Advanced Neo4j at FiftyThree: Reading, writing & scaling – oh my!

Engineering Lead, FiftyThree
17 min read

Editor’s Note: Last October at GraphConnect San Francisco, Asseem Kishore – Engineering Lead at FiftyThree – delivered this presentation on advanced read and write queries in Neo4j.
For more videos from GraphConnect SF and GraphConnect Europe, check out graphconnect.com..
My name is Aseem Kishore, and I’m a developer at a startup in New York called FiftyThree which makes an iOS app available on iPhone and iPad called Paper. The purpose of the app is to let you capture your ideas as quickly, efficiently and beautifully as possible.
Ideas come in many shapes and forms including text, lists, checklists, photos and drawings. With our app you don’t have to cut and paste text; you can drag and drop text and with a feature called Swipe-to-Style, and you can indent lists with a swipe.
Photos can be included and annotated, and you can sketch graphs and draw pictures. Through its social and collaborative layer, we have a cloud that lets you share your ideas, follow others and remix other people’s ideas. This sharing service is powered entirely by Neo4j.
I’ve presented at previous GraphConnect conferences about FiftyThree’s work with Neo4j, in both October 2013 and October 2014.
The two things I’ll cover in this blog post are actually very basic, and are: reading and writing queries.
When you really dive into the subtleties of both reading and writing, there is a lot that we may be taking for granted. For example, with reading, consistency is a very important aspect to your data, while with writing, atomicity is an important fundamental principle.
Reading
Below is what a typical Neo4j cluster setup might look like, drawn in Paper. (One of Paper’s features is essentially autocorrect for shapes — you can draw something that looks like a square and Paper will automatically format it for you):

In this standard cluster, you have a master and two slaves that communicate with each other. The recommended setup is to have a load balancer in front, such as HAProxy, that the clients talk to.
Instead of sending all the traffic to a single instance or arbitrarily load balancing the traffic, you can tap two separate pools, one of which will send requests to the master and one that will send requests to the slaves.
Because Neo4j is a master/slave setup, the typical recommendation for how you split these pools is reads versus writes. However, for a lot of applications (including ours), reads vastly outnumber writes, so being able to horizontally scale reads is very effective and valuable. We’ve learned that it actually works better for us to split traffic by the desired consistency, instead of by reads versus writes.
With Paper’s social layer, we have accounts that we persist in Neo4j. When we were splitting based on reads versus writes, we started seeing transient errors that couldn’t repro. One problem we encountered was that when someone created an account, they would automatically get logged out.
The cause came from our client app, which had code in place that would assume if any request failed for an authentication-related reason, either the password had changed or the account had been deleted. This was because the write request to create an account was being immediately followed by a read request which was doing auth lookup for that user. If that read request was going to a slave, that user may not have been synced right away.
We realized that right after a signup, we should actually send the very next read to the master to ensure that the new account is there and up to date. The same thing applies if you change your password, do a password reset or change your email address.
Another good example: if you follow a profile in Paper and then hit the close button, you’re back at your home stream. Paper will do a refresh of the home stream so you can start seeing that account’s content. Again, if a slave hasn’t gotten this newly created follow relationship and you do the home stream query on a slave, you won’t get that content.
Per-user read-after-write consistency
We arrived at this notion that we refer to as “Per-User Read-After-Write Consistency,” which means that if I just did a write, my immediately subsequent reads should be strongly consistent.
To achieve this, we tried tracking the last time stamp that you did a write and fetched that data as part of our auth lookup. This allowed us to see that if you recently did a write, even if this request is a read request, we should send the read request to the master for strong consistency.

