


Collaborative Filtering: Creating the Best Teams Ever

Graduate Intern
7 min read

Editor’s Note: This presentation was given by Maurits van der Goes at GraphConnect Europe in April 2016. Here’s a quick review of what he covered:
–
What we’re going to be talking about today how to use collaborative filtering to provide effective recommendations:
The last couple of months I’ve been working to create a graph recommendation system for the company Part-Up to help people build the best virtual teams possible.
Why do We Need Virtual Teams?
What is Part-Up, and why do we need a recommendation system?
Consider office spaces from about 100 years ago, which consisted of islands of people at individual desks with little communication. This no longer works today, for both economic and personal reasons. We are moving away from hierarchical company structures towards flat structures, we are focusing our specialization in one area, and we are cooperating with other organizations.
Workers don’t want to have to show up at nine o’clock sharp, and may not even want to come into the office at all and work from home or while on holiday. This allows companies to keep up with intense global competition by increasing speed and flexibility.
To operate within these new economic and organizational models, you need a new platform — and that’s where Part-Up comes in. Imagine that you don’t have a fixed function or department, and you can do whatever you want from wherever you want. Part-Up provides the marketplace to find and form any team you need.
We founded the company one-and-a-half years ago, and we launched the platform in August. There are currently a number of public teams that anyone can join, but you first start by supporting the team, then becoming a contributor, and then becoming a partner. You can compare this to GitHub, which has a similar model. And while anyone can start with public teams, you can also create a private team for your own organization for a small fee.
Once you’re in a team, you can see the other activities and colleagues associated with it. There is no team leader; everyone is equal and you cooperate and organize yourselves.
But this is where a challenge arises. If there are over 400 available public teams, which one should you pick? Netflix did an analysis that showed if you have a large number of movie options, people will only check a total of 10 to 20 movie titles – but only three in detail. And the person doesn’t find a movie within that selection that they want to watch, they’ll drop out and never come back.
So we don’t want our users to have to search through hundreds of teams; we want to serve people one team that perfectly matches their interests, ambitions and moods. This is why we started developing a recommendation engine.
How to Develop a Graph Recommendation Engine
System Architecture
Below is our current system architecture:
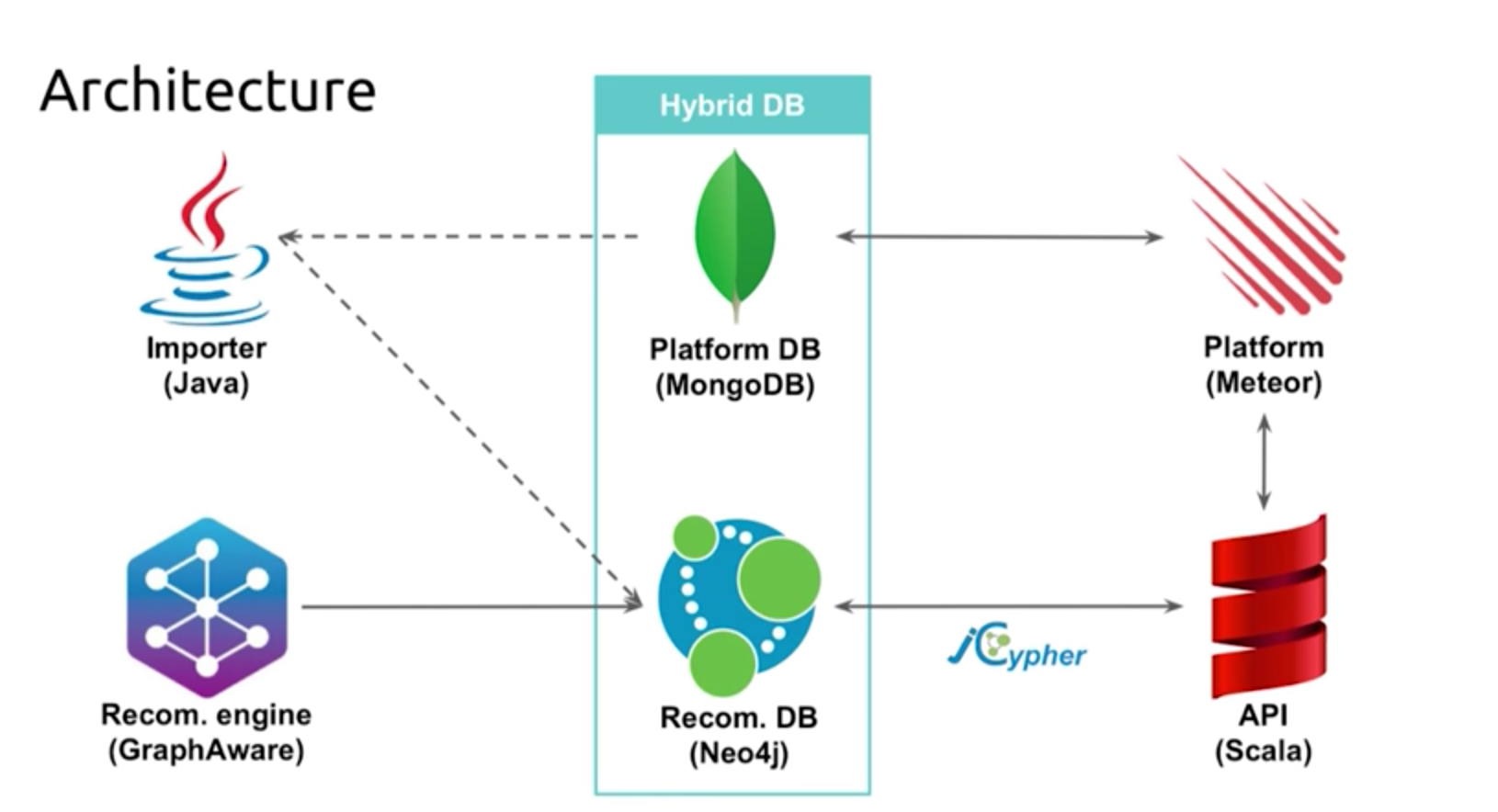
Our website runs on Meteor which works with MongoDB, and we chose to use a hybrid database structure, so MongoDB has all the content for the website but no recommendations. As we all know, Neo4j does a great job walking query paths, which it does much faster than MongoDB.
For this reason, recommendations are calculated in Neo4j and stored in MongoDB. When I request a recommendation via the API, it relies on JCypher to work with Neo4j and retrieve an ID. This picture is then colored in with information from MongoDB.
We create the recommendations with GraphAware, which has a really nice recommendation framework that allows you to specify and customize graph algorithms without having to build an entire framework. The GraphAware team has been really supportive, and I really like their product. The last piece of our system architecture is the Java Importer, which we used to get all of our old data into Neo4j.
Data Model
Below is the logical data model that we use in Neo4j:

I dropped all of the properties for the example, but we have a user which can hold strengths just like a profile. A user is active in a team and a part of a network, all of which are located in a city that is located within a country.
This is what my network looks like in Neo4j:
I’m quite active in a lot of teams (pink nodes), which are connected to networks (yellow nodes). We already know that it’s easy to walk these paths in Neo4j to get recommendations for new teams.
Below is the setup we are using in GraphAware. I’ve added a number of modules:

Next we check with the blacklist to see if there are any recommendations for teams that you are already on. We post produce these, meaning we tweak the results a bit within the post processor.
Below is the Cypher code for the blacklist:
MATCH (u:User) — [r:ACTIVE_IN]->(t:Team)
WHERE id(u)={id} AND r.role>1.0
RETURN t as blacklist
And here are some of the filters that I added:
MATCH (u:User),(t:Team)
WHERE id(u)={id} AND t.privacy_type=2
AND NOT (u) — [:ACTIVE_IN {role:1.0} — > (t)
RETURN t as blacklist
MATCH (u:User)
(n:Network)<-[:PART_OF] - (t:Team) WHERE id(u)={id} AND n.privacy_type=3 AND NOT (u) — [:MEMBER_OF] —>(n)
RETURN t as blacklist
Overcoming Filtering Challenges to Develop the Best Algorithms
Then we go into designing our algorithms. Below are the key filtering challenges we have to be prepared to overcome:
-
-
- Data sparsity: Because we don’t know a lot about our users, we don’t know which teams to recommend. This is especially true with a “cold start,” which is why dating sites, for example, ask a series of questions when you create a profile.
-
-
-
- Grey sheep: You can have users that are unlike any of your other users, which makes providing recommendations a challenge.
-
-
-
- Scalability: This is important not only for the infrastructure, but for algorithms.
-
-
-
- Shilling attacks: You don’t want the false activity of other users to affect your algorithm. Consider the fraudulent activity on Amazon in which people falsified ratings to make their fraudulent product more interesting to others.
-
-
-
- Synonymy: This points to a computer not being able to understand that coding and programming are the same thing.
-
The Basics — and Benefits — of Collaborative Filtering
Let’s explore how these algorithms first developed. The first iteration from about eight years ago resulted in electronic mail overload. To address this, they decided to compare activity in their documents to other the activity of other people, pull some profiles, and maybe even offer a recommendation based on the fact that the things I like are similar to what other users like. This led to collaborative filtering, which is what I use.
Below is a simple example of collaborative filtering:

On the left of the diagram is a user who is active in three teams. In each of those three teams there are three other active users, who are active in four additional teams. If we walk all possible paths for only one of those teams — let’s say team number three — and we continue walking to the teams on the far right, we end up with 12 possible paths. We do this for each team and then come up with a series of rankings.
Because we don’t use any properties, it’s really easy to write the Cypher query:

We first check the IDs of users who are active in a team, which appear as parameters because they’re being used by GraphAware. GraphAware automates the process, runs the query and stores the results in Neo4j.
This code can be tweaked based on whether or not the users have shared text, a shared city, or other similarities. Or if a team is too big and isn’t adding any additional members, it will omit that team from the recommendation results. We can perform this same search process for networks.
But walking 12 paths for every time we wanted to provide a recommendation was quite heavy. We needed a better solution, which we found with item-based collaborative filtering:

Because we didn’t want to bug our users by consistently asking for feedback, we used factors such as their comments, contributions and number of paid views to come up with a rating between one and five, which is what you see above.
But what if we want to predict how much a user will like their team if there isn’t any activity yet? To work around this, we use the adjusted cosine similarity:
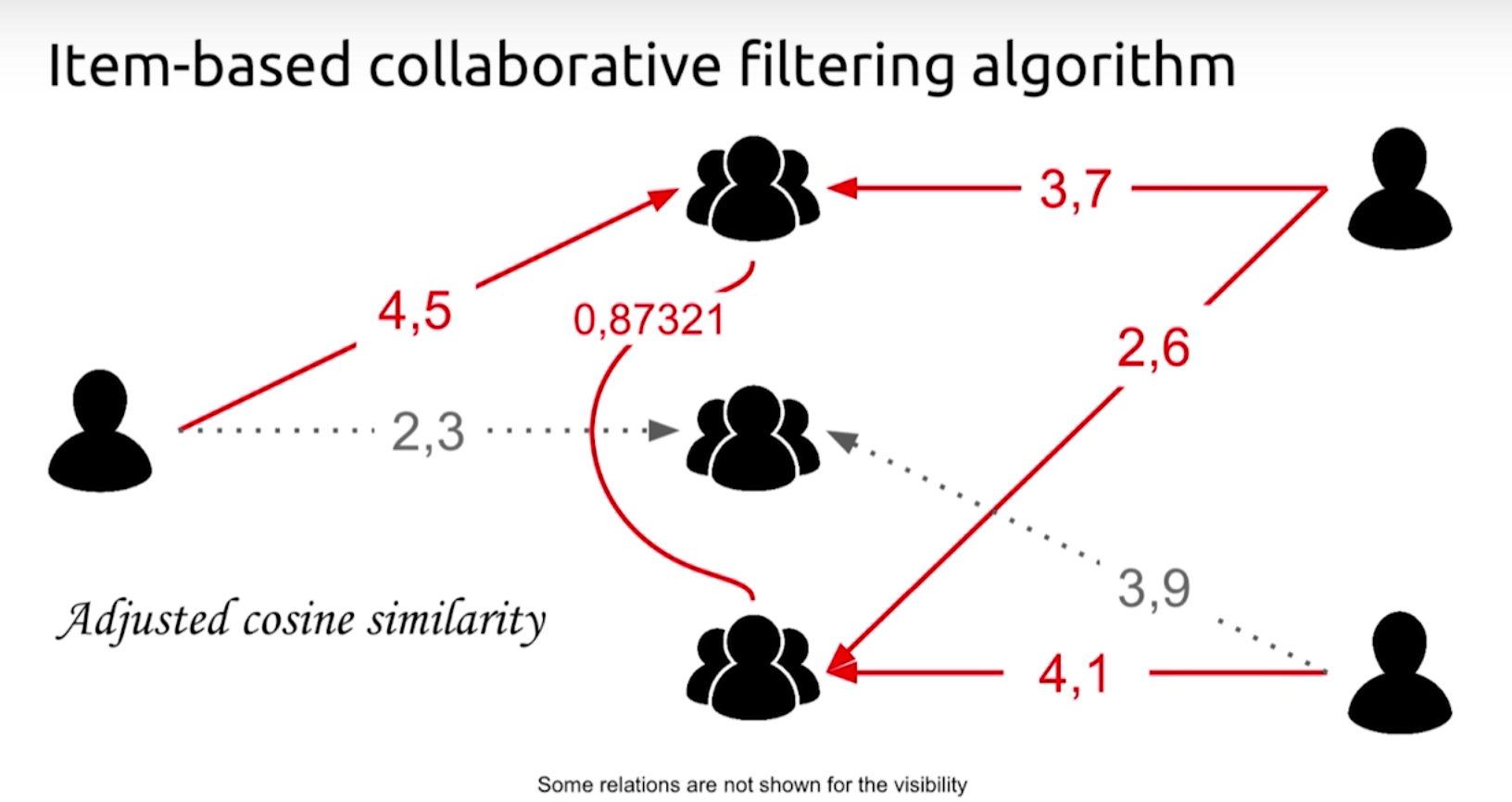
To do that, we compare the ratings that users have given two teams. For example, the user on the top right rated the first team 3.7 and the third team 2.6.
Next we’ll normalize the teams by finding the average score of all the users on the teams, and then you can calculate similarities between zero and one. Based on the result of 0.87321, I know that the first team and the third team are pretty similar.
Now let’s run the algorithm for the second team and third team:

Next we combine this information by using a weighted sum, the similarity between those teams and the ratings that a user is actually providing to teams to provide a good prediction of what their participation score will be:

Based on this information, this user’s participation score is a 3.6. If you do this for all the teams in the database, you can recommend the teams with the top 10 highest scores. You’ll also notice that in this model we don’t need the right side anymore — those two other users. So it’s really a model-based approach where you first create the model with similarities, and then you have an online approach where you use that model and try to predict those recommendations very rapidly.
Below is how to create a similarity with a Neo4j tree and procedures:

This will calculate those similarities, which you have to update from time to time if there are any behavior changes.
Next I use item-based collaborative filtering to run a formula that creates the above rating of 3.6:

I asked our users if they liked the recommendations we provided, and they did. Maybe a little too much, because they also found the random recommendations to be a good fit with their profiles. It’s also important to always show the context; if you let users know you are providing a recommendation, they will start to trust you more.
Part-Up doesn’t only believe in transparency; we practice it as well. We’ve posted everything on Github: our website, API, importer tool and the recommendation engine.
Collaborative Filtering: A Necessity, Not a Luxury
To conclude, collaborative filtering is really necessary. You don’t want to offer your users 450 teams; you want to serve them only one — and people really expect that today.
It needs to be domain independent, which means you need to find a smart way to compare other users instead of just looking at text. It should be easy and customizable. GraphAware and Neo4j, along with a number of other open source tools provide the opportunity to develop your own recommendation system.
The infrastructure and algorithms should be scalable, and make sure the system is a hybrid of MongoDB and Neo4j, and that you have multiple adjacent algorithms to make sure you can provide recommendations to every type of user in your database. Also be sure to visit Part-Up; it’s a great website and marketplace that will change the way you work.
Inspired by Maurits’ talk? Click below to register for GraphConnect Europe on 11 May 2017 at the QEII Centre in London and attend even more presentations, lightning talks and workshops from the world’s leading graph technology experts.
Share Article



Explore
Related Articles

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

Finding the Fastest Way Out: How Dijkstra’s Algorithm Finds Shortest Paths



Whose Signature Really Matters? Understanding PageRank Through Yearbook Signatures
