
An Automated Market of Cypher-Annotated Microservices, Part 1 [Community Post]

Co-Founder, Ianta Labs
5 min read
[As community content, this post reflects the views and opinions of the particular author and does not necessarily reflect the official stance of Neo4j.]
About 75 years ago, Allan Turing showed us how to build a universal computer.
At the time, computers were human individuals, whose jobs were doing mathematical computations. It might have been the simplicity of the technology at that time that influenced Turing to imagine his automatic machine as a simple, tape reading and writing mechanism following internal states and a limited number of instructions.
Turing’s thought process in designing his machine seems to have been guided by observing movements which human computers conducted in order to perform calculations.
In this series, we’ll take a similar approach and try, more ambitiously, to build a universal problem-solving machine making use of new technologies and concepts of the Internet era.
Presuppositions
Instead of a human computer, we’ll consider first the actions of a human problem-solver whose job is to find a sequence of actions aimed to solve a specific problem. Then we’ll look at the case when the problem solver is a programmer skilled to add lines of code to a program designed to solve a business problem even faster.
Instead of reading and writing symbols on a tape, we’ll consider “reading” context representations from real contexts and “writing” or making changes in real contexts. Instead of simple arithmetic instructions, we’ll consider procedures with defined inputs and outputs and an associated cost and duration of execution.
And to build a sense of community, collaboration and open competition, we’ll consider the option of having the list of instructions as an open marketplace where other programmers and problem solvers will publish their microservices to be selected to be part of the solution.
Defining the Problem
The first issue for us to solve is to define a problem.
We’ll consider a problem as being defined by an initial context, a target context (or contexts) and a list of constraints always including a budget, a timeframe and a limited number of instructions available in the market.
Solving a problem will mean to search for one or more sequences of instructions or services, which will transform the initial context into one of the desired contexts.
The second issue is to choose a language and a database flexible enough to describe with minimal effort any sort of contexts however large in number of entities and however complex in terms of interdependencies between entities.
Also it would be great for the language to be as close as possible to a natural language in order to facilitate the learning of the system by a large number of students, programmers and business analysts.
For these reasons, at Ianta Labs we decided to use for our microservices market research project, a graph database – Neo4j – and its database query language – Cypher.
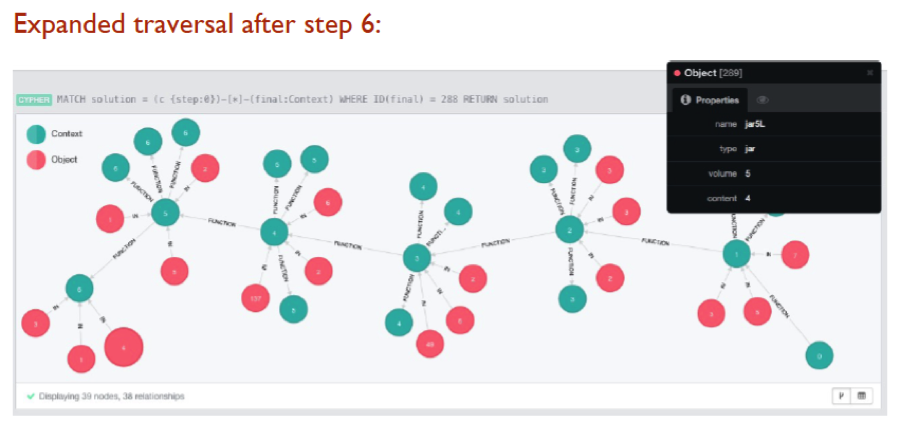
Solving the Three Jars Problem
In the rest of this first article, we’ll show at a high level how the system will work on a real non-programming demo problem.
We wanted to use a problem with non-obvious solutions but with a relatively small number of steps such that whomever interested would be able in a few minutes to solve it “manually.”
We settled for the problem of the three jars, which reads like this:
“Imagine you are selling lemonade and you have 3 jars of 3, 5 and 8 liters, with 8 liters of lemonade in the largest jar. A customer wants to buy 4 liters of lemonade. How would you measure 4 liters of lemonade for her?”
Here is what we thought Turing would have “looked” for in the actions of a problem solver.
First, the solver would have to define the initial context describing the three jars and their properties including at least volume and content.
Secondly, he would have to define the target context and/or the constraints (or tests) describing them.
Then the solver would have to identify the differences between the initial and the target contexts including specific entities and their properties that have to change during the solution steps. Next, he would need to search in memory for known actions (functions) that as a result will change those specific properties.
In case there are several actions, which change that property (content in our problem), he will have to decide on one to try first, likely based on a perceived effort/cost and/or duration.
Finally the solver would have to apply those actions to the initial context and test that the resulting contexts match the target.
When reaching a target context, he will just have to traverse back through previous intermediary contexts adding to a list the actions he used to “move” from one context to the other. That list will contain a solution of steps to solve the given problem.
It’s not difficult to write the Cypher pieces required to solve the three jars problem. Below are the first graph contexts we defined and then evolved and the traversal to the first solution:





We inserted the Cypher queries in a Java program, which automates the whole process and generates a solution:

The fun starts when you try to eliminate from the Java code all references to entities, properties and actions specific to the current problem in order to get a general algorithm. While it’s complicated and increasingly abstract, so far it still looks doable.
What’s Next for Cypher Microservices
In next week’s post, we’ll show how to add tables, HTML and source code files to the graphs describing contexts/states and how to build microservices to add, remove or change entities and properties of whatever nature (that is, a list of properties) in the graphs.
In the meantime, enjoy the sound and “dance” of pouring Java through Antlr4 into Neo4j in the video below. The parsed tree/graph is the one for the file Pour.java used as a microservice in the three jars problem above.
Learn how to solve problems just like this one using Neo4j. Click below to get your free copy of the Learning Neo4j ebook and learn to master the world’s leading graph database.
Catch up with the rest of this series on an automated market of Cypher-annotated microservices:
Share Article



Explore
Related Articles





