Apache Spark for Neo4j AuraDB

Senior Director of Developer Relations, Neo4j
6 min read
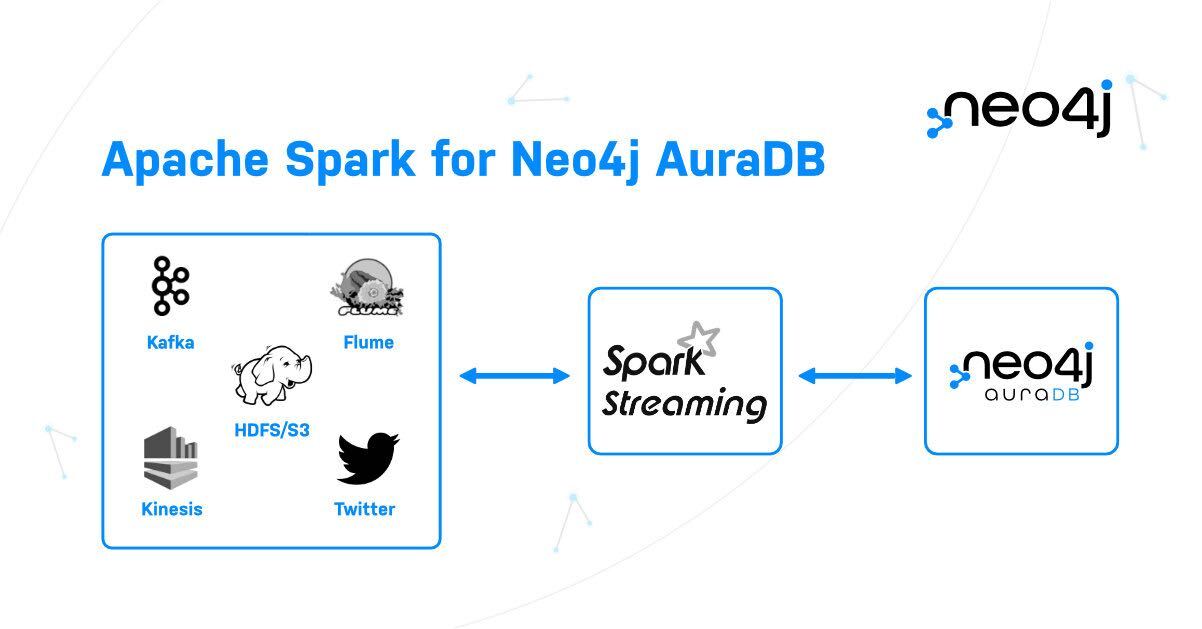
Neo4j recently released the Neo4j Connector for Apache Spark version 4.1, and in this post, I’d like to cover some of the important changes and new functionality. Today, we’re announcing the availability of streaming Spark support, both source and sink, which allows you to produce or consume data to and from Neo4j AuraDB, from any source you can connect to Spark.
These features are important to support the growing customer base using Neo4j AuraDB. We’re pleased to announce these and to make sure that customers know that everything described in this post works with Neo4j AuraDB Free, Enterprise, and Professional, but also with Neo4j Enterprise Edition (self-managed), and even Neo4j Community without limitations.
Streaming Spark support
With the existing Neo4j Connector for Apache Spark, we’ve worked with many customers who are using it for batch loading operations; moving data back and forth from systems like BigQuery, Snowflake, Azure Synapse, and others into the graph. This connector has unlocked the ability to engineer data pipelines together with things like Graph Data Science for some very powerful use cases.
But batch operations don’t work when you need to integrate with other streaming sources, such as AWS Kinesis, Google Pubsub, and others. Further, if you want to use AuraDB to feed such streaming and eventing pipelines, batches won’t do. This is where streaming support comes in.
Use cases
Bi-directional streaming with Spark unlocks some powerful use cases, which fall into several categories:
- Streaming ETL: Customers gather data continuously, clean and aggregate it, and push it into the Neo4j Aura knowledge graph – this permits anomaly behavior to be detected in near real-time, triggering other actions.
- Data enrichment: Adding value to a graph with Cypher, Spark streaming can enrich live data and connect it to other static datasets.
- Trigger Event Detection: Spark Streaming allows customers to detect and respond quickly to rare or unusual behaviors (“trigger events”) that could indicate a potentially serious problem within the system. Financial institutions use triggers to detect fraudulent transactions and stop fraud; manufacturing systems might send automatic alerts to the right teams who can maintain equipment and take immediate action to prevent outages.
- Machine learning: For ML workflows implemented in or with Spark, streaming data changes from a knowledge graph may help with deployment of online prediction models.
Because streaming works in both directions, we can use Spark streaming support to add graph capabilities to any streaming dataflow. Pipe the data into Neo4j, add value to it using Cypher and other approaches, and then get it where it needs to go quickly.
How it works
The Neo4j Connector for Apache Spark simply reuses the spark streaming API, creating a situation where Neo4j behaves just like any other streaming source. If you have experience with connector by reading/writing data from/to Neo4j with the “batch” API, you can also leverage the Structured Streaming feature by leveraging your previous experience – you just need to add few more options (for instance, if you want to start reading the streaming from the beginning or from NOW). Let’s take a look at some simple code examples. These are in Scala, but the same concepts work with Python and R too, thanks to polyglot support.
Writing to Neo4j
As the simplest example, let’s say we had a stream of data coming representing attendee / event check-in events, from AWS Kinesis like so:
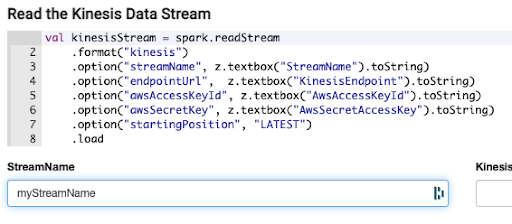
The same data could be streamed into the Neo4j graph with the following code:
val kinesisQuery = kinesisStream
.writeStream
.format("org.neo4j.spark.DataSource")
// Neo4j Aura connection options
