APOC Release for Neo4j 3.4 with Graph Grouping

Head of Product Innovation & Developer Strategy, Neo4j
4 min read

Just in time for the Neo4j 3.4.0 release, we also pushed out two versions of APOC – 3.3.0.3 and 3.4.0.1.
You can download them from GitHub, Maven or most conveniently with a single click in Neo4j Desktop.
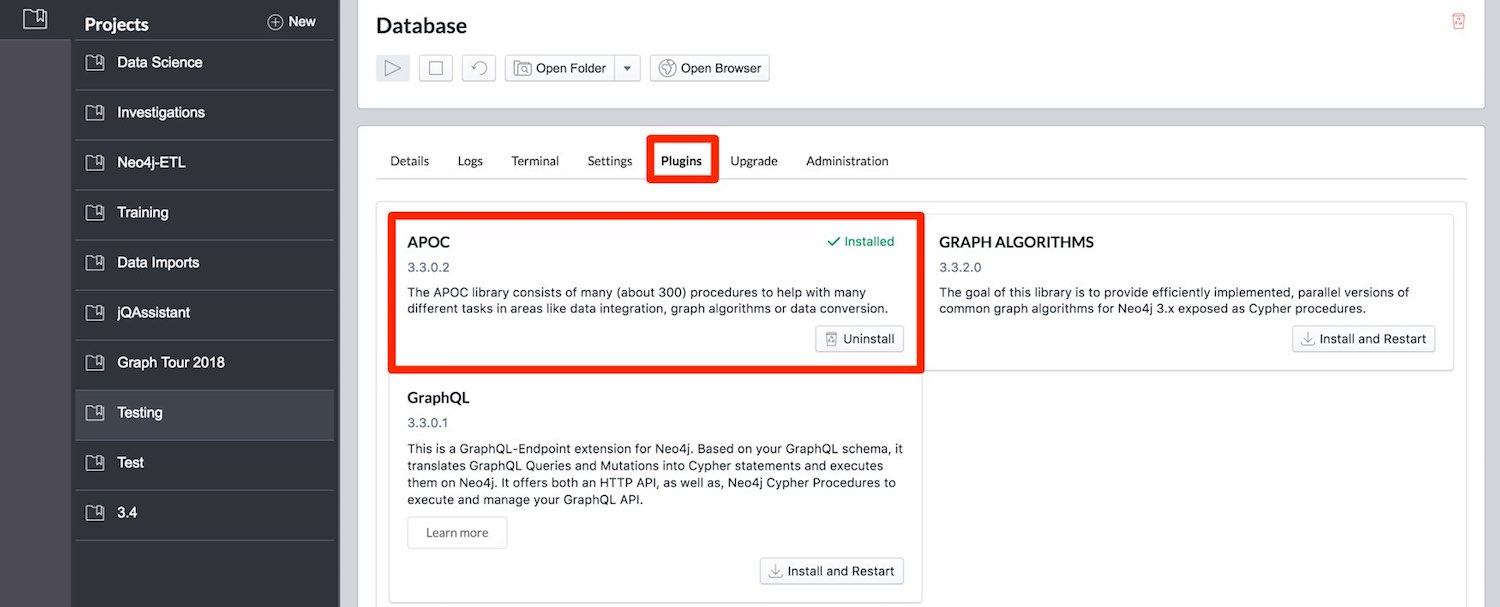
Please note that the “self-upgrade” process in Neo4j Desktop might leave the previous APOC version in your plugins directory, so you’ll have to remove it yourself if your DB fails to restart after upgrading.
|
This time, we had to spend much more effort on updating the internals, as Neo4j 3.4 comes with a new SPI (Kernel API) for more efficient interaction with the Cypher runtime.
As APOC uses that SPI in a number of places, we can thank Stefan Armbruster who took on the job of updating all of those.
I also want to thank everyone who contributed or reported back issues or feature requests.
Although this is release is lighter on features, there are two things that made it in that I hope will make all your lives easier.
Load Excel (XLS)
Much of business data is still living in Excel spreadsheets today, because quick computation, summariziation, charts and formatting are very handy.
And as I learned a long time ago from Simon Peyton Jones, Excel’s expression language is the most widely used, immutable functional language in the world.
One other feature that is very useful is to group data that belongs together into several sheets of the same file.
The main difference between apoc.load.xls and apoc.load.csv is that you can address individual sheets or even regions.
We use the Apache POI library to read Excel, but as I didn’t want to grow APOC by many megabytes, you’ll have to add these dependencies yourself if you want to use Excel loading.
They are linked in the documentation for both procedures.
Those two also come with a number of other cool features like:
- Provide a line number
- Provide both a map and a list representation of each line
- Automatic data conversion (including split into arrays)
- Option to keep the original string formatted values
- Ignoring fields (makes it easier to assign a full line as properties)
- Headerless files
- Replacing certain values with
null
So if you have a sheet like this (below), you cannot just access the individual Sheets, but also a region as shown here.
The name of the sheet is Offset so don’t get confused 🙂