The auth lookup should also be strongly consistent. Below is sample code where all our auth lookups are sent to the master. After that, if the queries are read requests, and we don’t need them to be strong consistency, we’ll send them to the slaves:

This means that all of our auth lookup reads are going to the master, which doesn’t horizontally scale. Because these auth lookups are very fast, simple queries, this hasn’t been an issue for us so far. If it does because an issue, we can offload our accounts from a master/slave system like Neo4j and move them to a horizontally-scaled system.
So, how recently did we do a write? Well, how do we define recently? What should the threshold be? This isn’t an easy question to answer, and what we’ve settled on boils down to slave lag: How far behind are the slaves relative to the master, and how long does it take them to catch up?
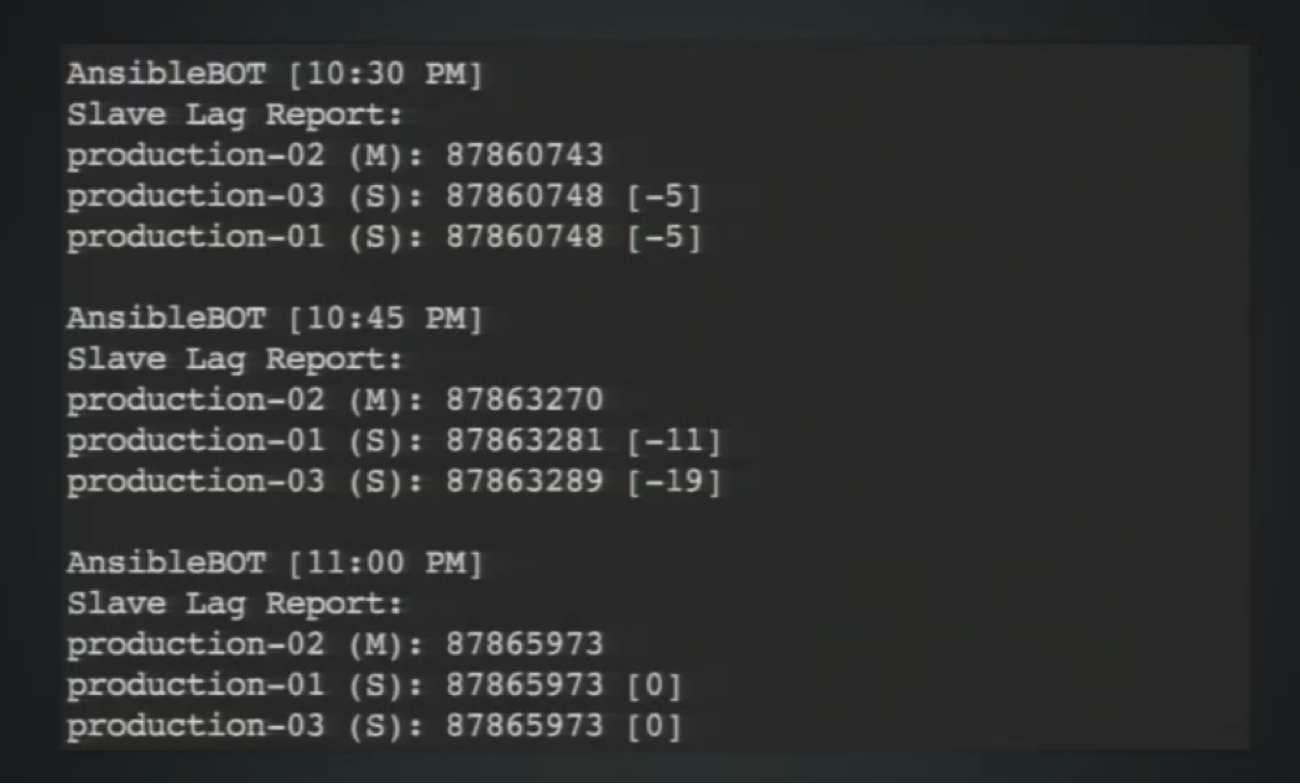
While it’s possible to monitor this stuff in Neo4j, it’s not necessarily easy, but the Neo4j development team is aware of that and working on it. We developed a tool that allows us to look at the last committed transaction in any instance and identify which instance is the master and which ones are the slaves. We sample that data every 15 minutes and today we see minimal slave lag relative to the raw rate of transactions going through the system.
Other major factors we monitor include the various HA configurations, pull interval and push factor and strategy.
Pictured below is the default snippet:

