PageRank is an important concept in computer science and modern technology. It is important because it is the underlying algorithm that mostly dictates what more than 3 billion users who use the internet experience as they browse the world wide web.
How does it work?
The first PageRank algorithm was developed by Larry Page and Sergey Brinn at Stanford in 1996. Sergey Brinn had the idea that pages on the world wide web could be ordered and ranked by analyzing the number of links that point to each page. This idea was the foundation of the imminent rise of Google as the world’s most popular search engine, with now over 3.5 billion searches made by its users every day.
PageRank gives us a measure of popularity in an ever connected world of information. With an enormous degree of complexity increasing every day in the virtual space of information sharing, PageRank gives us a way to understand what is important to us as users.

The unfortunate bit of this is that PageRank itself is mostly unapproachable to anything but seasoned engineers and esteemed academics. That’s why I want to make it easier for every developer around the world to make this algorithm the foundation of their innovative desires.
Categorical PageRank
It should be no surprise to regular readers of this blog that I am all about the graph. Graphs are the best abstraction of data that we have today. The concept is brilliantly easy and intuitive. Nodes represent data points and are described by meta data. Relationships connect nodes together, also described by meta data, and they enrich the information of each node relative to one another.
As I have been building the open source project Neo4j Mazerunner to use Apache Spark GraphX and Neo4j for big scale graph analysis, I’ve come to understand the need for breaking down PageRank into categories. Something I call ‘Categorical PageRank’.
This concept is pretty simple actually. I came across it when I was trying to understand why calendar year articles on Wikipedia have a distinct pattern of PageRank growth when plotted on a line graph. I introduced this data in an earlier article.

To better understand the causality it would be necessary to break each PageRank down into a set of partitions that could describe what the contributing factors were to the rise or decline of each year’s PageRank. This led me to an idea. That I could build a job scheduler that would scalably distribute PageRank jobs using both Neo4j and Apache Spark. This builds on top of earlier work I’ve done described here.
Over the course of a weekend I was able to sketch out a design on a whiteboard and implement the functionality as a proof of concept to see whether or not it would both work and be scalable (because all things I build must be web scale).
Here is that design:

The design describes the property graph data model of the popular open knowledge graph, DBPedia.org. This knowledge graph is a crowdsourced community effort that extracts information from Wikipedia and organizes it as a graph data model. You have resources which represent pages of Wikipedia articles and you have categories that organize that information into a set of common groups. Each Wikipedia page has a set of links that link to each other. PageRank only requires an edge list that describes those inbound and outbound links of each page.
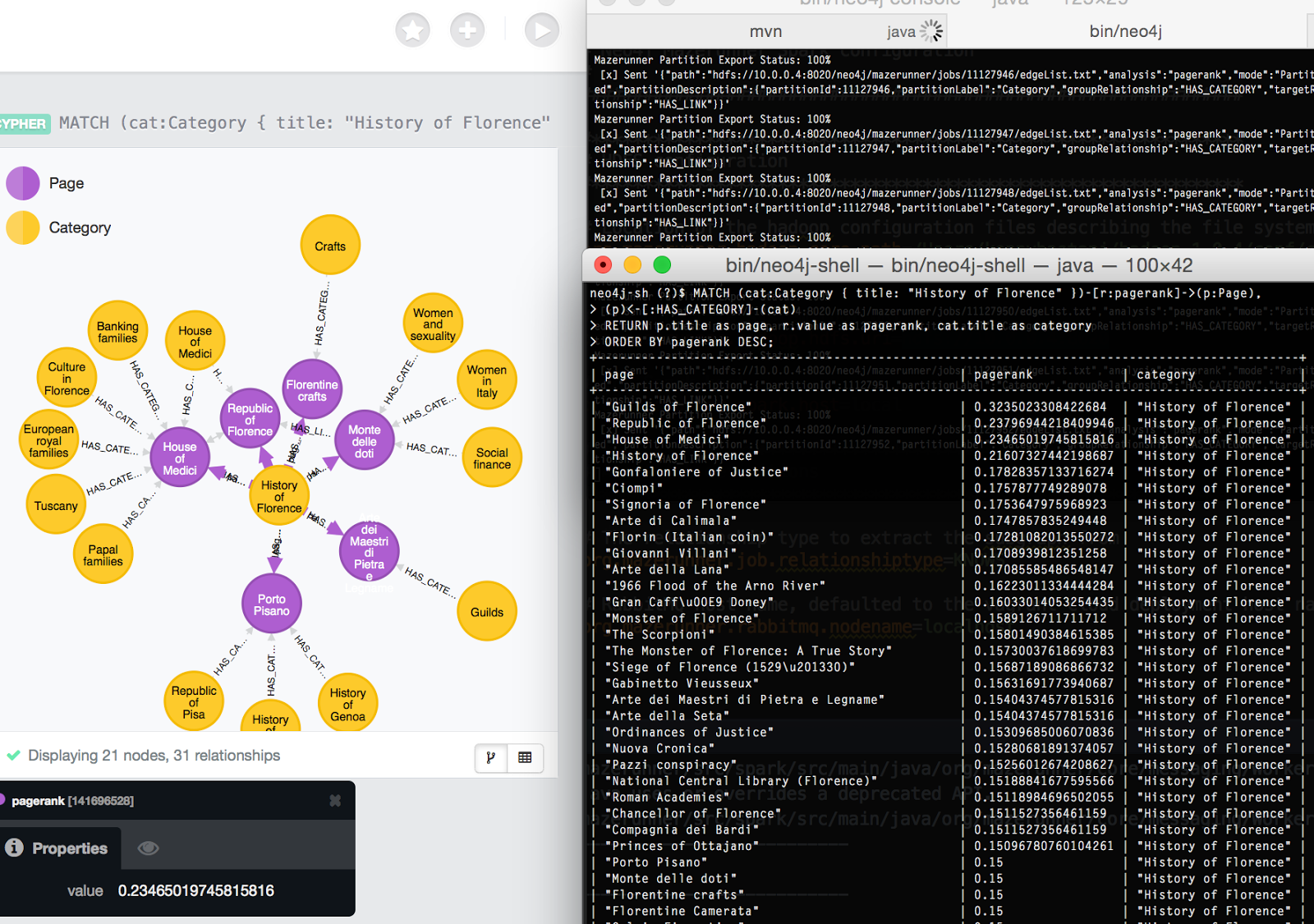
In the design I show two partitions of nodes, pages and categories. There are four page nodes and of the four there are two that belong to the blue category and three that belong to the red category. I’ve colored the one that is in both blue and red categories as purple.
While we see that the four nodes have links connected to one another, I wanted to partition PageRank jobs so that I could analyze subgraphs that describe each category.
For PageRank Partition 0, the blue category, the bottom box it is connected to describes the result of the analysis operation that was received back from Apache Spark and stored as a property graph in Neo4j. The big revelation here is that the Neo4j relationship entity that is displayed between the category and the page nodes has the results stored for that PageRank analysis. This means that multiple Page nodes can have different inbound PageRank values based on its locality within the graph.
The result of the proof of concept was golden. I imported all of DBPedia into Neo4j and started up my distributed job scheduler. I can scale each Apache Spark node to perform parallel PageRank jobs on independent and isolated processes all consuming a Hadoop HDFS file system where the Neo4j subgraphs are exported to.
While the proof of concept is complete and ready for use, it is still being merged into the master branch of the Neo4j Mazerunner project. You can take a look at the original story detail here for more details: Neo4j Mazerunner Issue 29
Also, here is a screenshot that shows the working system up and running.
Want to learn more about graph databases? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technologies for your application today.
Share Article



Explore
Related Articles

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3