CALL apoc.load.xls('file:///path/to/file.xls','Offset!B2:F3',
{mapping:{Integer:{type:'int'}, Array:{type:'int',array:true,arraySep:';'}}})
Resulting in:
| String | Boolean | Integer | Float | Array |
|---|---|---|---|---|
|
|
|
|
|
|
Graph Grouping
The other feature that I’m really happy about is graph grouping.
Quite some time ago, Martin Junghanns told me about the graph operators in Gradoop, one of which is graph grouping.
I found this concept to be a really cool and useful idea, and I implemented a first version in APOC a while ago.
- This is a way of summarizing a graph by grouping nodes by one or more properties, resulting in virtual nodes that represent these groups.
- Then for each of the virtual nodes, all of the relationships between each group are aggregated too.
- And you can provide additional aggregation functions for both nodes and relationships besides just counting them (e.g., sum of values or min/max of timestamps, that also turn into properties of the aggregated graph entities).
The documentation for this procedure also details all the command line and configuration options, such as skipping orphans or post-filtering the results.
Here is a quick example:
CALL apoc.nodes.group(['User'],['country','gender']) YIELD node, relationship RETURN *;

This is especially helpful to get a bird’s eye view of the graph, such as a summarization.
So for example, you can group a User graph by country and gender or a citation-graph by publication year.
As Martin and Max had built a nice JavaScript application demoing that feature, I took it and adapted it to use a Neo4j / APOC backend.
Find the adapted source code in this GitHub repository. It is self-contained and even hosts a running app.

As part of this I also added a number of functions to access node and relationship attributes that also work with virtual nodes and relationships.
Going forward, I want to make it run on graph projections and also improve performance further.
Release Summary
Features/Improvements
-
apoc.load.xlsfor loading data from Excel files, supports both.xlsand.xlsx -
Improvements for
apoc.nodes.group, e.g., filtering of rel-types or of outputs by counts -
Accessor functions for (virtual) entities (e.g., to postfilter them by property or label)
-
Dijkstra algorithm supporting multiple results
-
date.format(null)returns null, also add ISO8601 convenience format
Bugfixes
-
Fix for
apoc.periodic.iteratewith statements that already started withWITH -
Fix for deleted nodes in an explicit index
-
apoc.cypher.runTimeboxeduses separate thread -
Missing Iterator Utils in APOC
.jarfile -
Add missing
apoc.coll.combinations() -
Check for availability before running sync index update thread
Documentation
-
Docs for
apoc.load.csvandapoc.load.xls -
Docs for
apoc.group.nodes -
Docs for
apoc.coll.contains
So please go ahead and try out the new features and update your APOC dependency to the latest version.
You should also make it a habit to learn one new APOC procedure or function each day. There more than are enough for every day of the year 🙂
Start with CALL apoc.help('keyword') to not get lost anymore.
Cheers,
Michael
Share Article



Explore
Related Articles
New research finds enterprises earn 230% ROI with Neo4j Graph Intelligence Platform
What’s invisible in your supply chain could cost you

APRA Just Put the Financial Sector on Notice Over AI. Government Agencies Need to Take Notes.

Turning ServiceNow data into connected enterprise intelligence