

Mark Needham: Today we’re going to look at how to import a dataset from Stack Overflow into Neo4j:
Stack Overflow is an online community where programmers both post and answer questions on a variety of developer topics. Neo4j has become a large area of discussion on the platform — so far there have been over 10,000 questions asked and answered:

We thought it would be interesting to pull all of this data into Neo4j to see if we could learn anything interesting from all the posted questions and answers. So today we’re going to go over the process for bulk data import into Neo4j. If you’re interested in replicating what we did today, you can check out this blog post.
Importing the data: Stack Exchange API
Michael Hunger: Stack Overflow has an API called Stack Exchange. While it has rate limits and takes a while to download all the data, the data dump is hosted on the Internet and provides gigantic XML storage. It’s essentially a dump of an SQL Server — CSV pretending to be XML — and contains about 66GB of data.

Mark: So we have two APIs with two completely different types of data — there is one which is updated constantly and is like an API, and then a data dump that happens once a month. To bring the two together in Neo4j, we need what we’ll call “magic import dust:”
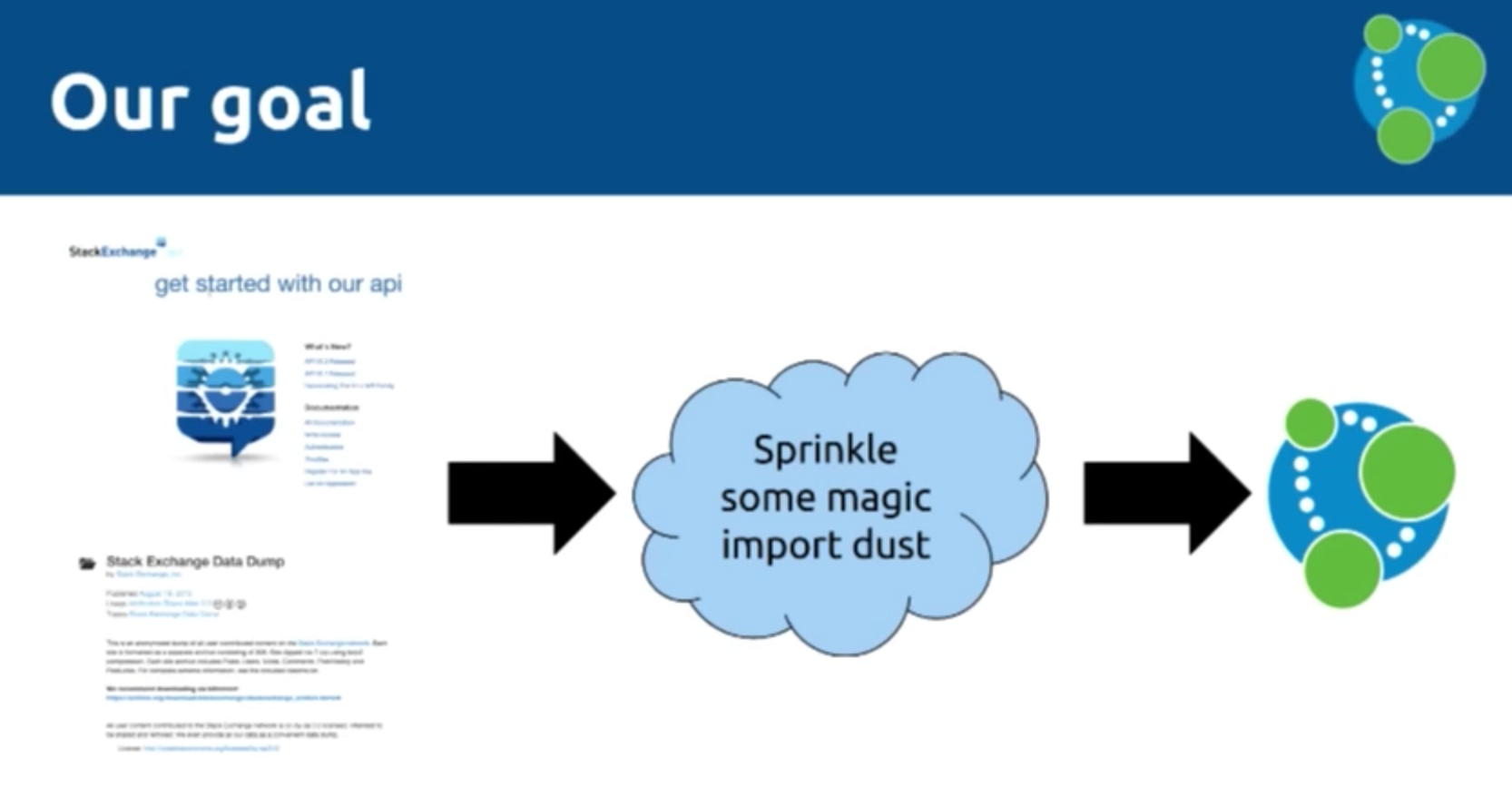
We will use the below API in two different ways to get all of the information from Stack Overflow into Neo4j, which has a number of properties that describe different elements.
Michael: The question ID is in HTML, while the title, text, answer and interpretation of nodes is in the JSON API:

LOAD CSV
Mark: We are going to go over two different ways to process this JSON data, the first of which is via a tool called LOAD CSV, which allows us to iterate over CSV files and create things in the graph. But we have to convert from the JSON to CSV:
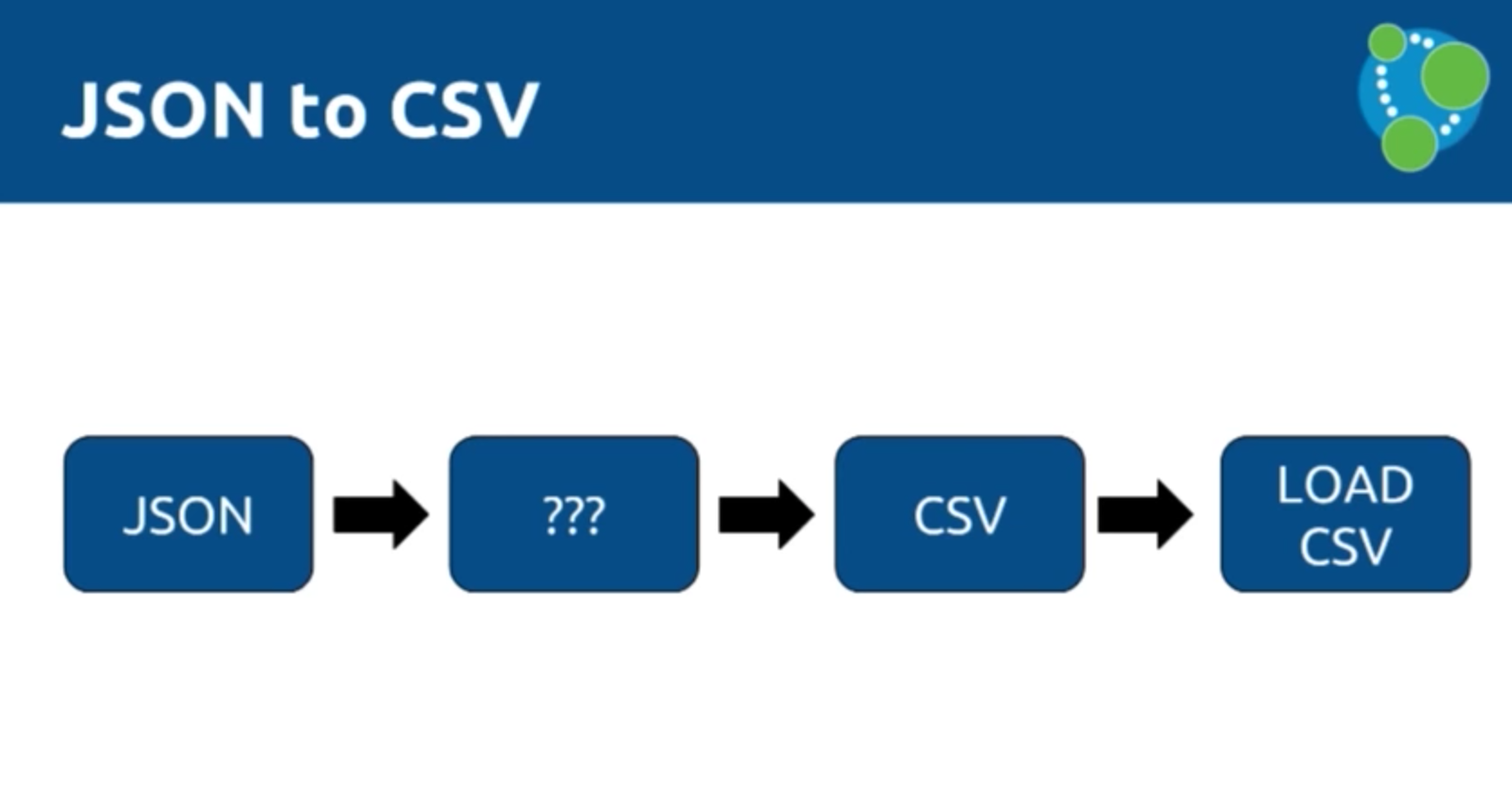
Remember, our goal is to create a graph that includes users, answers, questions and tags, which are used to organize questions and get the right person to answer them.
Michael: It’s very important to determine your data model before importing your data. You have to know what you’re trying to do with the data and the questions you’re trying to answer so that you can use your data in a relevant way. You’ll also likely have to manipulate the data to fit your data model prior to import.
For example, we decided not to include the body of the questions or the comments because they weren’t relevant to our data model, which is depicted below:
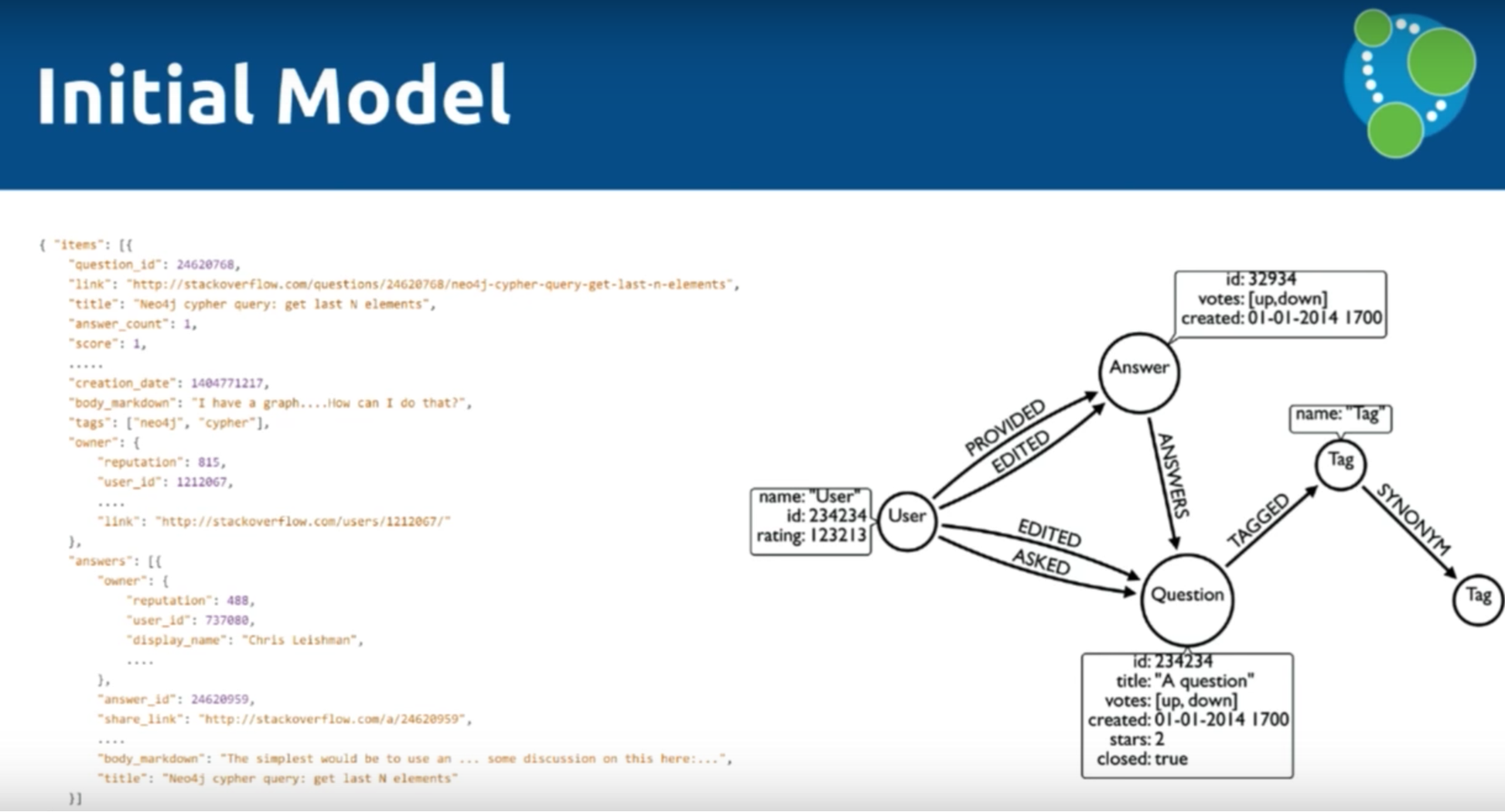
We used the tool jq to convert our data from JSON to CSV, which is comparable to XPath for XML. It’s implemented in C and C++ so is very fast and has a rich data language.
Mark: Let’s explore the following example, which we will ultimately upload into our data model:

We’ve downloaded an array of questions into a file, and then we’ll iterate through them and have them sit under an array called “items”. We’ll then go through these items and grab the question ID, title, etc., each of which will be a column in our CSV file. If a question has multiple tags, we separate those with “;”. We then run all the data through a filter. This returns the following standard CSV format:
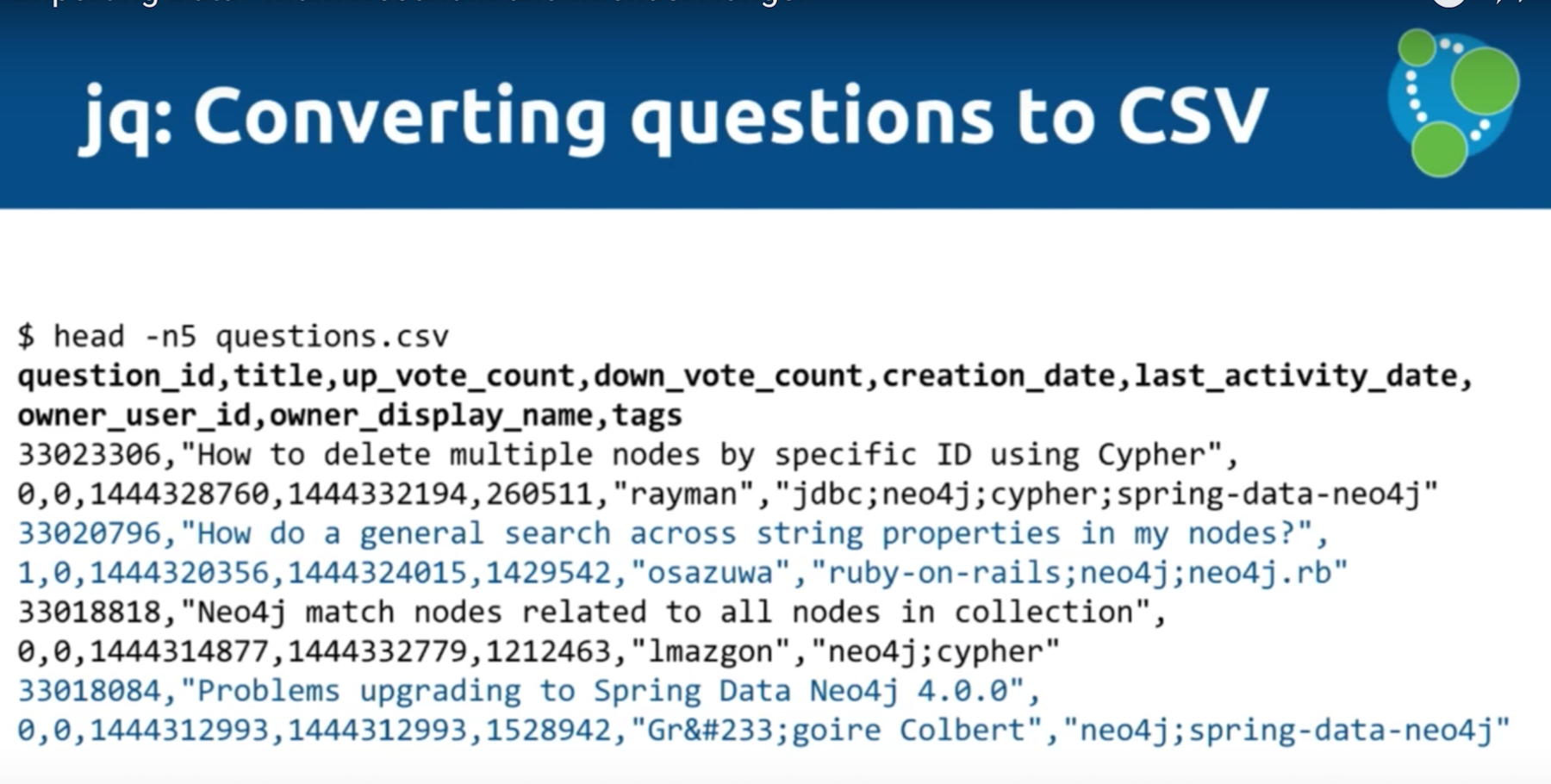
You can see that we have a question ID, up vote, down vote, etc. and one row for each JSON document that we had in our original API call.
Michael: It depends a bit on your jq query how many rows you get, but in our case it’s one row per question.
Mark: Then we do the same for the answers. We jq the JSON document into CSV, which is now in a format that works for LOAD CSV (which again, we use to import the data into Neo4j).

Below is the LOAD CSV tool, which is a command in Cypher that allows us to iterate over a CSV file. We can provide either a URI or a file part, so if you find a CSV on the web you can upload it directly without even downloading it to your machine.

Michael: Depending on whether or not headers are provided, LOAD CSV will return each line of the CSV as either a list of values or as a map that allows you to map headers to fields. You can create, update, move and match data with information that comes in from the CSV.
You can drive computation, filter, group and aggregate the CSV on certain properties to sort data qualities, and run the CSV through Cypher. This allows you to see the data the same way Cypher does — with lone quotes and binary zeros.
Mark: After we apply Cypher operations to our map, there are three things we’re going to hook up: CREATE, MERGE and MATCH. CREATE allows us to create things such as nodes and relationships, which — without any constraints — will cause our database to perform this action every time.
If we don’t want the database to create connections because they’re already there, we’ll use MERGE. But, if there are some instances in which connections aren’t already there, it will create them.
You’ll also want to use MERGE if you want to write item-potent LOAD CSV scripts. Sometimes we’ll have some data already in the database which we will also want to add to the graph with a LOAD CSV query. In those cases, we might want to add a MATCH as well.
Michael: As a general rule, CREATE is faster than MERGE because it doesn’t have to check the data — it just pumps in the data. This is especially useful in an initial import, but keep in mind that you’ll have to check for duplicates outside of Neo4j.
Because LOAD CSV returns a list of rows of maps, you can add filters that — for example — aggregate or sort out duplicates. This is done by doing a DISTINCT on input values, reducing the number of rows and killing the duplicates, especially if you have data resulting from JOINs in a relational database.
Mark: Now you have your CSV files from Stack Overflow, so you’re ready to create a graph. You might start out with something like this:

With a LOAD CSV from questions of CSV, you’ll create a question, add then add an ID, title, up vote count, creation date, etc. You’ll also create an owner, which is connected to the relevant question, and iterate through the tags (which is essentially going through the semicolon-separated array we mentioned earlier).
LOAD CSV tips and tricks
1. Start with a small sample
If you run the data the above way, you’ll likely end up with a long run time because you started with your entire database. But when you’re first running your data, start with a small set — such as 100 data points — to see if your query works. This speeds up the round trip times, which allows you to make adjustments and corrections to your query without having to first wait for your entire dataset to run:

2. MERGE on a key
Mark: Another important tip to keep in mind is to MERGE on a key. MERGE will explore all the properties you’ve placed on your data. So you can ask the question — Is there anything else already in my database that, in this case, has the same ID? Is there any question which has the ID and the title and the up vote count and the creation date? So you’re checking four different elements when actually you know whether or not a question is unique based on its ID.
This is effectively the Stack Overflow primary key. Because each question has an ID, we don’t need to compare every property to see whether or not it’s the same.
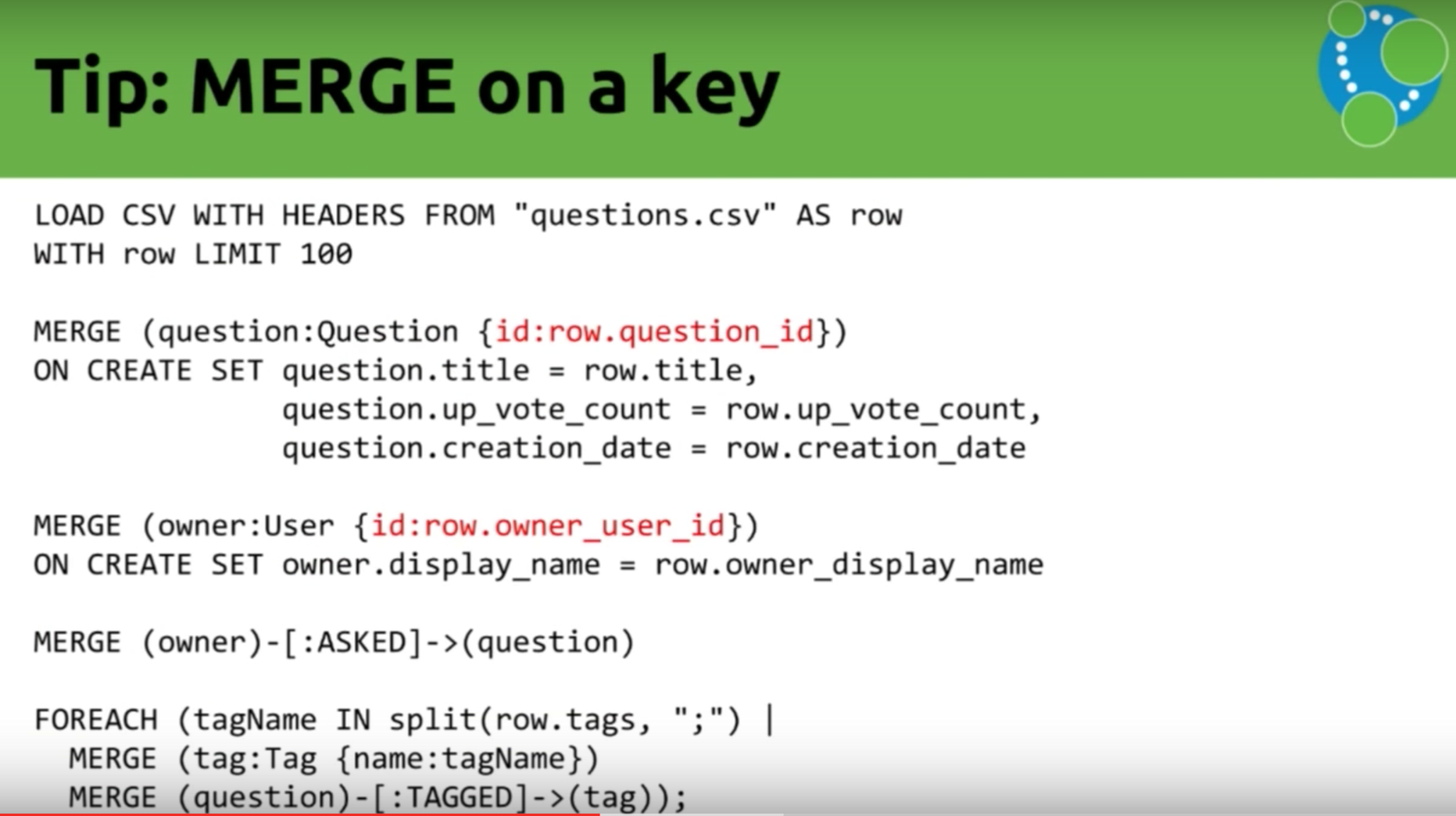
We can do the same for the owner as well. We have a key on the owner, so the next key MERGE tip is to use the key inside your MERGE.
Don’t put every single thing in there because what you probably want to do is set these properties if they aren’t already set. You don’t actually really want to use them to go and remove duplicates so we’re just pulling this apart, and we’re using the ON CREATE clause to help. If you run the script again, it would make sure the question is there.
3. Use constraints and indexes
There are two ways to make a search faster: 1. by using constraints, which ensure uniqueness, and 2. indexes, which provide a starting point for the search.

Michael: The constraint automatically creates an index, so creating a constraint allows you to take advantage of both constraints and indexes.
4. Use only one MERGE statement
Mark: Our next tip is to use only one MERGE statement instead of building one massive input query:

Using one MERGE per statement is faster than creating one large overarching MERGE. For example, create one MERGE for the question, one for the owner and one to combine the two.
Michael: At this stage, since all node flavors are independent of one another, you can also run imports in parallel. There are some nodes, such as a tags, which have a lot of relationships. If you do a MERGE of these relationships, the database will check to make sure there isn’t already a relationship of this type and direction between the two nodes. To do this, it iterates over the relationships between the nodes.
This can take some time, depending on how many relationships that node has. However, the tool will automatically check the node with fewer relationships. Which is called MERGE inter-operation.
5. Use DISTINCT
Mark: Our next tip is to use DISTINCT, which equates to a “don’t-do-the-same-work-over-and-over-again” tip. In this dataset it applies to the tags:
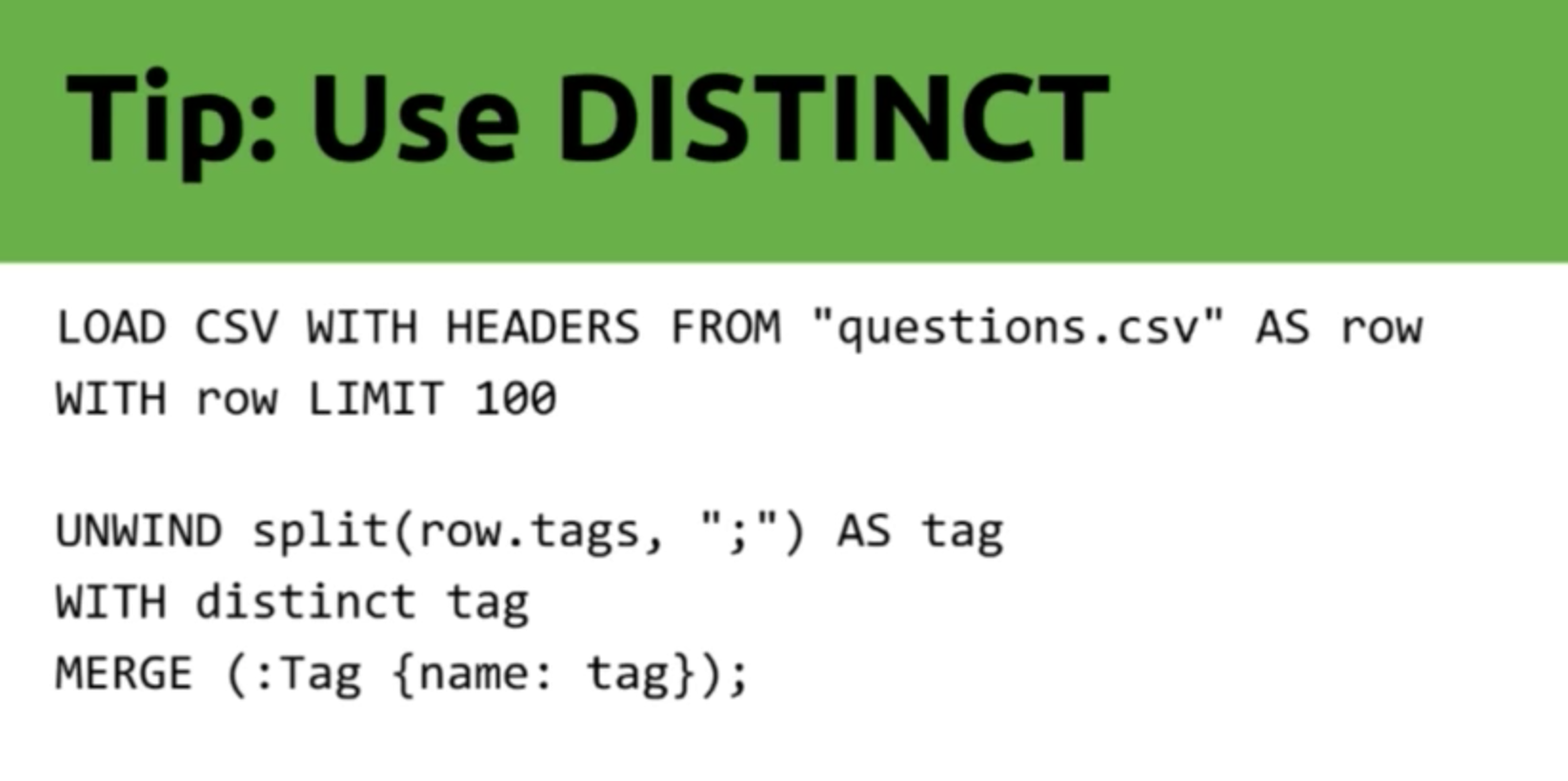
Lots of people add the same tag over and over again to our questions. For example, of our 10,000 Neo4j entries, you’ll see 10,000 entries with the Neo4j tag. To reduce the amount of work the MERGE has to do, we can use DISTINCT when we create our tags. Instead of creating or going over Neo4j 10,000 times, we just get it once and then we create it.
6. Use periodic commit
Mark: Another tip that you can use in LOAD CSV is a PERIODIC COMMIT, which in this example will take the first 1,000 questions and commit those before going on to the next 1,000. This prevents you from exceeding your RAM:

Michael: Something between 10,000 and 100,000 updates per transaction are a good target.
Mark: Something to keep in mind is that PERIODIC COMMIT applies only to LOAD CSV. If you want to do a big graph refactoring of something that you’ve already imported, you’ll have to do batching.
6. Script import commands
Our next tip is to script your import commands. We’ve been showing individual queries, which are fine when you start, but as you become more experienced you’ll want to start collecting them into a script. You can run these through the neo4j-shell tool that comes with the database:
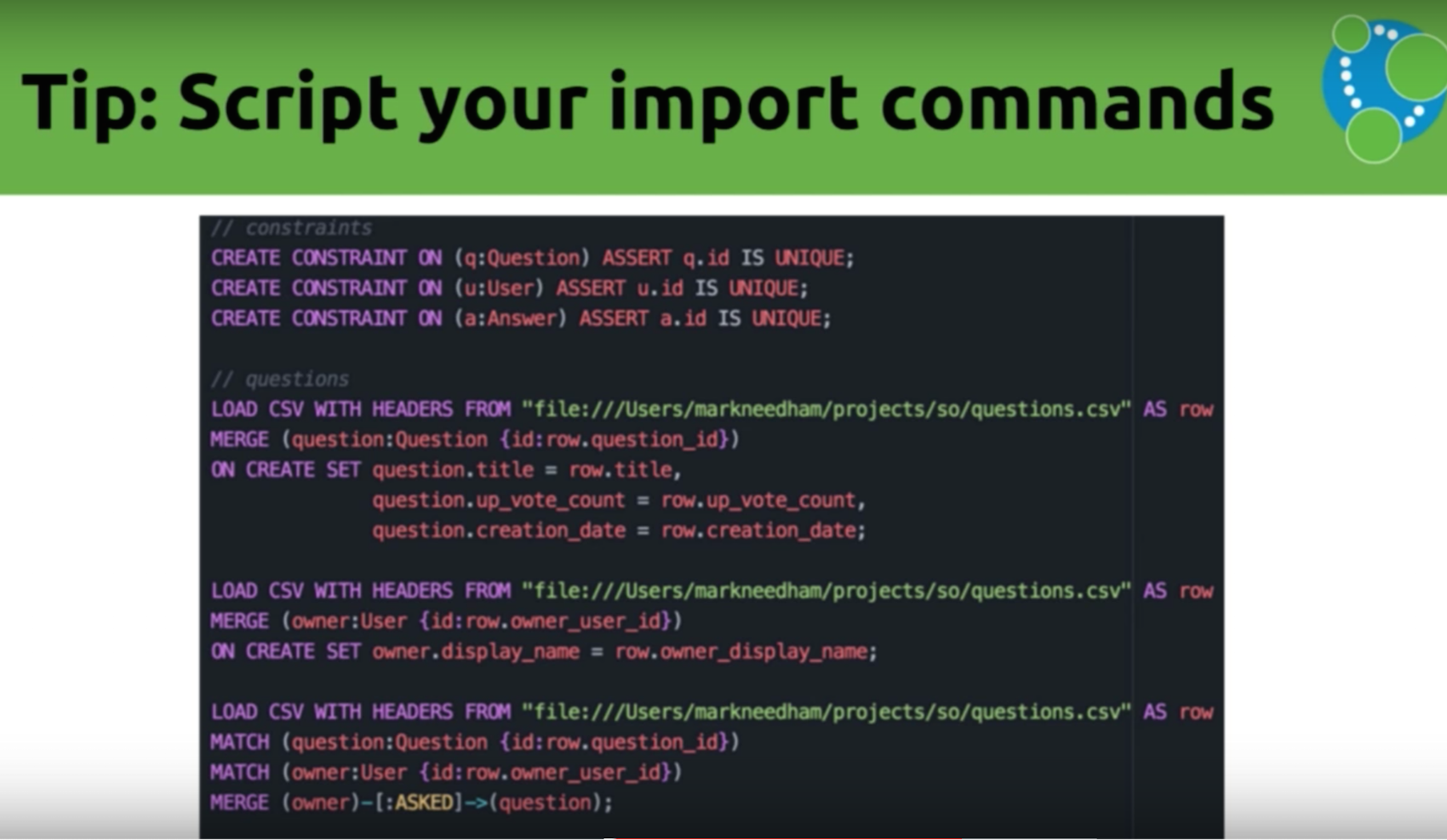
Michael: While neither Windows Excel nor DMG comes with the shell, there is a tool written by my colleague, William Lyon, which has a web version that allows you to upload and automatically run a file.
Mark: In summary, LOAD CSV is a tool that can be used to import and inspect data. It has been included in Neo4j since version 2.1, allows you to load data from any URL, and is ideal for any medium-sized dataset, which we define as up to 10 million rows. If you go beyond that, you’ll want to use the next tool we’re about to introduce.
Neo4j 3.0 brought the introduction of procedures, which allow you to write your own custom code and call it from Cypher. Michael created Awesome Procedures (APOC) in Github, which you can access here.
Load JSON
Michael: One example procedure is LOAD JSON, which uses Java to convert JSON to a CSV instead of jq. We just put in two lines of Java to get the JSON URL, turn it into a row of maps on a single map, return it to Cypher, and perform a LOAD CSV:

Mark: Below is the Stack Overflow API. We call the JSON directly, pass in the URI, and don’t need a key for the API so we just call for the questions. It will send 100 questions with the Neo4j tag and will come back with the value as the default. You YIELD that and use the UNWIND keyword to separate all the items, which then returns the question ID and the title:
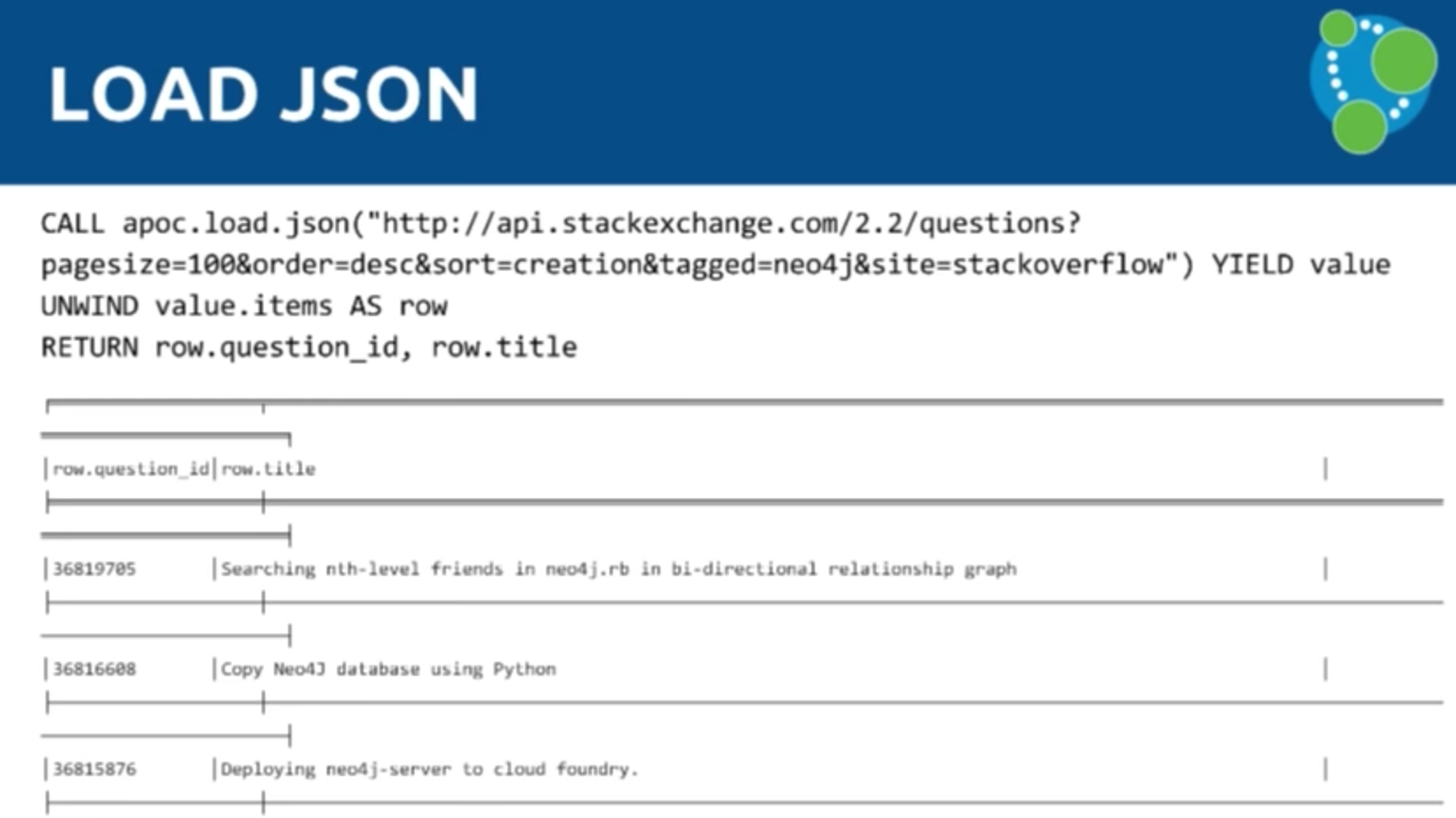
Instead of doing LOAD CSV, you could do LOAD JSON instead. And now we’re in exactly the same place — instead of having to use the CSV file, we can just phrase this to JSON directly.
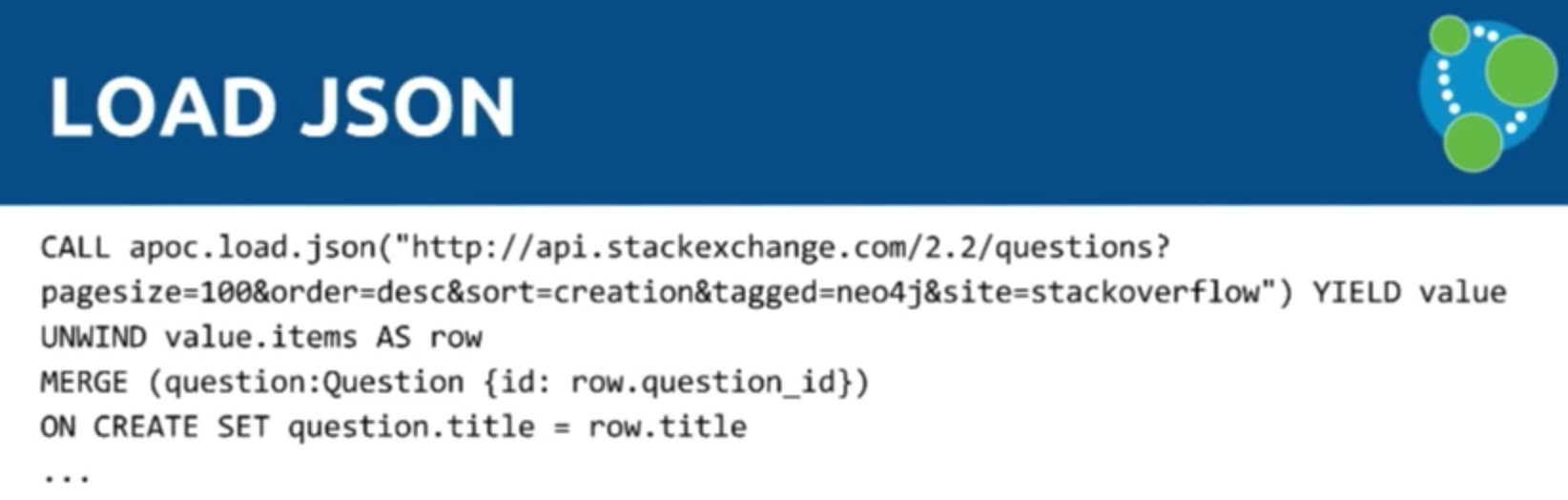
And you can apply all the previous tips related to LOAD CSV to LOAD JSON as well.
But now we’re going to explore how to bulk data import the initial dataset.
Michael: We took the initial dataset — comprised of gigantic XML files — and wrote Java code to turn them into CSV files. Neo4j comes with a bulk data import tool, which uses all your CPUs and disk I/O performance to ingest the CSV files as quickly as your machine(s) will allow. If you have a big box with many CPUs, it can saturate both CPUs and disks while importing the data.
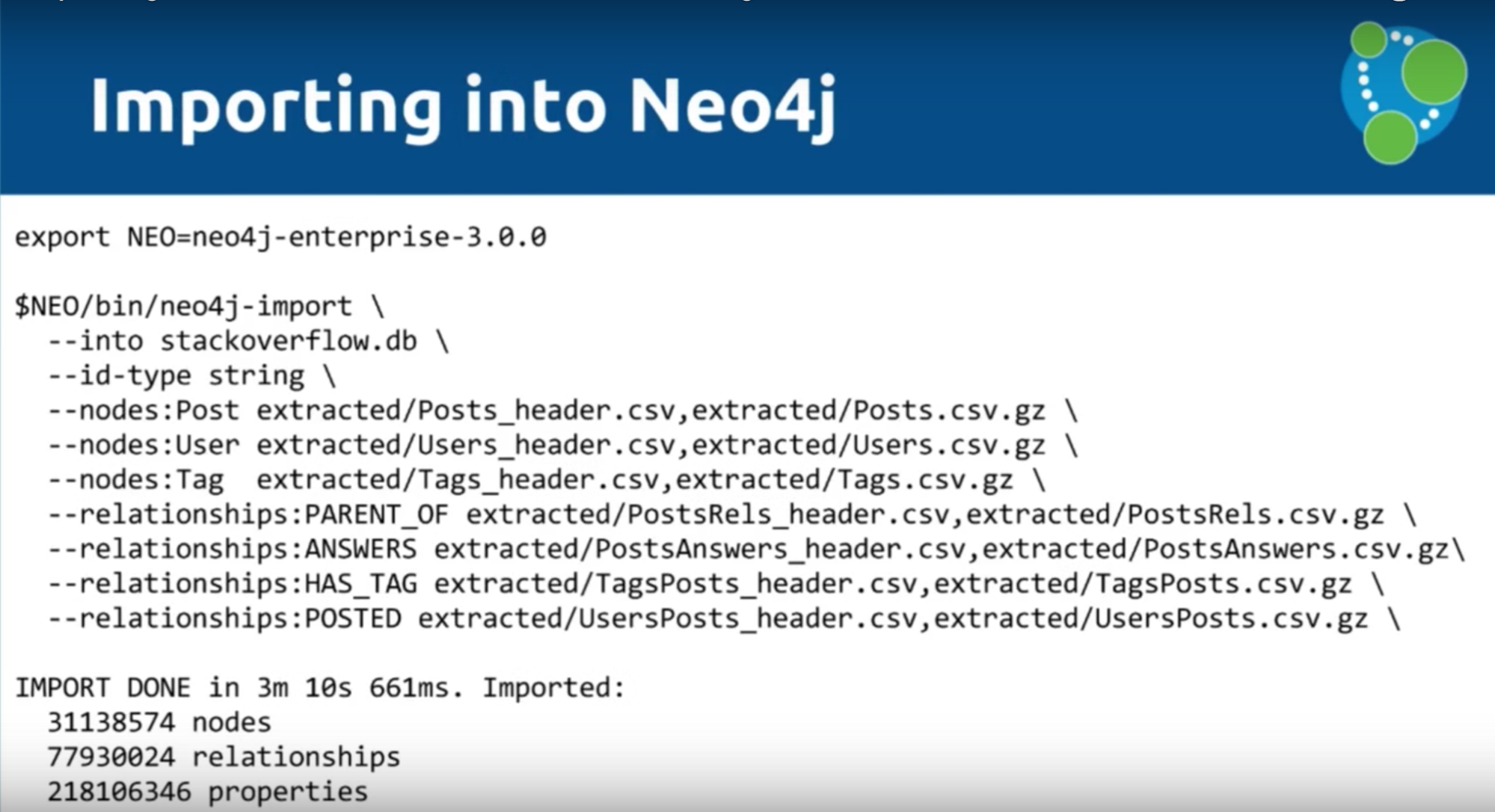
Mark: In your BIN directory when you download Neo4j 3.0, you get a tool called neo4j-import which essentially allows you to build an offline database. As Michael said, we’re skipping the transactional layer and building the actual store files of the database. You can can see below what CSV files we’re processing:

While this is extremely fast, you first have to put the data into the right format. In the above example, we give each post a header so that we can separate them into header files.
Often when you get a Hadoop dump, you end up with the data spread out over a number of part files, and you don’t want to have to add a header into all of those. With this tool, you don’t have to. Instead, you note that the headers, relationships, etc. are in different files. Then we say, create this graph in this folder.
We’re running this for the whole of the Stack Overflow dataset — all the metadata of Stack Overflow is going to be in a Neo4j database once this script is run.
Below is what the files look like. This is the format you need in order to effectively define a mapping. You can define your properties, keys and start IDs:

So we’ve converted an SQL server to CSV, then to XML, and now back to some sort of variant of CSV using the following Java program — what I will call Michael’s magic import dust:

This is what the generated Posts file looks like:

And below is our Neo4j script, which includes 30 million nodes, 78 million relationships and 280 million properties that was imported in three minutes and eight seconds:
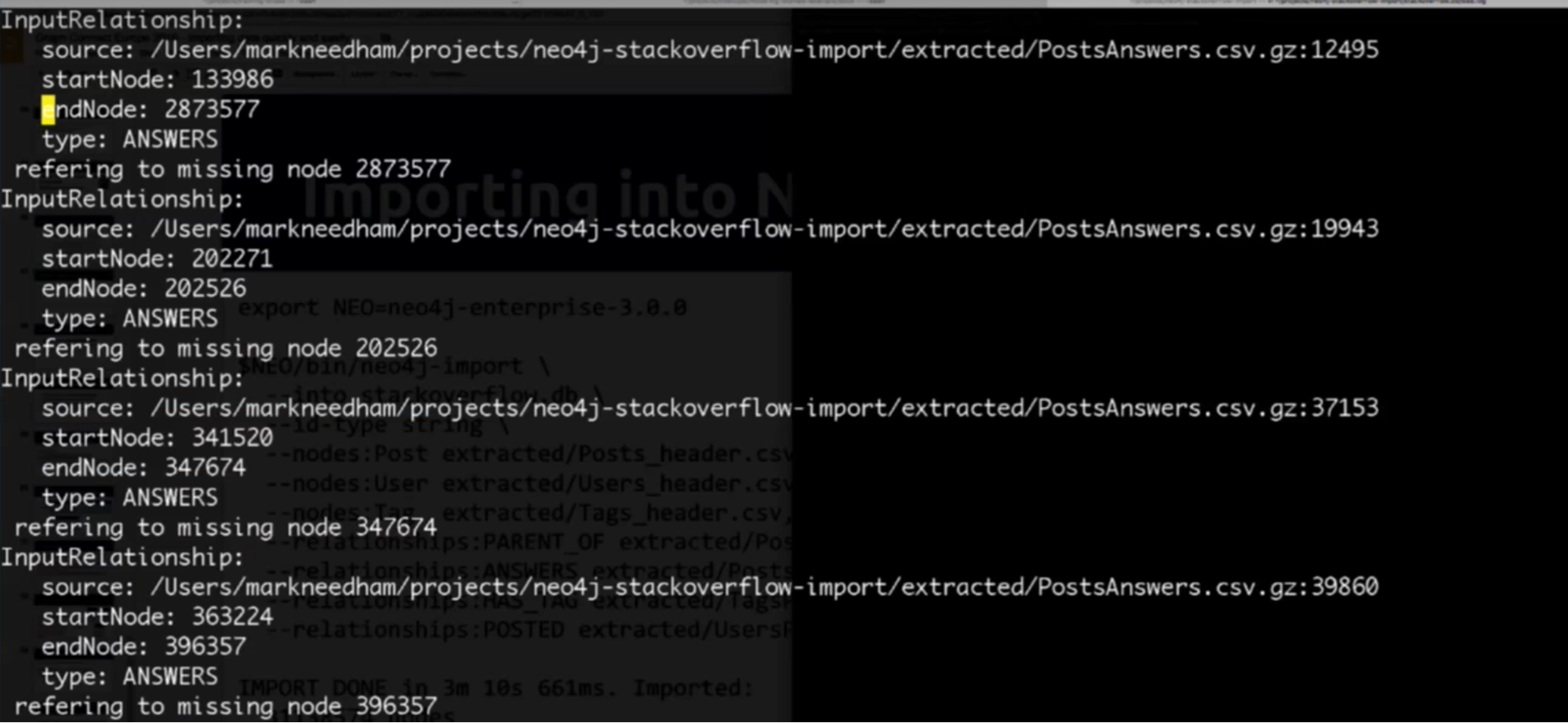
Mark: The other cool thing you’ll see is that you get a file telling you if there was anything that it couldn’t create, which is essentially a report of potentially bad data:
Summary
Michael: Remember — the quality of your data is incredibly important:

And some final tips to leave you with:

To learn more, you can find Michael and Mark on Twitter, and check out the following resources:
- Stack Overflow on Github
- Neo4j blog post on Stack Overflow
- Loading JSON from URL
- Neo4j APOC Procedures on Github
Inspired by Michael and Mark’s talk? Click below to register for GraphConnect San Francisco and see even more presentations, talks and workshops from the world’s leading graph technology experts.
Share Article



Explore
Related Articles


Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.



