


The Great Hookup: Announcing Neo4j Connector for Apache Spark


3 min read
We are thrilled to announce our latest tool, Neo4j Connector for Apache Spark. This connector is huge as it opens up the vast Apache Spark™ ecosystem to Neo4j.
Neo4j Connector for Apache Spark is an integration tool that moves and reshapes data bi-directionally between Neo4j and Apache Spark.
With this connector, Neo4j customers now have access to any data sources that are connected to the Spark ecosystem. Spark is the data orchestration tool of choice for most organizations, and also a powerful ETL tool.
Data scientists and developers who regularly need to manipulate data – data mashup and munging, extracting, consolidating, aggregating deduplicating, summing, etc. from Spark or other data sources (Oracle, Snowflake, Teradata, etc.) – can do so in Spark and then move it to Neo4j for graph processing.
For the Spark users out there that want advanced graph functionality, look no further: Neo4j offers a fully supported native graph database with rich data science tools.
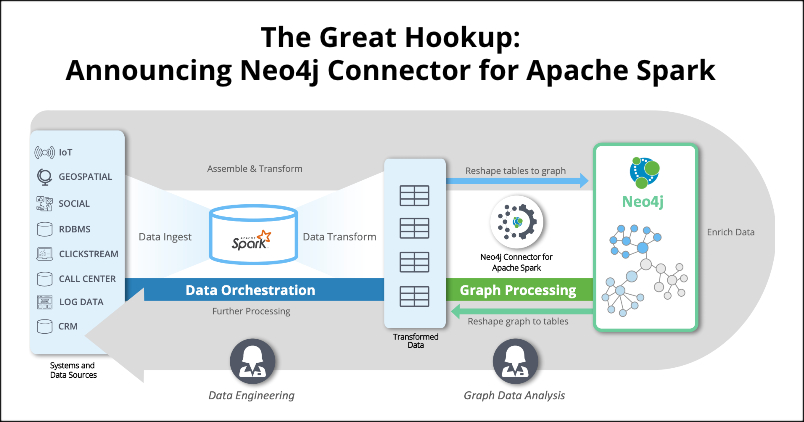
How the Connector Works
Apache Spark has a DataSource API that allows foreign systems to be plugged in easily. Simply put, this lets us implement Neo4j within Apache Spark just like any other source for DataFrame reads or target for writing them.
Reading millions of nodes out of Neo4j can be as simple as this:
spark.read.format("org.neo4j.spark.DataSource")
.option("url", "neo4j://my-cluster:7687")
.option("labels", "Person")
.load()
.show()
Under the covers, the connector uses Neo4j’s official Bolt driver for Java, so all the usual connection settings that you would use with any other graph application are the same – no changes.
The connector lets you work with three kinds of graph objects, in both directions (read and write):
- Nodes
- Relationships
- Queries
Sometimes, reading or writing data is as simple as working with a population of nodes, such as Person nodes in the example above. Other times, you need the full richness of the Cypher query language to express a graph pattern, and this will also work. You can perform path traversals or call special graph algorithms and quickly read the results back into Spark.
How You Can Use the Connector
If you’re already using Apache Spark, the connector is ideal for extraction, transformation and load (ETL) work with Neo4j and tying graphs into existing data engineering or machine learning (ML) pipelines.
Here’s a simple five-step workflow illustrating how to use Neo4j Connector for Apache Spark:
- Assemble and Transform
Select data from a data store (e.g., Oracle), clean and transform to tables in Spark. - Reshape Tables to Graphs
Write any DataFrame1 to Neo4j using Tables for Labels2. - Enrich Data
Derive graph value in Neo4j and reveal connections that enrich data. - Reshape Graphs to Tables
Read graph-enriched data from the Neo4j graph back to Spark using Labels for Tables2. - Further Processing
Loop insights derived from graph analytics back to the original data source (Oracle) to make a decision or to contribute to other workflow activities within Spark.
1DataFrame: terminology used by Spark to denote their table format.
2Tables for Labels, 2Labels for Tables: terminology used by Neo4j to denote conversion of graphs to tables and tables to graphs.
A huge thank you to our beta testing customers who helped us bring this product to market. We are excited to hear what new solutions you build by merging your Spark and graph data.
Try it out and let us know!
Share Article



Explore
Related Articles

Finding the Fastest Way Out: How Dijkstra’s Algorithm Finds Shortest Paths



Whose Signature Really Matters? Understanding PageRank Through Yearbook Signatures

From Cafeteria Cliques to Graph Communities: Understanding the Louvain Algorithm
