The co-evolution of computer hardware & graph databases: Why graph-native matters

Chief Scientist, Neo4j
10 min read
Neo4j is a native graph database, which means all of the code – from the web browser to the drivers, Bolt protocol, page cache, cluster protocols, disk storage format — is optimized for graph workloads. As hardware advances come along, we’re uniquely positioned to adapt our software design to make sure that graph workloads run flawlessly on these new compute and storage architectures.
A long time ago…
A year or so ago, Max De Marzi did some very interesting benchmarks about native and non-native graphs. There’s something very important about the algorithmic and mechanical efficiency of native graph technology versus a graph that is “grafted” onto some other kind of database.
In Max’s deconstruction of other non-native benchmarks, he demonstrated the efficiency and performance of native graph technology under real-world scenarios. The inexpensive data structures and high mechanical sympathy of Neo4j always wins out.
To understand why native graph technology is so efficient, we step back in time a little to 2010 and the coining of the term index-free adjacency by Rodriguez and Neubauer. The great thing about index-free adjacency is that your graphs are (mostly) self-indexing. Given a node, the next nodes you may want to visit are implicit based on the relationships connecting it. It’s a sort of local index, which allows us to cheaply traverse the graph (very cheaply, at cost O(1) per hop).
Neo4j manages to keep traversal costs so low (algorithmically and mechanically) by implementing traversals as pointer chasing. This implementation option is available to us precisely because we bear the cost of building the storage engine. And in building that storage engine, we made sure to make traversals as efficient (and therefore as fast) as possible. Pointer chasing is what computers are optimized for: it’s the fundamental fetch-execute cycle. By aligning Neo4j’s architecture that way, we see amazing performance as I’ll discuss in a moment.
Things aren’t so rosy for non-native graph databases. While the developers of such systems benefit from taking an off-the-shelf storage engine, those engines aren’t graph-native and so their users suffer. At runtime, we see the penalty of that choice: global indexes at cost O(log N) to support traversals that are O(1) in Neo4j.
Non-native is way more expensive than just hopping across at constant cost per hop. For even modest graphs that can imply 6-15x more I/O operations and those I/O operations are expensive and scarce which can result in inefficient and slow traversals.
And it’s not just the fact that something is algorithmically O(1) that’s important, but its implementation matters. Hash lookups that resolve over the network may still be O(1) in algorithmic terms, but you also have the mechanical cost of multiple network lookups too. The cost of de-referencing a pointer in your local address space is far cheaper in absolute terms.
Neo4j is very well designed that it’s in memory and on disc format. The way that we traverse relationships is simply by de-referencing pointers, which is something that computers do cheaply. If you can keep the contents of those addresses in your cache, you absolutely flash past. Given Large RAM (and TB RAM is now unremarkable) we’re right in the sweet spot for Neo4j’s storage engine.
Non-volatile RAM
For many years RAM has played second fiddle to CPU in the hardware race. But right now there’s an interesting and potentially revolutionary confluence happening with primary RAM and secondary storage, which have started to come together into something called non-volatile RAM. In the next few years we’re going to see RAM, which is about an order of magnitude larger than current volatile RAM, with a performance penalty of only around 4X slower.
This leads to some really interesting opportunities. In terms of memory representations, Neo4j currently has in-memory and on-disc representations of graphs, each of which are designed to be efficient given the nature of the storage but they must be translated as graphs and paged to and from disc.
But when these formats converge in non-volatile RAM, we can immediately create data structures that are suited precisely for that purpose because — again — Neo4j is a native graph database. We can optimize those structures in non-volatile RAM to support the most demanding graph workloads. So, RAM is getting bigger, NV-RAM is getting bigger, and my prediction is that soon enough most large graphs will be held in non-volatile RAM, dramatically simplifying and reducing deployment footprints and offering staggering performance gains to native graph technology.
Co-processors
There’s another interesting hardware trend that I think is worth mentioning: specialized co-processors. Of course, we are already familiar with co-processors in the form of GPUs which are used to offload certain capabilities from the CPU for tasks as diverse as fast 3D graphics and general-purpose parallel programming.
But now people are starting to think about co-processors for other things — such as, for example, storage in the IBM power series with CAPI Flash:

Because Neo4j is native from top to bottom, we have built a plugin so that it can natively use CAPI flash. The IBM engineers benchmarked it and found it to be twice as fast because they offloaded the heavy I/O work onto the specialized co-processor.
Enter Johan
There is a guy who doesn’t get a lot of limelight: Johan, our quiet, thoughtful CTO and longstanding advocate for native graph technology. He recently led an asymptotic benchmarking effort to determine, “What happens when you really, really, push Neo4j to its absolute limits?” While this isn’t necessarily the kind of benchmark for typical business domains, it allowed the Neo4j developers to understand our mechanical and algorithmic limits and what we could do to make the whole stack even better.
Neo4j is quite an unusual database, and so people often misunderstand it and as graph databases have become a popular category several late-entrants have added their own misinformation to the mix to gain commercial traction.
I know that Neo4j scales very well, but my anecdotal evidence is not data. So Johan took a realistic dataset — the Amazon retail dataset — and took a commodity dual Xeon server and had his team write Java procedures roughly similar to the kind of social recommendation you can see expressed here in Cypher:

In this query, we are asking the database to return something I bought that another person also bought, and then to provide a recommendation. It’s a simple social recommendation that is actually quite valuable since we humans are very influenced by the behavior of our friends.
With a single thread, you can get 3 to 4 million transversals per second. With 10 threads we can max out about 30 million a second, with 20 threads they could max out about 50 million a second, with 30 threads about 60 million:

If you were to put this in a kind of online transaction processing scenario — like an online web app — you can explore a lot of a graph in a relatively short time. You could put this in between your web request and your web response and give a very good end-user experience.
Johan’s team has also demonstrated that Neo4j can comfortably handle trillion-relationship graphs on a single server by aggregating some smaller commodity SSD’s. Subsequently they found that they could sustain about 100,000 of these user-level transactions per second.

That’s 100,000 useful things that users might want to get done per second, not artificial benchmarks. Johan managed this even with a relatively modest amount of RAM (512GB) with 99.8% page faults so the disc subsystem was exercised thoroughly too and it was still very fast.
On the write channel we looked to another real-world dataset. We imported the Friendster dataset which is a highly connected network dataset of about 1.8 billion relationships, and it took about 20 minutes.
To put these read, write and volume figures together: Neo4j can sustain about 50 million traversals per second, a million writes per second, and store a graph with over one trillion records.
You can get a huge amount of work done with this kind of horsepower, all of which exists because Neo4j is natively optimized to suit graph workloads all the way down the stack.
An apples-to-oranges comparison
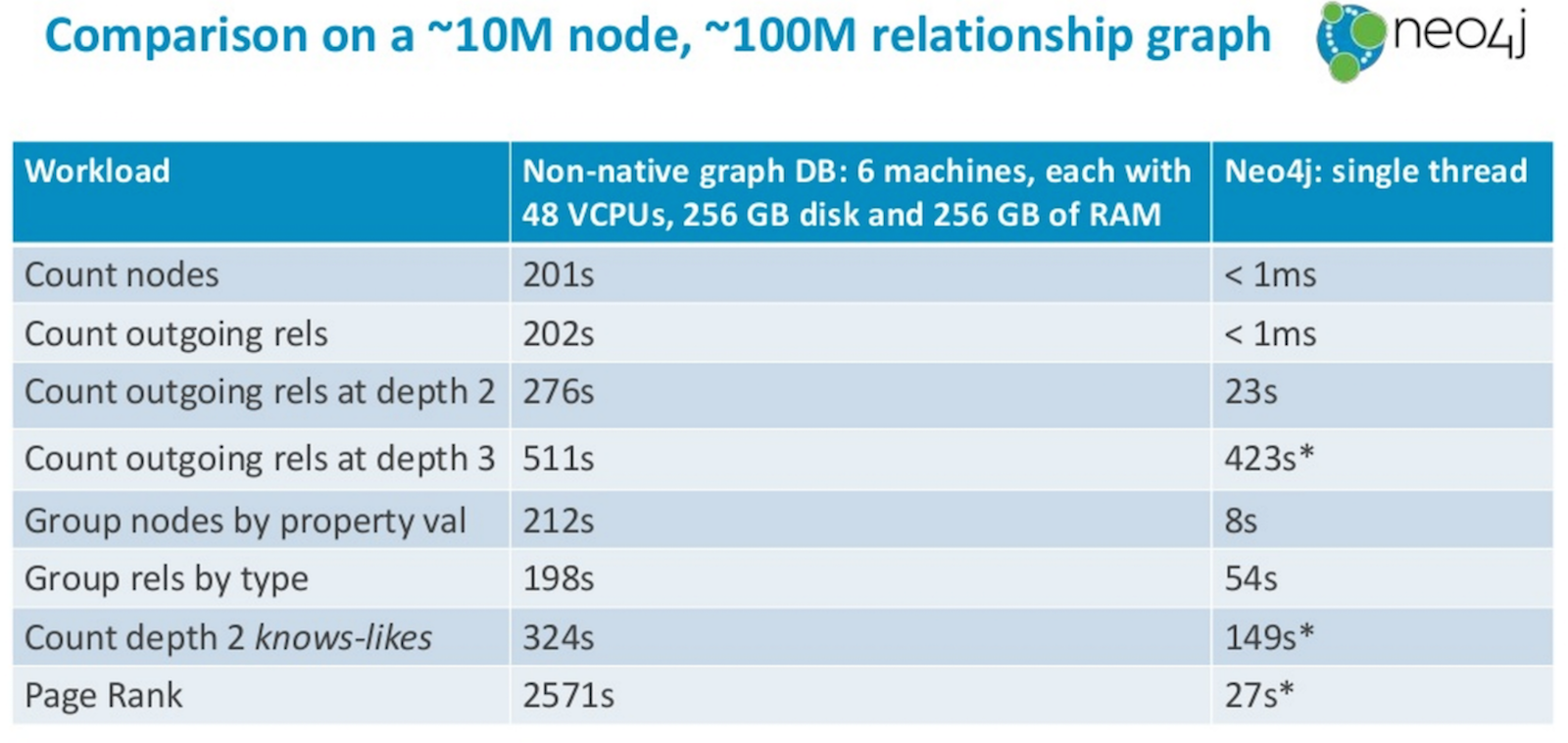
In the run-up to last year’s GraphConnect San Francisco conference, I was shown eight graph analytics micro-benchmarks published by a non-native graph library that sits atop some other kind of database:

Presumably these figures are considered respectable, and I understand they are improvements over early versions of the same benchmark. The experiment took six machines with 48 VCPUs, 256 GB of disc, 256 GB of RAM each, which is about 300 CPUs, and 1.5 TB RAM in total.
I wondered what this 10 million node graph with 100 million relationships, a total of four gigabytes of data, would look like in Neo4j on my 16-gig laptop. And I genuinely didn’t know what was going to happen.
But here’s what did happen:
The ones with asterisks were run on a now low-end 128GB machine (since Neo4j likes the additional JVM heap space for analytic jobs), while the ones without were run on my 16GB laptop. And you can see how hugely Neo4j outperformed non-native graph databases.
I wanted to share these results with my engineering colleagues at Neo4j, who rightly pointed out this is not an apples-to-apples comparison. That’s because when you ask for a count of nodes or relationships in Neo4j, it has specialist stores that can return those requests very quickly. Because it’s optimized for graph queries, Neo4j doesn’t have to hop around the graph counting as per non-native approach because there are specific parts of our storage engine that track graph characteristics.
But I think this comparison is legitimate because it’s what end users experience. That Neo4j optimizes for these workloads all the way down the stack means it simply performs better and that if we can continue this pattern of optimization for our customers’ graph workloads, we can continue to get at least 200,000 times better performance for simple operations, and twice as good for more complex operations.
Importantly “twice as good” is actually downplaying Neo4j’s amazing graph capabilities. Remember that the non-native tech runs on an impressive cluster of machines, but the Neo4j experiments needed only a single core on a commodity machine to outperform.
While it might make some folks excited to run a large cluster of machines, calmer minds understand that it’s better to run a small, efficient cluster of machines that do the same job. It’s cheaper, it’s easier, it’s less risky. And again, Neo4j can deal with this because we’re graph native, and you can see how a single core efficiently stomps all over that macho cluster.
Conclusion
The efficiency of graph-native Neo4j is expressed as very high performance on modest amounts of hardware today. Tomorrow that same native graph database technology will enable Neo4j to track hardware trends at any part of the stack and ensure that its efficiency only ever gets better and the end-user experience is only ever faster and smarter.
If you’d like to hear more, come along to our GraphConnect Europe conference in London where I’ll be talking more about where native graph technology is going.
Sign up for GraphConnect Europe on 11 May 2017 at the QEII Centre in London and connect with graph technology experts from around the world.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