This isn’t necessarily the optimal snippet for you — it certainly wasn’t for us. It includes the pull interval, which refers to how often slaves are querying the master, which was initially set to 10 seconds; today we have it set to 500ms.
Given the 500ms amount and the subsequent lack of significant slave lag, we set our read-after-write consistency threshold at two seconds. This means for the next two seconds after you do a write, all your read queries will go to the master, which has so far been working well for us.
Per-user read-after-read consistency
Per-User Read-After-Read consistency is another more subtle consistency that can come into play.
When you have two or more slaves, if one read query goes to Slave A and your subsequent read query goes to Slave B and they’re not in sync, you might get a consistency flapping. In practice, this could express itself as a photo that exists for one second and then in the next second, it doesn’t exist.
Because the slave lag is so minimal, we haven’t seen this issue. However, if you do run into this problem, you can apply a database instance stickiness per user:

In the HAProxy configuration, you could have your app code send the user ID as the header and direct it to always route a particular value of this header (designated as the user ID) to the same slave.
Writing
As I mentioned above, Paper has social layers which allow users to follow other users:

To do this effectively, people need to be able to both follow and unfollow a user, and we need to cache some statistics to monitor performance. Just like Twitter will show you the number of followers and number of followings per user, the cache should be able to show that information without fetching the entire list manually.
To do the same thing in Paper, we cache both an “unfollowers” property and an “unfollowing” property per user. This means that I want to increment the write property every time I follow someone and decrement the write property when I unfollow someone.
Let’s look at an example, a very simple line of Cypher:

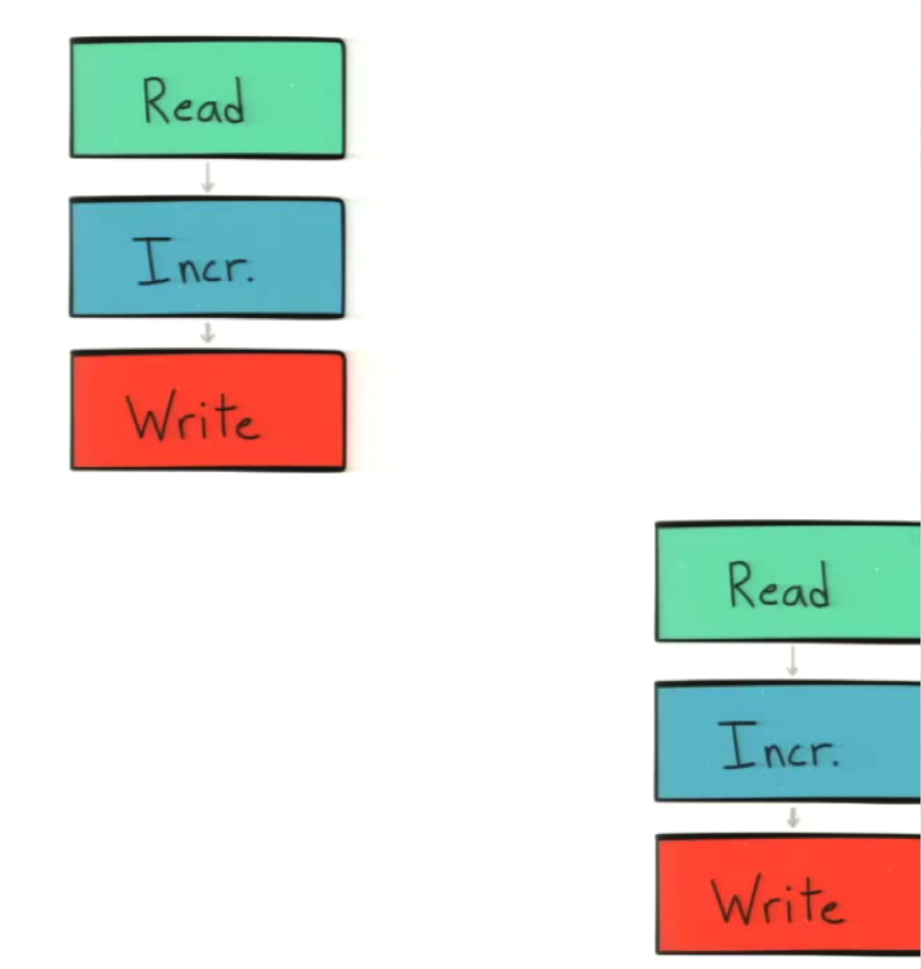
If you’ve ever done multithreaded programming in any coding language, you will recognize the classic C = C + 1 case. The reason it’s classic is because it’s a simple race condition in which you do a read before a write. It works fine if two parallel actors do the same call in sequence:
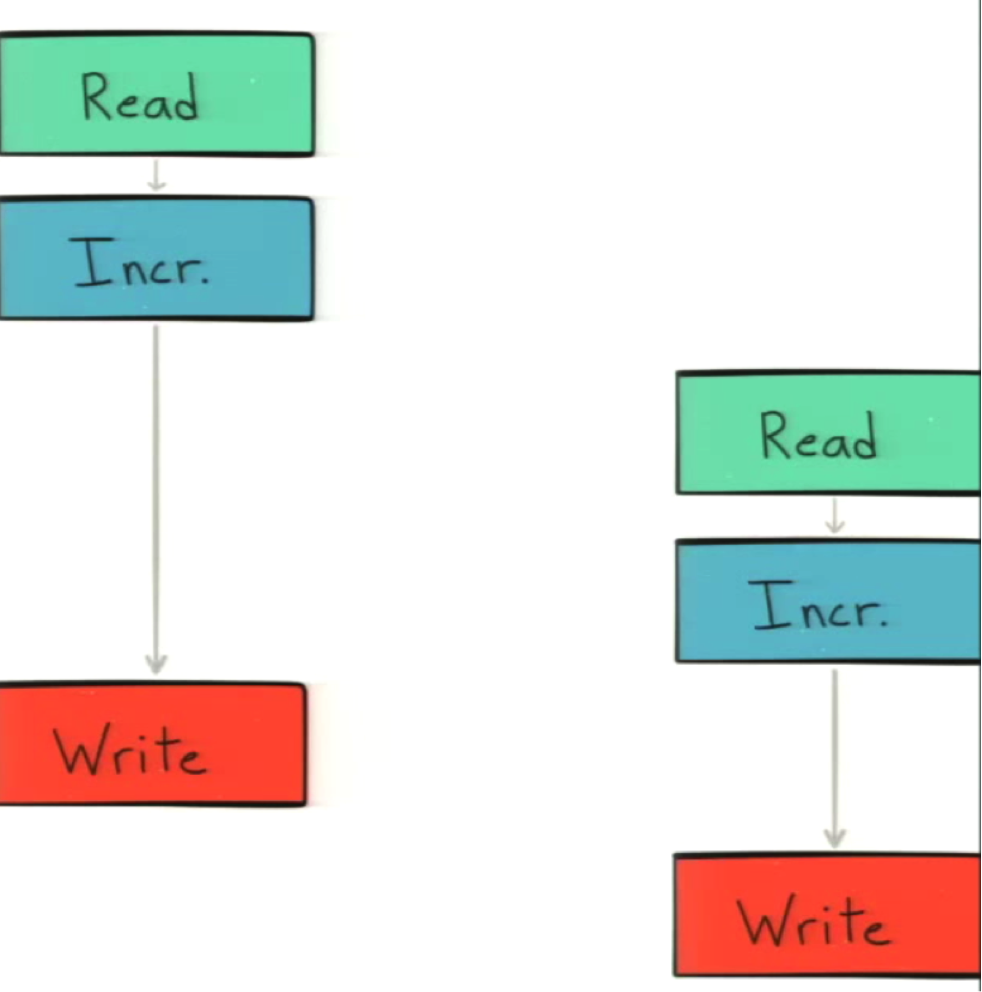
If the call doesn’t happen in sequence, then they’re going to both write the same value rather than building off of each other:
Neo4j uses a “read-committed isolation level,” which means that reads are not protected from concurrent modifications by other transactions. Only write locks are acquired and held until the end of the transaction.
In our previous read-increment-write flow, the whole series of steps is the transaction and a lock is only taken at that last step:

Because the locks are only held for the write, it doesn’t actually prevent the reads from happening out of order.
This is the default behavior because it offers significant performance advantages. However you can work around it to achieve higher levels of isolation, namely serialization, for your use case by manually acquiring write locks on nodes and relationships.
In the following example, we have removed the increment — which doesn’t change the semantic — and add a write before the read:
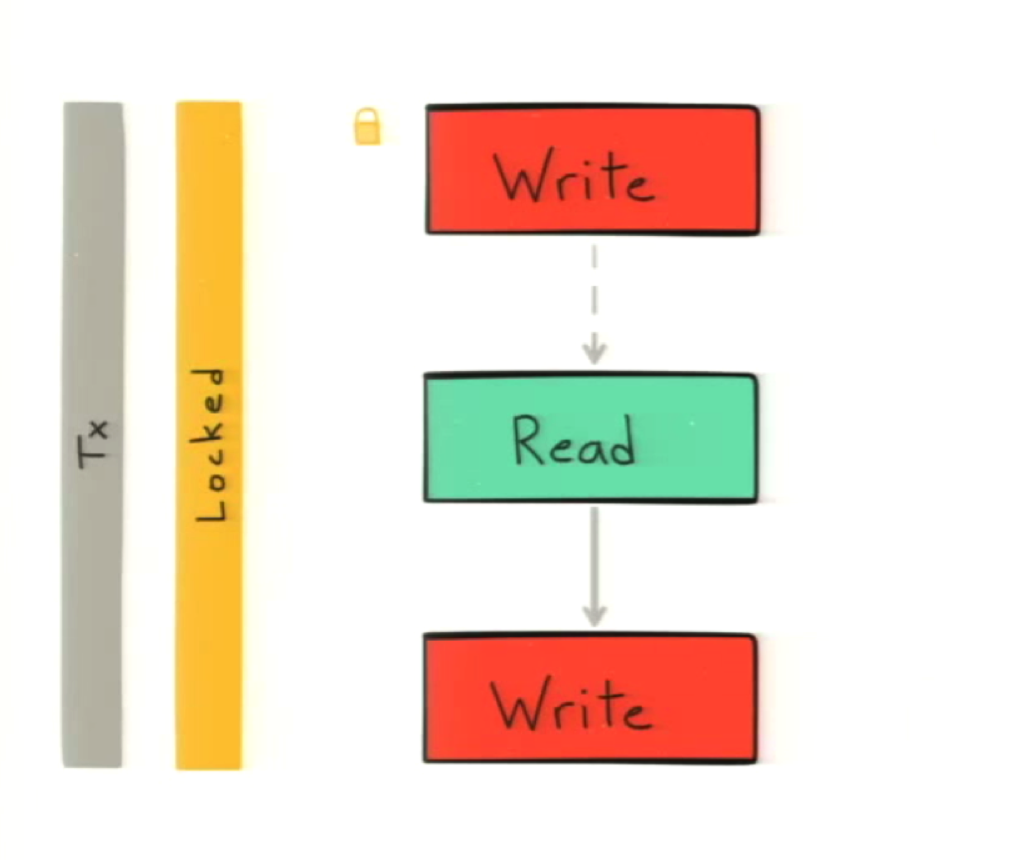
This allows us to acquire the desired write lock so that our entire transaction is serialized. Now, even if both transactions begin at the same time, only one will get the lock and the other will have to wait until the first transaction finishes.
This guarantees the serialization that you need to prevent a race condition:
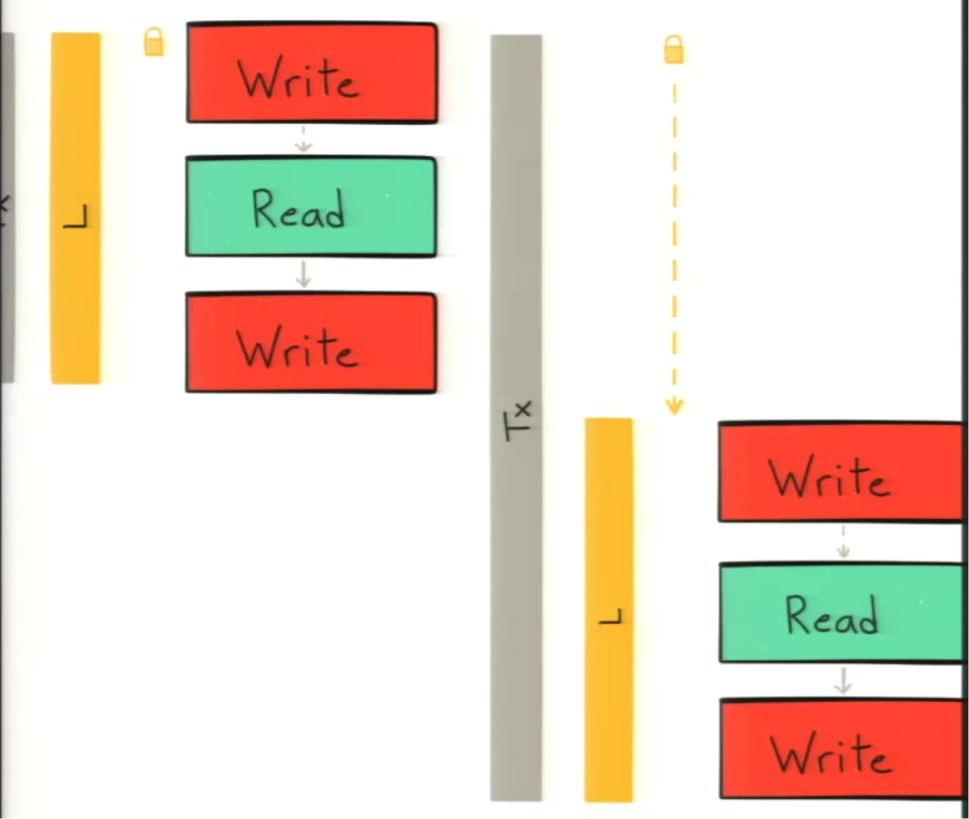
To do this in Cypher, keep the following points in mind: The lock is required at the node and/or relationship level. When modifying a property on a node or relationship — such as creating, deleting or changing the property — a lock is taken on the entity that the property belongs to.
If you want to acquire a lock on a node, you have to set a property — of any value — on that node. Below is the convention we use in our own Cypher queries:

This _lock probably doesn’t have any semantic, and the true doesn’t matter. But it’s the convention we use so we can see locking the same way in every query. If you write your query like this, you can take the write lock and prevent the race condition.
Consider the following example: In order to run this, we need a node. We use the following MATCH clause to get the user whose property we want to increment:

But what happens if there is a concurrent query that removes that user label? This is something that happens at Paper; we implement partial soft deletes to retain some history for our deleted nodes. We do this by changing labels — we swap out a user label for a deleted user label:
So what happens if the first MATCH query finds a user and then a second query swaps out that user label for a deleted label?

Now we’re going to execute our first query even though we don’t really want to.
To fix this, we use double-check blocking. This requires the verification of any read done prior to the write lock that could have changed. In this case, the part that could have changed for us is the user label, so we just verify that the user label still exists on this node before we do our write.

How does this work with relationships? Here’s a very common concept ensuring that you have IDE input in relationships. In our case, this means there should only be only one follows relationship from me to Alice, not two. And where this relationship doesn’t exist, you can create it:

It’s important to note that when you create and delete relationships, a lock is taken not just on the relationship but also at the start and end node. We therefore have to ensure that we aren’t susceptible to race conditions. In this case, the race condition would be that you think there’s no relationship between me and Alice but a concurrent second query adds one right after you start your query.
The simple way to prevent this is to take an explicit lock on both the start and end nodes to ensure that once we do our read to see whether a relationship exists, a relationship will not concurrently get added or deleted:

The good news is the merge keyword in Cypher does do this:

Unfortunately, because you typically don’t want to merge your entire pattern, MERGE is not a silver bullet. In the below example, I didn’t put the user labels in my MERGE clause because I don’t want to actually create users if Alice is just trying to follow Bob; I only want to merge the relationship:

I put the MATCH before the MERGE, which means we are doing some reads before I take any write locks. To solve this, we do the matches, take the write locks explicitly and then verify the matches:

In the Paper network, our system has a notion of blocking, just like Twitter or Facebook. In the following example, we want to verify that Alice hasn’t blocked me if I’m trying to follow her.

This check for blocks doesn’t belong in the MERGE and presents another race condition. You might think there aren’t any blocks relationships, but a second concurrent query creates one. Now my follows relationship is illegal or invalid.
The solution is the same as in prior examples:

While it’s not technically necessary to use two locks, we found it to be helpful because you prevent cases where two separate queries end up taking one lock that happens to be the same lock. For example, if you have one query working with Alice and Bob and another with Bob and Carol, it might take a lock on Alice and Carol which isn’t necessarily what you intended.
To prevent any issues that could arise from using more than one lock, Neo4j has deadlock detection built in, which will return an error mentioning ForsetiClient:

This is a typical error you might get if you’re trying to do concurrent operations in Neo4j in which it can’t execute either query because each is waiting on the other’s locks.
Notice that this error is Neo.transienterror.transaction.deadlockdetected. The transient error classification is really valuable. In every error that it returns, Neo4j classifies it as either a client error, meaning you have a bug; a database error, meaning Neo4j has a bug and you should report it; or a transient error, which means the query didn’t work this time but will likely work if you try it again.
To address this, we run our Cypher queries in a retry loop, meaning that if we receive a transient error, we’ll do some exponential backoff and retry the query. And once you get this retry architecture in place, you may notice a number of other places you want to implement the architecture as well:

But what if this single query is part of a larger transaction? If any of the queries return an error, the entire transaction will fail. And if that happens, you can’t retry one query; you have to retry the whole transaction.
The main place we use transactional queries is for complex deletes. Deleting a user is not something we can trivially express in a Cypher query because there is so much recursive business logic: the user has a number of shared IDs, they have followers, they are following other accounts, etc.
We can’t cram the business logic for deleting all those things into a single Cypher query, which means you have to wrap your code in something that’s transaction-aware and then run that code in a retry loop.
The below shows that we begin a transaction and then execute our code, queries and business logic and then retry the whole thing if there are any transient errors:

Keep in mind that if you’re in a polyglot persistence architecture and you have multiple data stores and writes, you need to make sure you roll back this other write before you retry the whole thing.
While the above examples were fairly simplistic, this all becomes much more complex in the real world. It’s harder to determine all the reads that inform rights, what parts of those reads can change, what locks you need to take and as you take all those locks, what kind of contention you need to be aware of.
The good news is there is a whole spectrum of tradeoffs. On one end, you can do simple queries without having to worry about the cautions listed above. On the other end of the spectrum, you could be as upfront and cautious as possible and your queries will get a little bit more complex and they’ll be a little bit harder to reason. But, there’s probably a good middle ground for you somewhere.
For Paper, that middle ground is that most of our queries by default don’t worry too much about this stuff. We abstract some of the key things like property increments and relationship checks into some helpers and that abstracts with that complexity pretty well. Then we just tackle the other stuff like the double-check blocking for label swaps only in the few cases where we’ve encountered those issues in practice.
Today, our system is running very smoothly. Our error rate is lower than it ever has been, and we don’t see any more of the occasional inconsistencies in our database that we had seen previously.
Closing
Consider the following closing lesson. Earlier we learned that locks are at the node and relationship level. Below is a typical data model:
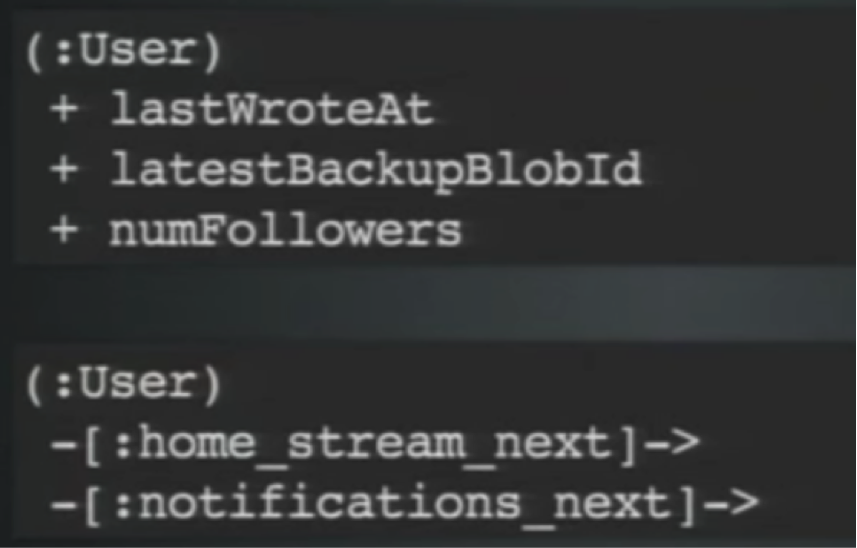
Over time, your database builds up in the amount and types of data that it’s storing. Consider all the things I mentioned earlier that could have a high-write throughput:
- Write tracking
- Latest backup
- Backup system
- Non-follower stats
- Link lists
All these things can have a high write over, particularly because most of them are affected by the actions of other people, not just you.
For example, if you follow 100 people, every time one of those people posts a new idea, it will show up in your home stream. The same is true anytime anyone stars one of your ideas.
Both times, you will get a notification. That’s going to change the head of your list, which is like deleting and creating a new relationship.
What we saw was that modifying a property takes a lock at the node level, while creating and deleting relationship takes a lock at both the relationship and node level. Instead of one monolithic node it may be better to have separate nodes that correspond to different concerns:
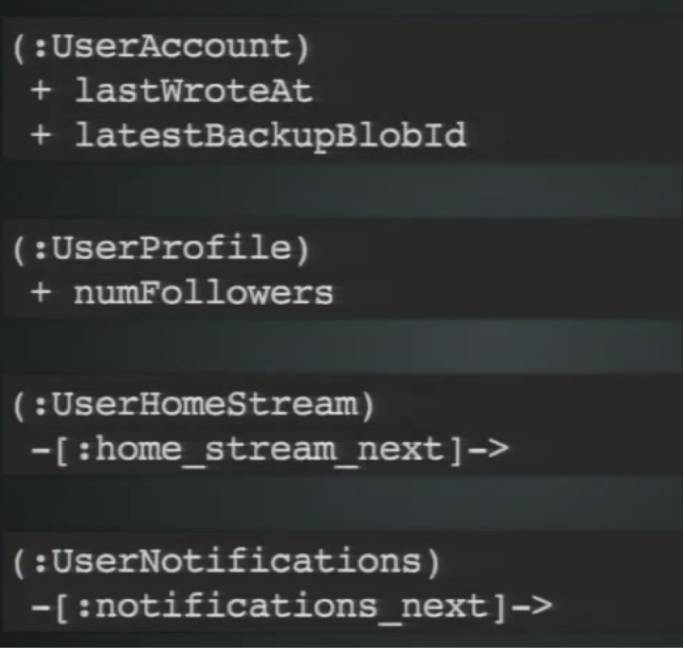
This allows you to have more granular write throughput.
The below are the most important takeaways from the above material:

Inspired by Aseem’s talk? Click below to check out the rest of the videos from GraphConnect Europe.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