.option("url", "neo4j+s://abcd.databases.neo4j.io")
.option("authentication.type", "basic")
.option("authentication.basic.username", "neo4j")
.option("authentication.basic.password", "password")
.option("checkpointLocation", "/tmp/kinesis2Neo4jCheckpoint")
// end connection options
.option("save.mode", "Append")
.option("relationship", "CHECKED_IN")
.option("relationship.save.strategy", "keys")
.option("relationship.properties", "user_checkin_time:at")
.option("relationship.source.labels", ":Attendee")
.option("relationship.source.save.mode", "Overwrite")
.option("relationship.source.node.keys", "user_name:name")
.option("relationship.target.labels", ":Event")
.option("relationship.target.save.mode", "Overwrite")
.option("relationship.target.node.keys", "event_name:name")
.start()
Most of the options specified here follow the existing patterns of the connector; it allows us to specify that we’re writing relationships for example, that go from the :Attendee label to the :Event label, creating a CHECKED_IN relationship.
Full information on this particular example above can be found in Davide Fantuzzi’s excellent article on integrating AWS Kinesis with Neo4j.
Reading from Neo4j
To show data flowing in the other direction, let’s look at a simple example of reading all of the :Person labels from our graph, and producing them into a Spark stream. This time, we’ll provide a simple example in Python, since due to polyglot support in Spark, the connector works with both.
graph_stream = (
spark.readStream
.format("org.neo4j.spark.DataSource")
.option("authentication.type", "basic")
.option("url", url)
.option("authentication.basic.username", user)
.option("authentication.basic.password", password)
.option("streaming.property.name", "lastUpdated")
.option("streaming.from", "ALL")
.option("labels", "Person")
.load()
)
query = (graph_stream.writeStream
.format("memory")
.queryName("testReadStream")
.start())
spark.sql("select * from testReadStream").show(1000, False)
In this example, we simply construct a stream, start a query over that stream, put the resulting data into a temporary in-memory table called “testReadStream,” and then query it to see which data is coming back. Rather than reading just a single label, we could do the same with relationships, or any Cypher query.
Where to get more information
The best place to find out more about this release is via the official documentation, which you can find here. You can also drop by the Neo4j Community site to ask questions, or get in touch directly with your Neo4j representative.
If you aren’t already an Aura Free user, you should also definitely drop by Neo4j Aura and sign up for a free AuraDB database, where you can give it a shot, and even use it for Spark development testing on small datasets.
Conclusion
If you are a Neo4j Aura customer, this release is great news. We’ve made bi-directional integration with Spark streaming possible. You can get started today, whether you’re using Aura Free, Professional, or Enterprise. If you are running Neo4j Enterprise Edition, you can do exactly the same.
The approaches we’re describing here work with most modern versions of Apache Spark >= 2.4.5, and also work with Spark 3. If you’re using a cloud managed version of Spark, such as Google Dataproc, AWS EMR, Databricks, or other, runtimes are available, which will work.
We’ve already seen customers build a variety of really cool applications using Neo4j Aura and Apache Spark together, and we can’t wait to see what you will build next.
Share Article



Explore
Related Articles
Introducing Document Intelligence: From documents to a knowledge graph, right inside Aura

Getting started with Neo4j Aura: A guide to the leading cloud graph database

Finding hidden bottlenecks in flight networks with Aura graph analytics on Databricks

Find impactful graph-powered insights in Databricks

