


Cypher: How to Rewrite a UNION Query Using a COLLECT Clause


6 min read
In Cypher, as in SQL, queries are built up using various clauses. One such clause is the UNION clause that we will discuss in this post.
The UNION clause is used to combine the similarly structured results of multiple queries and return them as one output. By default it returns the distinct values but with an UNION ALL you get all of them.
We are often asked how to do UNION post processing – like sorting, paginating or post-filtering – with the UNION results. Currently in order to do sorting or pagination, we have to apply these to all the partial queries in turn as a pre-processing, which of course takes you only halfway there, but not to the actual post-processing.
In this post we will discuss how we can do UNION post processing by rewriting the query using the COLLECT function and the UNWIND clause.
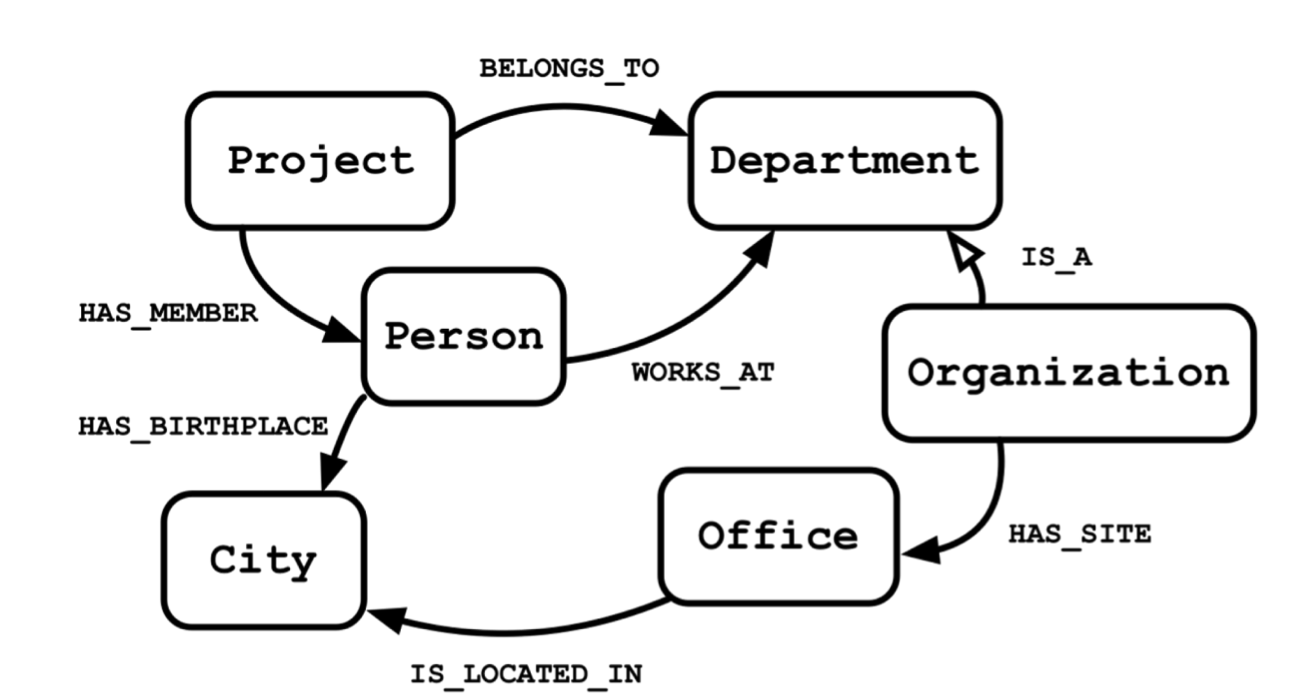
We will consider the following data model:
Problem Description:
We would like to get name of Person who works in the department that is led by “Scott” or name of the Person who works at the “Operations” department.
One of the ways to write a Cypher query for this problem statement is to use the UNION clause. Consider this example below:
match (n:Person)-[r:WORKS_AT]->(d:Dept)-[:LEAD_BY]->(m:Person) where m.name = "Scott" return n.name as name, r.hoursPerWeek as hourPerWeek UNION match (n:Person)-[r:WORKS_AT]->(d:Dept) where d.name = "Operations" return n.name as name, r.hoursPerWeek as hourPerWeek
Output of the query:
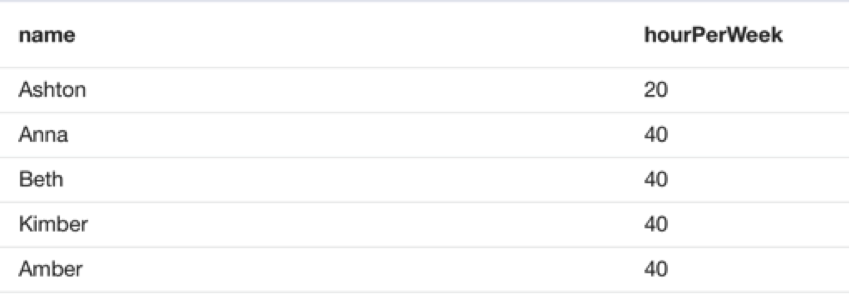
Now, since I can’t do UNION post processing such as sorting the data by name, I have to apply the ORDER BY clause as pre-processing to both queries that are part of the UNION clause. My query would change as follows:
match (n:Person)-[r:WORKS_AT]->(d:Dept)-[:LEAD_BY]->(m:Person) where m.name = "Scott" return n.name as name, r.hoursPerWeek as hourPerWeek order by name UNION match (n:Person)-[r:WORKS_AT]->(d:Dept) where d.name = "Operations" return n.name as name, r.hoursPerWeek as hourPerWeek order by name

As you can see in the output, sorting is not done correctly. “Ashton” comes before “Amber” in the output. That is because it sorts the first query and then sorts the second query and combines the results.
How can we resolve this issue? By using COLLECT and UNWIND as a power-combo. COLLECT collects values into a list (a real list that you can run list operations on). UNWIND transforms the list back into individual rows.
First we turn the columns of a result into a map (struct, hash, dictionary), to retain its structure.
For each partial query we use the COLLECT to aggregate these maps into a list, which also reduces our row count (cardinality) to one (1) for the following MATCH. Combining the lists is a simple list concatenation with the “+” operator.
Once we have the complete list, we use UNWIND to transform it back into rows of maps. After this, we use the WITH clause to deconstruct the maps into columns again and perform operations like sorting, pagination, filtering or any other aggregation or operation.
Here is the rewrite of the UNION query:
match (n:Person)-[r:WORKS_AT]->(d:Dept)-[:LEAD_BY]->(m:Person)
where m.name = "Scott"
with collect({name:n.name, hoursPerWeek: r.hoursPerWeek}) as rows
match (n:Person)-[r:WORKS_AT]->(d:Dept)
where d.name = "Operations"
with rows + collect({name:n.name, hoursPerWeek: r.hoursPerWeek}) as allRows
UNWIND allRows as row
with row.name as name, row.hoursPerWeek as hoursPerWeek
return name, hoursPerWeek
The first MATCH:
match (n:Person)-[r:WORKS_AT]->(d:Dept)-[:LEAD_BY]->(m:Person)
where m.name = "Scott"
with collect({name:n.name, hoursPerWeek: r.hoursPerWeek}) as rows
This query gets the Person’s data who works at department led by “Scott,” creates a map from the name and hoursPerWeek values and then collects them into a list called “rows.”
Then the second MATCH collects the information of the Person who works at “Operations” department and combines the list “rows” with the new list and adds them in “allRows.”
match (n:Person)-[r:WORKS_AT]->(d:Dept)
where d.name = "Operations"
with rows + collect({name:n.name, hoursPerWeek: r.hoursPerWeek}) as allRows
Now we UNWIND that large list as individual “row”s and return the data. (If we only want to return the data, we can combine the last WITH and RETURN into one.)
UNWIND allRows as row with row.name as name, row.hoursPerWeek as hoursPerWeek return name, hoursPerWeek
After the UNWIND and WITH clause we can also add all the UNION processing operations like sorting or any other aggregate functions.
So if we want to sort the data and aggregate the data for the rewritten query we can rewrite the same query but adding ORDER BY and an aggregation clause after the UNWIND and WITH as shown:
match (n:Person)-[r:WORKS_AT]->(d:Dept)-[:LEAD_BY]->(m:Person)
where m.name = "Scott"
with collect({name:n.name, hoursPerWeek: r.hoursPerWeek}) as rows
match (n:Person)-[r:WORKS_AT]->(d:Dept)
where d.name = "Operations"
with rows + collect({name:n.name, hoursPerWeek: r.hoursPerWeek}) as allRows
UNWIND allRows as row
with row.name as name, row.hoursPerWeek as hoursPerWeek
return name, sum(hoursPerWeek)
order by name
A short variant of this query would look like this:
match (n:Person {name:"Scott"})-[r:WORKS_AT]->(d:Dept)-[:LEAD_BY]->(m:Person)
with collect({name:n.name, hoursPerWeek: r.hoursPerWeek}) as rows
match (n:Person)-[r:WORKS_AT]->(d:Dept {name:"Operations"})
WITH rows + collect({name:n.name, hoursPerWeek: r.hoursPerWeek}) as allRows
UNWIND allRows as row
RETURN row.name as name, sum(row.hoursPerWeek) as hoursPerWeek
order by name
Want to learn more about graph databases and Neo4j? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technologies for your mission-critical application today.
Share Article



Explore
Related Articles

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.




