
Summer 2017 Release of the APOC Procedures Library

Head of Product Innovation & Developer Strategy, Neo4j
5 min read
It’s summertime, but that doesn’t mean we’re less active building cool stuff for you to use with Neo4j.
If you haven’t heard of APOC yet – dubbed “Awesome Procedures On Cypher” – it’s a Swiss Army knife of useful utilities that make your life with Neo4j much easier. Besides the documentation, there are a number of past articles, that introduce relevant parts of the APOC library.
After about three months with almost 50 new features and fixes to APOC after our Spring release we’re happy to announce two new APOC releases for Neo4j 3.1 and 3.2.
Thank You!
Of course my thanks goes to the people contributing to APOC, foremost Alberto, Angelo, Daniele, Omar, and Lorenzo from LARUS in Italy who did most of the work.
Ron van Weverwijk from GoDataDriven added very useful text comparison features, Brad Nussbaum from AtomRain contributed improvements in load-jdbc and Stefan Armbruster added new merge procedures.
Valentino Maiorca provided new hashing functions, Max de Marzi built a way of quickly counting the number of different entries for an indexed property, and Andrew Bowman added functions for sorting map-keys.
Highlights of the APOC Release
There are lots of improvements in the Cypher export procedures, which now support neo4j-shell, cypher-shell and plain formats as well as exporting to separate files or exporting only the constraints. Accordingly, apoc.cypher.runFile and apoc.cypher.runSchemaFile can now consume multiple files.
Three new procedures give you a more detailed output of schema indexes and constraints, as well as apoc.meta.schema for a nested schema listing of nodes and relationships.
CALL apoc.meta.schema();
// output similar to
"Person": {
"type": "node",
"count": "131",
"labels": [],
"properties": {
"name": {"type": "STRING","indexed": true,"unique": true},
"born": {"type": "INTEGER","indexed": true,"unique": false},
},
"relationships": {
"ACTED_IN": {
"direction": "out",
"count": "797",
"labels": ["Movie"],
"properties": {
"roles": {"type": "UNKNOWN","array": true,"existence": false}
}
},
"PRODUCED": {"direction": "out","count": "27","labels": ["Movie"],"properties": {}},
"DIRECTED": {"direction": "out","count": "49","labels": ["Movie"],"properties": {}},
"WROTE": {"direction": "out","count": "12","labels": ["Movie"],"properties": {}}
}
},
There are now procedures to merge nodes and relationships with dynamic labels, relationship-types and properties. (apoc.merge.node/relationship)
CALL apoc.merge.node(['Label'], {id:uniqueValue}, {prop:value,...}) YIELD node;
CALL apoc.merge.relationship(startNode, 'RELTYPE', {[id:uniqueValue]}, {prop:value}, endNode) YIELD rel;
There are also functions for working with large decimal numbers, e.g., for finance applications. You can find them in apoc.number.exact.*
RETURN apoc.number.exact.mul(toString(2^64),"2")
36893488147419104000
RETURN 0.98 - 0.9 as default, apoc.number.exact.sub('0.98','0.9') as exact
╒═══════════════════╤═══════╕
│"default" │"exact"│
╞═══════════════════╪═══════╡
│0.07999999999999996│"0.08" │
└───────────────────┴───────┘
Something that people struggle with in Neo4j are atomic operations on properties of nodes and relationships, that’s why we added procedures to APOC that eagerly take write-locks and retry in case of deadlocks for property updates.
Those functions are located in the apoc.atomic.* namespace.
CREATE (n:Foo {counter:0,owners:[], ownerCount:0});
MATCH (n:Foo)
CALL apoc.atomic.add(n,"counter",1) YIELD newValue AS counter
CALL apoc.atomic.insert(n,"owners",0,"bar") YIELD newValue AS owners
CALL apoc.atomic.update(n,"ownerCount","length(n.owners)") YIELD newValue AS ownerCount
RETURN n, owners, counter, ownerCount
╒════════════════════════════════════════════════════╤══════════════╤═════════╤════════════╕
│"n" │"owners" │"counter"│"ownerCount"│
╞════════════════════════════════════════════════════╪══════════════╪═════════╪════════════╡
│{"ownerCount":2,"owners":["foo","bar"],"counter":2} │["foo","bar"] │2 │2 │
└────────────────────────────────────────────────────┴──────────────┴─────────┴────────────┘
A new function apoc.map.updateTree allows you to update tree structures based on matching keys.
apoc.map.updateTree(treeMap, key, updateList)
RETURN apoc.map.updateTree(
{name:"Michael",kids:[{name:"Rana"},{name:"Selma"},{name:"Selina"}]},
'name',
[['Michael',{born:1975}],["Selina",{born:1998}],["Rana",{born:2005}],["Selma",{born:2008}]])
{"name":"Michael",
"born":1975,
"kids":[
{"name":"Rana","born":2005},
{"name":"Selma","born":2008},
{"name":"Selina","born":1998}]
}
There are now apoc.update.jdbc procedures for doing updates in relational databases.
CALL apoc.load.jdbcUpdate(jdbc-url,statement, params) YIELD row;
MATCH (u:User)-[:BOUGHT]->(p:Product)<-[:BOUGHT]-(o:User)-[:BOUGHT]->(reco)
WHERE u <> o AND NOT (u)-[:BOUGHT]->(reco)
WITH u, reco, count(*) as score
WHERE score > 1000
CALL apoc.load.jdbcUpdate('jdbc:mysql:....',
'INSERT INTO RECOMMENDATIONS values(?,?,?)',[user.id, reco.id, score]) YIELD row;
A new apoc.nodes.connected function can be used as efficient connection test of dense nodes and non-dense nodes.
Relationships can be now merged as a new graph refactoring, and you can control via configuration what happens to the properties.
// merge relationships onto first in list
CALL apoc.refactor.mergeRelationships([rel1,rel2,..., relN], {config}) YIELD rel
Similar to the json-path in the json functions and procedures, you can now use XPath to access a subset of a XML document in apoc.load.xml.
CALL apoc.load.xml('books.xml', '/catalog/book[@id="bk102"]/author') YIELD value
WITH value._text as author
RETURN author
New text comparison functions provide fuzzy matching and Levenshtein distance for strings, which is really useful for data matching and merging.
RETURN apoc.text.distance('Berlin','Bärlin'); // -> 1
RETURN apoc.text.distance('Neo4j','neoj4'); // -> 3
RETURN apoc.text.fuzzyMatch('Cypher','Ciper'); // true
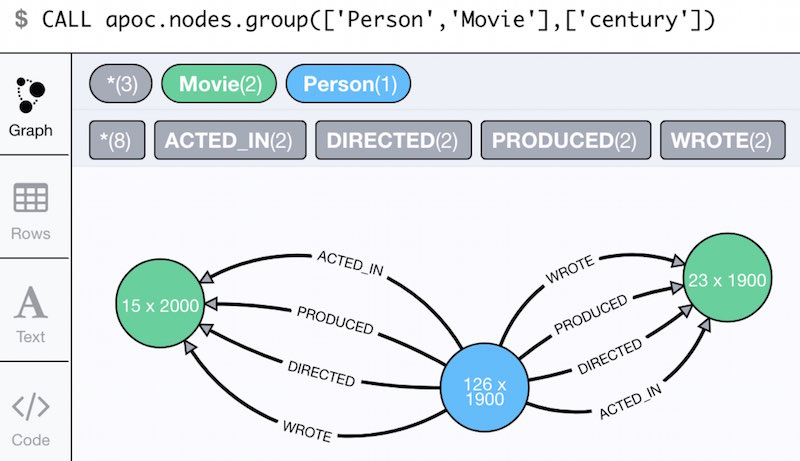
A new feature that I learned about from Martin Junghanns is graph grouping.You can take an existing graph and group it into a virtual graph by node labels and properties to get an overview.
The procedure currently only aggregates nodes and relationships by with counts, so you can set the caption in your Neo4j Browser to caption: "{count} x {property}";
Going forward, I want to make it more versatile and efficient.
Here, I group the movies and actors of the movie graph by the century they’re released or born in.
MATCH (n:Movie) SET n.century = n.released/100*100 return count(*) UNION MATCH (n:Person) SET n.century = n.born/100*100 return count(*); CALL apoc.nodes.group(['Person','Movie'],['century']);
Bugfixes
warmuphad a bug that made it fail with graphs with more than two billion nodes or relationshipsPeriodic.iterateshould now better report nested errors- Improved error messages for missing database drivers
- Dropping the existing schema in
schema.assertis now optional - Faster turnaround in parallelization
apoc.convert.toMapnow also works for nodes and relationships
We got fixes and improvements for code and documentation from Gábor Szárnyas, Chris Willemsen, John Bodley, Elad Wiess and Nicholas Schiestel. Thank you!
Installation
As usual, you can grab the latest APOC releases from here.
Then just drop the jar-file into your $NEO4J_HOME/plugins directory (note the instructions for different install locations for Neo4j-Community in the readme) and restart your server.
You find more details on the new procedures and functions in the documentation or via call apoc.help('keyword')
Feedback
And of course APOC cannot improve if you don’t provide your feedback, so please let us know if you like it and find it useful (especially on Twitter).
If you find any issues or have ideas for improvements don’t hesitate to send us issues.
Of course the best thing is to get a pull request with a bug fix or improvement, so don’t be afraid and give it a try.
Have fun connecting and have a great summer,
Cheers,
Michael
Show off your graph database skills to the community and potential employers with the official Neo4j Certification. Click below to get started and you could be done in less than an hour.
Share Article



Explore
Related Articles





How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs
