Cypher – the SQL for graphs – is now available for Apache Spark

Chief Technology Officer, Neo4j
3 min read

In case you missed it at GraphConnect New York: The Neo4j team has announced the public alpha release of Cypher for Apache Spark™.
We’ve been building Cypher for Apache Spark for over a year now and have donated it to the openCypher project under an Apache 2.0 license, allowing for external contributors to join at this early juncture of an alpha release. Find the current language toolkit on GitHub here.
Making Cypher more accessible to data scientists
Cypher for Apache Spark will allow big data analysts and data scientists to incorporate graph querying into their workflows, making it easier to leverage graph algorithms and dramatically broadening how they reveal data connections.
Up until now, the full power of graph pattern matching has been unavailable to data scientists using Spark or for data wrangling pipelines. Now, with Cypher for Apache Spark, data scientists can iterate easier and connect adjacent data sources to their graph applications much more quickly.
As graph-powered applications and analytic projects gain success, big data teams are looking to connect more of their data and personnel into this work. This is happening at places like eBay for recommendations via conversational commerce, Telia for smart home, and Comcast for smart home content recommendations.
Cypher for Apache Spark: A closer look
Follow the openCypher blog and read the latest post for the full technical details of Cypher on Apache Spark.
Cypher for Apache Spark enables the execution of Cypher queries on property graphs stored in an Apache Spark cluster in the same way that SparkSQL allows for the querying of tabular data. The system provides both the ability to run Cypher queries as well as a more programmatic API for working with graphs inspired by the API of Apache Spark.
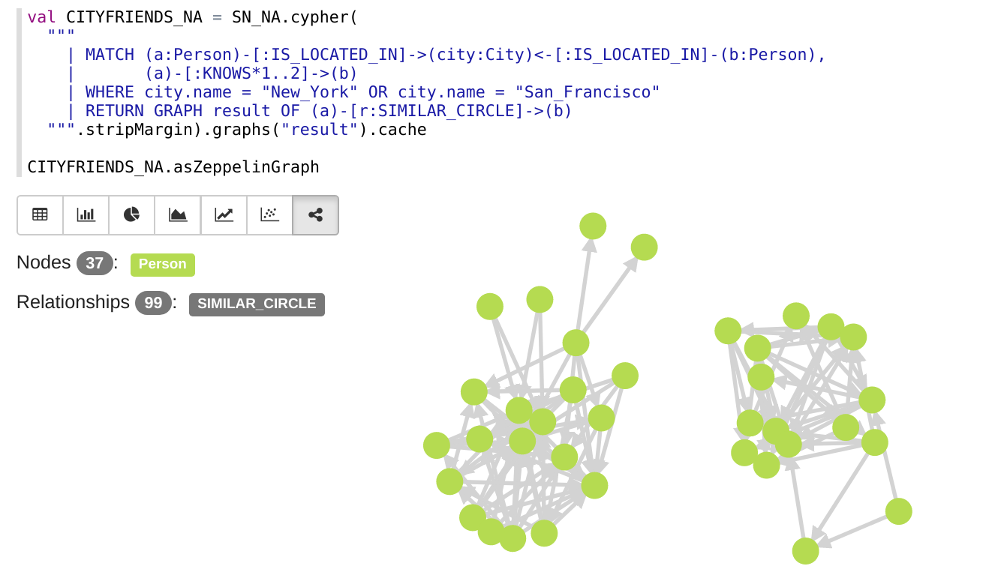
Cypher for Apache Spark is the first implementation of Cypher with support for working with multiple named graphs and query composition. Cypher queries can access multiple graphs, dynamically construct new graphs, and return such graphs as part of the query result.
Furthermore, both the tabular and graph results of a Cypher query may be passed on as input to a follow-up query. This enables complex data processing pipelines across multiple heterogeneous data sources to be constructed incrementally.
Cypher for Apache Spark provides an extensible API for integrating additional data sources for loading and storing graphs. Initially, Cypher for Apache Spark will support loading graphs from HDFS (CVS, Parquet), the file system, session local storage, and via the Bolt protocol (i.e., from Neo4j). In the future, we plan to integrate further technologies at both the data source level as well as the API level.
Cypher for Apache Spark also is the first open source implementation of Cypher in a distributed memory / big data environment outside of academia. Property graphs are represented as a set of scan tables that each correspond to all nodes with a certain label or all relationships with a certain type.
Conclusion
We at Neo4j are proud to be contributing Cypher for Apache Spark to the openCypher project to make the “SQL for Graphs” available on Spark and the wider community. This is an early alpha release, and we will help further develop and refine Cypher for Apache Spark until the first public release of 1.0 next year.
Until then, we look forward to your feedback and contributions. The data industry is recognizing the true power of graph technology, and we’re happy to be building the de facto graph query language alongside our amazing community.
Click below to get your free copy the O’Reilly Graph Databases book and discover how to harness the power of graph database technology.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

