
How Backstory.io Uses Neo4j to Graph the News [Community Post]

Software Engineer
5 min read
[As community content, this post reflects the views and opinions of the particular author and does not necessarily reflect the official stance of Neo4j.]
Backstory is a news exploration website I co-created with my friend Devin.
The site automatically organizes news from hundreds of sources into rich, interconnected timelines. Our goal is to empower people to consume news in a more informative and open-ended way.
The News Graph
Our ability to present and analyze news in interesting ways is based on an extensive and ever-growing “news graph” powered by Neo4j.
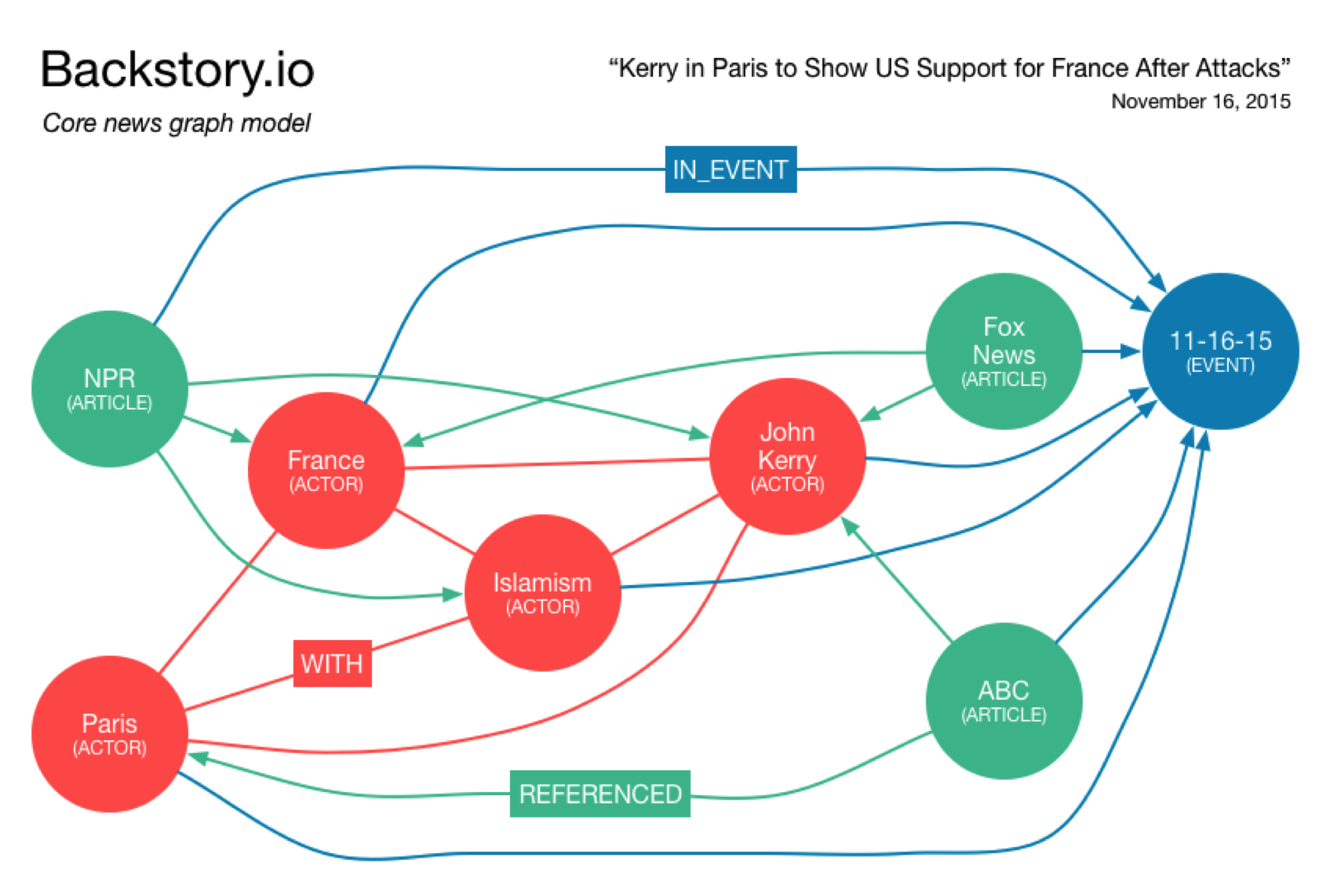
The core graph model is shown in simplified form below:

Consider three articles published by different news sources on November 16th, 2015.
First, Backstory collects these articles and stores them as ARTICLE nodes in the graph.
Second, article text is analyzed for named entities, stored as ACTOR nodes. Articles have a REFERENCED relationship with their actors.
Thirdly, these articles are clustered because they’re about the same thing: U.S. Secretary of State John Kerry visiting France after the terrorist attacks in Paris. The article cluster is represented by an EVENT node. All articles and actors in a cluster point to their news event with an IN_EVENT relationship.
Finally, all actors in the cluster point to one another using a dated WITH relationship, to record their co-occurrence.
Given enough data, this model allows us to answer interesting questions about the news with simple Cypher queries. For example:
What are the most recent news events involving John Kerry?
MATCH (:ACTOR {name: "John Kerry"})-[:IN_EVENT]-(e:EVENT) RETURN e ORDER BY e.date DESC LIMIT 10
When was the last time Islamism interacted with Paris?
MATCH (:ACTOR {name: "Islamism"})-[w:WITH]-(:ACTOR {name: "Paris"}) RETURN w.date ORDER BY w.date DESC LIMIT 1
How many news events involving France occurred this week?
MATCH (:ACTOR {name: "France"})-[:IN_EVENT]-(e:EVENT) WHERE e.date > 1447215879786 RETURN count(e) AS event_count
In addition to the information present in the news graph itself, we tap into a large amount of enriched data by virtue of correlating all actor nodes to Wikipedia entries.
For example, by including a field about the type of thing an actor is, a query can now differentiate a person from a place. Cypher has risen to the challenge and continues to allow for concise queries over a complexifying graph.
Neo4j For The Win
We are big Neo4j fans at Backstory. The graph technology and community has propelled us forward in many ways.
Here are just a few examples:
There Are Ample Neo4j Clients across Languages
In the Backstory system architecture – described in more detail here – there are a variety of components that read from and write to the graph database.
A combination of requirements and personal taste have led us to write these components in different languages, and we are pleased with the variety of options available for talking to Neo4j.
On the write-side, we use the the Neo4j Java REST Bindings. This component also uses a custom testing framework that allows us to run suites of integration tests against isolated, transient Neo4j embedded instances.
On the read-side, we’ve created an HTTP API that has codified the queries the Backstory.io website makes. This is written in Python and uses py2neo.
There’s also an ExpressJS API for administrative purposes, which constructs custom Cypher queries and manages its own transactions with Neo4j.
The Neo4j Browser Is a Crucial Experimentation Tool
The Neo4j Browser is an excellent tool for anything from experimenting with new Cypher queries to running some sanity checks on your production data.
Every Cypher-based feature I’ve developed for Backstory was conceived and hardened in the Browser. I even used it to develop the example queries above!
Graph Flexibility Is Underrated
Early on in our design process for Backstory we were a bit skeptical of using a graph database. Was it really worth leaving the comfort zone of relational databases or key-value stores?
Even after we had committed to a Neo4j prototype, we expected to end up requiring secondary relational storage for any number of requirements outside of the core news graph.
It turns out Neo4j has sufficed for all of our persistent data requirements, and has even led us to novel solutions in several cases. Four quick examples:
- Ability to latently add indexes
- Using Neo4j as an article queue
- Using the graph to cluster articles
- Using Neo4j for Named Entity recognition
The Backstory model has evolved substantially over time. New node and relationship types come and go, and properties are added that need to be queried. Neo4j’s support for adding indexes to an existing graph have allowed us to keep queries performant as things change.
When Backstory collects news articles from the Internet, it has to queue them for textual analysis and event clustering. Instead of using a traditional persistent queue, we realized that Neo4j would support this requirement with minimal additional effort on our part. We already had Article nodes; so it was a matter of adding an “Unprocessed” label to new ones, and processing them in insertion order.
Our solution for grouping similar articles together into news events is based in part on the similarity of Article/Actor subgraphs. There is a strong signal in the fact that two articles within a small time span refer to the same actors. Some state-of-the-art clustering algorithms are graph-based, and Neo4j allowed us to quickly approach an excellent clustering solution.
A central challenge for Backstory is recognizing actors in news article text. Until now, we have used a blend of open-source natural language processing tools and human intervention. But we’ve begun to experiment with using graphs to identify actors, and the results are a marked improvement and extremely promising.
Conclusion
As mentioned above, our goal with Backstory is to create better ways for people to consume news and understand the world. Part of this is having a world-class technology platform for collecting and analyzing news.
Neo4j’s vibrant community and the flexibility of the graph database are enabling us to achieve these goals.
Instead of thinking about our database simply as a place where bits are stored, we think of our data as alive and brimming with insights. The graph lets our data breathe, striking the right balance between structure and versatility. Meanwhile, Cypher queries continue to perform well as the model grows more complex.
The Neo4j-powered news graph is absolutely the centerpiece of our system, and we’re excited for what the future holds.
If you’d like to follow our progress, join the mailing list on https://backstory.io or give us a follow on Twitter at @backstoryio.
Ready to use Neo4j for your next app or project? Get everything you need to know about harnessing graphs in O’Reilly’s Graph Databases – click below to get your free copy.
Share Article



Explore
Related Articles




How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs

