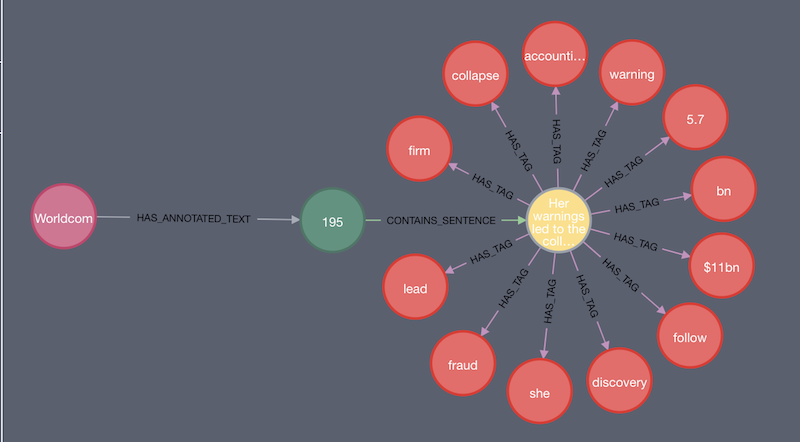
In the image above, the article (the pink node) branches into a sentence that has further been broken down into words (the red nodes). This will happen for every sentence in the article and for all the subsequent article nodes.
After decomposing the entire text into parts, let’s see if we can get some insight from the text using Cypher queries.
Let’s see the top five most mentioned organizations in these articles:
MATCH (n:NER_Organization) RETURN n.value, size((n)<-[:HAS_TAG]-()) as Frequency ORDER BY Frequency DESC LIMIT 5
Let’s also do the same for top five most mentioned people:
MATCH (n:NER_Person) RETURN n.value, size((n)<-[:HAS_TAG]-()) as Frequency ORDER BY Frequency DESC LIMIT 5
We can also check which companies have the most mentions in a negative context:
MATCH (tag:NER_Organization)-[]-(s:Sentence:Negative)-[]-(:AnnotatedText)-[]-(a:Article) WHERE NOT tag:NER_Person AND NOT tag:NER_O RETURN distinct tag.value, count(a) as articles ORDER BY articles DESC;
In the process of building a knowledge graph, we’ll extract some information regarding who works where and in what capacity or role:
MATCH (o:NE_Organization)-[]-(p:NE_Person)-[]-(t:TagOccurrence) WHERE NOT t:NE_Person AND t.pos IN [['NN']] RETURN DISTINCT p.value AS Person, collect(distinct t.value) as Title, o.value AS Company ORDER BY Company
We can also construct meaningful relationships using these insights, hence moving towards actually building a knowledge graph.
Also, make sure to note that doing natural language processing search in a Neo4j database has allowed us to transform plaintext news articles into a knowledge graph. This becomes a sweet spot for Neo4j, in which we’re able to transform 510 business news articles into meaningful insight!

In the first phase, we extracted information from raw text to create a knowledge graph and tie the pieces together. The knowledge graph integrates all of the information using links and helps reasoners derive new knowledge from the data.
Natural Language Query for Neo4j
Some of the main applications of our knowledge graph are conversational interface and natural language search for a database. In the following section, we’ll build a natural language query feature for our database and knowledge graph.
In order to map a question to the graph, we’ll need to break down the question to its atomic elements as well. We’ll do this in Python using SpaCy for NLP, and we’ll also use the py2neo driver to connect to the graph.
Quite close to what we did in the graph, we will be running the question through an NLP pipeline to produce tags and receive linguistic identifiers regarding the words involved in the question. Identifying keywords in the question helps us seek out what exactly is asked.
First, we’ll have to connect to our Neo4j database using py2neo:
graph = Graph("bolt://localhost:7687",auth = ("username","password"))
tx = graph.begin()
Let’s actually enter a question and work on it. For demonstration purposes, we’ll ask the question, “Where does Larry Ellison work?”
From here, SpaCy will tokenize the question and tag its contents into linguistic identifiers. These tokens – generated from their respective questions – will serve as our set of identifiers, and tell the system to look for suitable nodes in the graph.
This image below breaks down the question into words and tags them with its identifiers.

In the following block of code, we are running an NLP pipeline on the question which is tokenizing, tagging, performing named entity recognition and dependency parsing, and rendering it as the diagram above.
nlp = en_core_web_sm.load() doc = nlp(question) ner = [(X.text, X.label_) for X in doc.ents] print(filtered_question) for token in doc: print((token.text, token.pos_, token.tag_, token.dep_)) print(ner) displacy.render(doc)
We have a named entity recognized from the question which we have to use in the Cypher query as a parameter. For this, we can use our logic – that if the question contains any named entities, we’ll put them in a parameter according to their types (such as person, organization, location).
The block of code below checks if we have more than one named entities, or if the type of named entity is an organization. It then puts it in a key-value pair.
if (len(ner[0])>2):
parms_2 = {"name1":name1, "name2":name2}
print(parms_2)
else:
parms = {}
parms["names"]=names
print("Parms: ",parms)
if (ner[0][1] == "ORG"):
parms_1 = {}
parms_1["org"] = [ner[0][0]]
print(parms_1)
This is going to be used as a parameter in the following Cypher query:
Tagged names are: [[‘Larry’, ‘Ellison’]]
Parms: {‘names’: [‘Larry Ellison’]}
As mentioned before, we will use the set of tokens generated from the question to identify and construct the Cypher query we want to use by putting appropriate parameters into it.
Here, for the parameter, “Larry Ellison,” our Cypher query would look something like this:
MATCH (p:Person) -[r:WORKS_AT]-> (o:Organization) WHERE p.value = "Larry Ellison"
By declaring components of our query as strings (variable=”(var:Label)”) and building the query using those components, we produce:
query1 = '''
match {} {} {}
where p.value IN $person
return p.value as Name,r.value as Works_as,o.value as at
'''.format(label_p,works,label_o)
Finally, we’ll run the query shown below with the graph.run() function of py2neo to produce our results. Although this will generate a simple results table in textual format, we recommend taking this query and running it in the Neo4j browser in order to visualize relationships.
for word,tag in tags:
if word in ['work','do']:
verb = word
print('We have a verb: ',verb)
print(graph.run(query1,parms).data())
Since we have the verb work in the question we asked, we can construct a query around that verb by selecting the appropriate relationship in the query:

So if you have a knowledge graph containing ‘n’ people, we can utilize this query to get the same information for all those people, implying that designing the right queries answers almost all questions for a knowledge graph.
While we can run the entire set of NLP operations inside a Neo4j database and then extract and create something valuable, we can also take an already available knowledge graph and use NLP to query it with a natural language interface.
Let’s take a look at how to do that!
NLP on Top of Neo4j
In this example, we will not be running NLP pipelines inside a Neo4j database. Instead, we will be using NLP libraries in Python to build a near-natural language querying feature on top of the Panama Papers dataset by ICIJ loaded into Neo4j. The Panama Papers dataset contains records of offshore investments by entities as well as various organizations’ roles regarding these investments.
Essentially, we’ll be running an NLP pipeline on the question instead and utilize the tokens from the question to produce the Cypher query we desire. The objective here is to create a conversational system on top of an existing graph database, and perhaps utilize graph algorithms such as PageRank to get the most influential entities in the graph.
We have implemented a simple conditional programming paradigm to build a query using string-building based on the tokens in the question.
Let’s first connect to the Neo4j database:
def connect():
graph = Graph("bolt://localhost:7687",auth = ("username","password"))
tx = graph.begin()
print('Connected...')
We will then ask users to input a question. For this example, let’s ask: ‘Which locations come under Panama jurisdiction?”
def ask_question():
question = input("INPUT: ")
print("n")
Now that we have a question, let’s run some NLP functions on it.
First, let’s tokenize and tag the question. The image below breaks down the question into words and tags them with its identifiers. This is how it should look:

Similar to what we did with the question before, in the code below, we are running an NLP pipeline for tokenizing, tagging, performing named entity recognition and dependency parsing, and rendering it as the diagram above.
def tag_question(): doc = nlp(question) tokens = [token.text for token in doc] pos = [pos.pos_ for pos in doc] tags = zip(tokens,pos) tags = list(tags) ner = [(ner.text,ner.label_) for ner in doc.ents]
Next, we need to build parameters based on the named entities in the question in order to use it in the Cypher query:
def parms_builder():
if len(ner) == 1:
if (ner[0][1] == 'GPE') or (ner[0][1] == 'LOC'):
if (ner[0][0] == "US") or (ner[0][0] == "USA"):
country_ = 'United States'
elif (ner[0][0] == "UK"):
country_ = 'United Kingdom'
else:
country = ner[0][0]
parms = {}
parms["country"] = country
Now that we have tokens and parameters, we can start building the Cypher query based on these. Try to pick out at least two sets of unique tokens from the question and utilize it in the condition to construct the query. We can also use the any() and all() functions from Python to check with the elements in our tokens’ list.
Once we are in the loop, we need to specify which node and relationship to look for, and pass them as parameters to the string builder as well.
Finally, we’ll use the graph.run() function in py2neo to run the Cypher query and produce our results:
if token in (all(['come','under']) and ['jurisdiction']):
match_0 = "MATCH {}".format(label_entity)
query = match_0 + "WHERE entity.jurisdiction_description CONTAINS $country RETURN collect(distinct entity.countries) as Locations, entity.jurisdiction_description as Jurisdiction"
print(graph.run(query,parms).to_table())
In the table below, we can clearly see there are a lot of countries which indicate that entities from these locations used Panama as their jurisdiction of choice. (Note: The output has been reformatted to look more readable.)

This system has a limited scope for the types of questions that can be asked of it, as the rules for fetching a query are programmed manually without the use of machine learning (ML). However, by increasing the number and type of questions, it is quite possible to increase the model’s scope.
An ML approach was tried on a sample to detect the nodes automatically, but it did not yield sufficient accuracy for its use in this application. However, a larger vocabulary could result in improved accuracy.
Moving Forward
The path forward would be to replace dynamic string building with dynamic Cypher query building, or automatically building a Cypher query from the question. This would require complex modelling techniques as well as a suitable training-testing dataset underneath in order to produce the best results.
Octavian’s blog post regarding sequence translation is a good read for those who desire to obtain a deeper technical perspective. Another paper called “Cognitive Natural Language Search Using Calibrated Quantum Mesh” published by the Institute of Electrical and Electronics Engineers (IEEE) also leverages the graph structure for natural language search.
Circling back, the structure of the graph model makes natural language processing easier. Graphs have the power to transform raw data into information – such as knowledge graphs – and this ability makes Neo4j a good candidate for solving ever-growing problems in AI.
All code used in this blog post along with the data used in our examples can be found on Github.
Read the white paper, Artificial Intelligence & Graph Technology: Enhancing AI with Context & Connections
Share Article



Explore
Related Articles




How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs

