
Analyzing the Paradise Papers with Neo4j: A Closer Look at Queries, Data Models & More


6 min read

Our friends from the ICIJ (International Consortium of Investigative Journalists) just announced the Paradise Papers this past week, a new trove of leaked documents from the law firm Appleby and trust company Asiaciti.
Similar to the Panama Papers before (which we covered in-depth here), we’ve learned from those records that a large number of people and organizations use shell companies in tax havens and offshore jurisdictions to hide, move and spend huge amounts of money (billions to trillions of USD) without the necessary fiscal oversight.
In the last few days we saw a huge number of reports being published covering activities of companies like Nike, Apple, unsavory involvement by the Queen’s investment group, connections of Russian investments to politicians like Wilbur Ross or companies like Facebook and Twitter and many more.
The more than 13 million documents, emails and database records have been analysed using text analysis, full-text- and faceted-search and – most interesting to us – graph visualization and search.
From the Paradise Papers about section:
Special thanks go to the the Pulitzer Center on Crisis Reporting for supporting visual elements of the project, Neo4j and Linkurious for database support.
We are especially proud that Manuel Villa, whose position was sponsored by our “Connected Data Fellowship” was able to contribute to the research and data work.
As before, the leaked information was added to the already large body of data from previous leaks in a comprehensive Neo4j database that was available both to the data team as well as the investigative journalists.
The ICIJ published a fraction of the Paradise Papers data as part of their Power Players visualization at the same time as the reported stories. There are about 1000 nodes and 3000 relationships in this preliminary dataset.
We’re expecting the ICIJ to release larger parts of the dataset soon, and we will keep you updated with further findings.
Data Model
The data model the ICIJ used for the Panama Papers is quite straightforward. We’ve applied this same data model to the available Paradise Papers dataset. The model includes:
- A company, trust or fund created in a low-tax, offshore jurisdiction by an agent
(Entity) - People or companies who play a role in an offshore entity (
Officer) - Addresses (
Address) - Law-firms or middlemen (
Intermediary) that asks an offshore service provider to create an offshore firm for a client.
Each of these carries different properties, including name, address, country, status, start and end date, validity information and more.
Relationships between the elements capture the roles people or other companies play in the offshore entities (often shell companies), we see many officer_of relationships for directors, shareholders, beneficiaries, etc.
Other relationships capture similar addresses or the responsibility of creating a shell company by a law firm (intermediary_of).

Until the data is officially published we used the information from the ICIJ’s website for some examples on the reported stories.
Here is the full graph of (currently) independent reports that will come together in the full dataset:
This initial Neo4j graph database consists of information about 212 legal entities, 669 officers connected to those entities, which were established through 15 different intermediaries (often law firms used to incorporate the legal entities).
We can now use the data in Neo4j for interactive graph visualization, but also for full graph querying and later for the application graph algorithms (Part 2 of this blog series).
Basic statistics over the data tell us that we have these entities:
MATCH (n) RETURN labels(n), count(*) ORDER BY count(*) DESC
╒════════════════╤══════════╕ │"labels(n)" │"count(*)"│ ╞════════════════╪══════════╡ │["Officer"] │675 │ ├────────────────┼──────────┤ │["Entity"] │212 │ ├────────────────┼──────────┤ │["Address"] │134 │ ├────────────────┼──────────┤ │["Intermediary"]│15 │ ├────────────────┼──────────┤ │["Other"] │11 │ └────────────────┴──────────┘
The distribution of degrees for our entities shows a typical power law: there are some addresses which have 127 companies registered and some people who have almost 90 shell companies registered to their name.
Remember, this is a tiny fraction of the Paradise Papers data.
MATCH (n)
WITH labels(n) AS type, size( (n)--() ) AS degree
RETURN type,
max(degree) AS max, round(avg(degree)) AS avg, round(stdev(degree)) AS stdev
╒════════════════╤═════╤═════╤═══════╕ │"type" │"max"│"avg"│"stdev"│ ╞════════════════╪═════╪═════╪═══════╡ │["Other"] │14 │4 │4 │ ├────────────────┼─────┼─────┼───────┤ │["Address"] │127 │5 │15 │ ├────────────────┼─────┼─────┼───────┤ │["Intermediary"]│44 │10 │14 │ ├────────────────┼─────┼─────┼───────┤ │["Officer"] │89 │4 │8 │ ├────────────────┼─────┼─────┼───────┤ │["Entity"] │112 │12 │13 │ └────────────────┴─────┴─────┴───────┘
These are our relationships, so you see it’s mostly officers and addresses for entities and officers.
MATCH ()-[r]->() RETURN type(r), count(*) ORDER BY count(*) DESC
╒════════════════════╤══════════╕ │"type(r)" │"count(*)"│ ╞════════════════════╪══════════╡ │"officer_of" │2079 │ ├────────────────────┼──────────┤ │"registered_address"│639 │ ├────────────────────┼──────────┤ │"connected_to" │86 │ ├────────────────────┼──────────┤ │"intermediary_of" │67 │ ├────────────────────┼──────────┤ │"same_name_as" │28 │ ├────────────────────┼──────────┤ │"same_id_as" │2 │ └────────────────────┴──────────┘
We can break down the officer_of relationship by link property, then we see this:
MATCH ()-[r:officer_of]->() RETURN toLower(r.link), count(*) ORDER BY count(*) DESC LIMIT 10
╒═══════════════════════════╤══════════╕ │"toLower(r.link)" │"count(*)"│ ╞═══════════════════════════╪══════════╡ │"director" │661 │ ├───────────────────────────┼──────────┤ │"is shareholder of" │326 │ ├───────────────────────────┼──────────┤ │"alternate director" │238 │ ├───────────────────────────┼──────────┤ │"secretary" │209 │ ├───────────────────────────┼──────────┤ │"appleby assigned attorney"│102 │ ├───────────────────────────┼──────────┤ │"vice-president" │65 │ ├───────────────────────────┼──────────┤ │"auditor" │54 │ ├───────────────────────────┼──────────┤ │"president" │52 │ ├───────────────────────────┼──────────┤ │"ultimate beneficial owner"│48 │ ├───────────────────────────┼──────────┤ │"is signatory for" │41 │ └───────────────────────────┴──────────┘
What is interesting here, is the number of “appleby assigned attorneys” and “ultimate beneficial owner” which are not visible in the fiscal records.
Jurisdictions
This version of the dataset contains limited address information, but we can check to see the distribution of addresses across countries:
MATCH (n:Address) WHERE exists(n.country) RETURN n.country, count(*) ORDER BY count(*) DESC LIMIT 10
╒═══════════╤══════════╕ │"n.country"│"count(*)"│ ╞═══════════╪══════════╡ │"US" │23 │ ├───────────┼──────────┤ │"BM" │12 │ ├───────────┼──────────┤ │"BR" │7 │ ├───────────┼──────────┤ │"GB" │7 │ ├───────────┼──────────┤ │"IM" │6 │ ├───────────┼──────────┤ │"KY" │4 │ ├───────────┼──────────┤ │"ID" │4 │ ├───────────┼──────────┤ │"JO" │3 │ ├───────────┼──────────┤ │"HK" │3 │ ├───────────┼──────────┤ │"BS" │3 │ └───────────┴──────────┘
One important question we can ask is: What are the most popular offshore jurisdictions used by people in other countries?
For example, for people with addresses in the U.S., what are the most common offshore jurisdictions of Officer’s by country of address
// Most popular offshore jurisdictions for Officer's by country of address
MATCH (a:Address {country: "US"})--(o:Officer)--(e:Entity)
RETURN e.jurisdiction_description AS jurisdiction, COUNT(*) AS num
ORDER BY num DESC LIMIT 10
╒══════════════════════════╤═════╕ │"jurisdiction" │"num"│ ╞══════════════════════════╪═════╡ │"Bermuda" │94 │ ├──────────────────────────┼─────┤ │"Cayman Islands" │74 │ ├──────────────────────────┼─────┤ │"United States of America"│3 │ ├──────────────────────────┼─────┤ │"State of Delaware" │1 │ └──────────────────────────┴─────┘
We can see that the most common jurisdictions of entities with connections to people with addresses in the U.S. are Bermuda and the Cayman Islands, which also confirms common knowledge and the reason why so few Americans were in the Panama Papers, since Panama is not a common offshore jurisdiction for Americans.
Of course keep in mind that this is only querying a subset of the data. In our next blog post we’ll look at analyzing the full dataset.
Wilbur Ross
The current U.S. Secretary of Commerce, Wilbur Ross, was revealed to have connections to offshore companies, as reported by the ICIJ earlier last week.
// What are the jurisdictions of Ross's connected entities? MATCH (o:Officer)--(e:Entity) WHERE o.name CONTAINS "Ross" RETURN e.jurisdiction_description AS jurisdiction, COUNT(*) AS num ORDER BY num DESC
╒═══════════════════╤═════╕ │"jurisdiction" │"num"│ ╞═══════════════════╪═════╡ │"Cayman Islands" │16 │ ├───────────────────┼─────┤ │"State of Delaware"│1 │ └───────────────────┴─────┘
We see that Ross is connected to 17 legal entities, 16 of which are registered in the Cayman Islands:
// Wilbur Ross’s connections in the Paradise Papers MATCH (o:Officer)-->(e:Entity)-[:intermediary_of]-(i:Intermediary) WHERE o.name CONTAINS "Ross" MATCH (e)--(o2:Officer) RETURN *

We could write a similar Cypher statement to query for Ross’s second-degree network, without specifying node labels or relationship types:
MATCH p=(o:Officer)-[*..2]-() WHERE o.name CONTAINS "Ross" RETURN p
Queen Elizabeth Investment House
The Duchy of Lancaster – Queen Elizabeth II’s private estate and portfolio – appears in the Paradise Papers dataset. An investment of several million dollars was made in a Cayman entity, Dover Street VI Cayman Fund by the Duchy. While the Queen’s estate regularly reports some domestic investments and holdings, offshore holdings, including the Dover Street VI Cayman Fund investment had not been previously reported.
We can write a Cypher query for all two-degree connections to the Duchy:
MATCH p=(o:Officer {name: "The Duchy of Lancaster"})-[*..2]-()
RETURN p
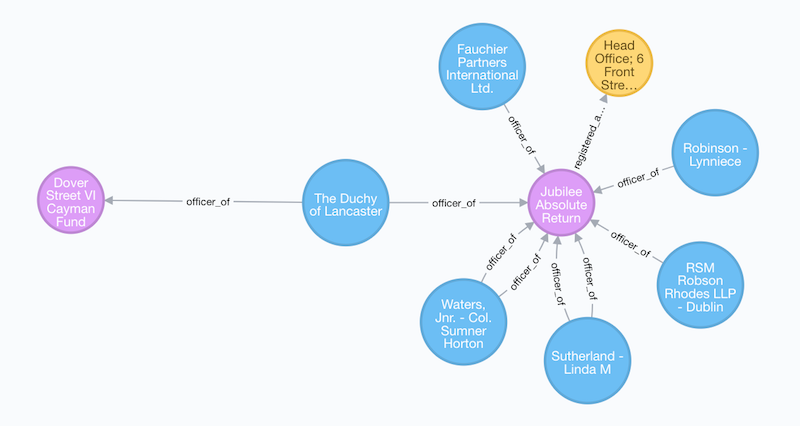
We can see a common pattern for the orchestration of offshore entities. If we expand two of the Officer nodes, “Robinson – Lynniece” and “Sutherland – Linda M” we see that they are serve as officers for many other offshore entities:
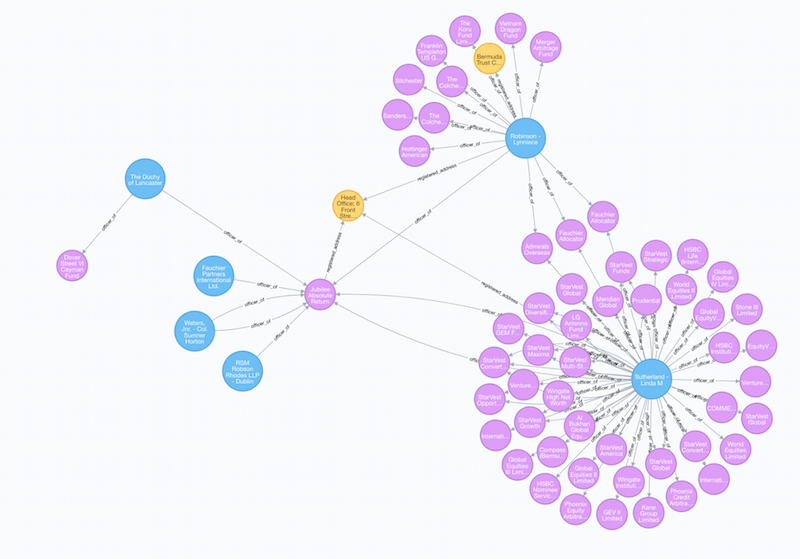
These individuals serve as corporate services managers, where they may serve as officers for hundreds of offshore entities.
Looking Ahead
This post was an introduction to the Paradise Papers dataset, with some examples from the recently published investigations.
In our next post, we will explore how we can apply graph algorithms, virtual graph projections, more advanced querying and spatial analysis to the entire Paradise Papers dataset.
References
Share Article



Explore
Related Articles

Mastering Fraud Detection With Temporal Graph Modeling

What Are the Different Types of Graph Algorithms & When to Use Them?


Top 10 Graph Database Use Cases (With Real-World Case Studies)

