
Dependency Management with Neo4j at the Royal Bank of Scotland

Senior Engineer, Royal Bank of Scotland (RBS)
5 min read
Editor’s Note: This presentation was given by Stelios Gergiannakis at GraphConnect Europe in April 2016. Here’s a quick review of what he covered:
- The legacy deployment process at RBS
- Challenges with integration in dependency management
- Why the RBS team chose Neo4j for automated deployments and dependency management
- Future automated deployment projects at RBS Group
–
Today I’m talking about how we used Neo4j to more effectively deliver our software to production at the Royal Bank of Scotland.
Our Legacy Deployment Process
About two-and-a-half years ago, we decided to revamp our single-dealer platform called Agile Markets, a cluster of applications. To do this we created Zambezi, our home-grown, open source-style framework that accelerates the delivery of electronic customer experiences, or as we call them, digital channels. It relies on HTML in the front end and microservices in the back end.
We have a huge bank, and the numbers are sometimes mind boggling. We have 10 or 20 different delivery teams just for Agile Markets, so our number of developers was already up in three digits. But we created the Zambezi platform and gave it to our developers to “create some magic.”

But it wasn’t all sunshine and roses. We inherited a legacy deployment process, which included manual deployment with raising change requests and iTasks for different isolated installation teams. It often felt like we were trying to play football [soccer] uphill.
We were getting to the point where the legacy deployment process was causing butterfly effects. We would deploy a library to UAT, development, production and then make a few minor changes that had major and unintended ramifications.
As a bank, we at RBS are highly regulated and frequently received questions from our customers. We would often find ourselves feeling tangled inside this spider web of dependencies, teams and artifacts. We were constantly being slowed down, and we knew we had to do something different.

The Challenge of Integration in Dependency Management
To solve these problems, we created a tool called Dart — “Damn, another release tool.” Because there wasn’t a tool out there, like TeamCity, that we could have used? And we tried. We created hooks on TeamCity and implemented automated deployment, but due to the size of our company, we couldn’t make it work for us.
In our case, we had to integrate with existing GoldenSource systems that included everything inside the bank such as teams, users and hosts. We also wanted to expose the information and interact with Dart through a REST API, and keep ourselves from becoming restricted in the future in terms of a UI versus a mobile client.
We started by integrating all the components with existing legacy deployment tools in a piecemeal fashion, and then determined how to phase them out. And above all, we had to make sure we were moving towards our strategic goal: cloud deployment.
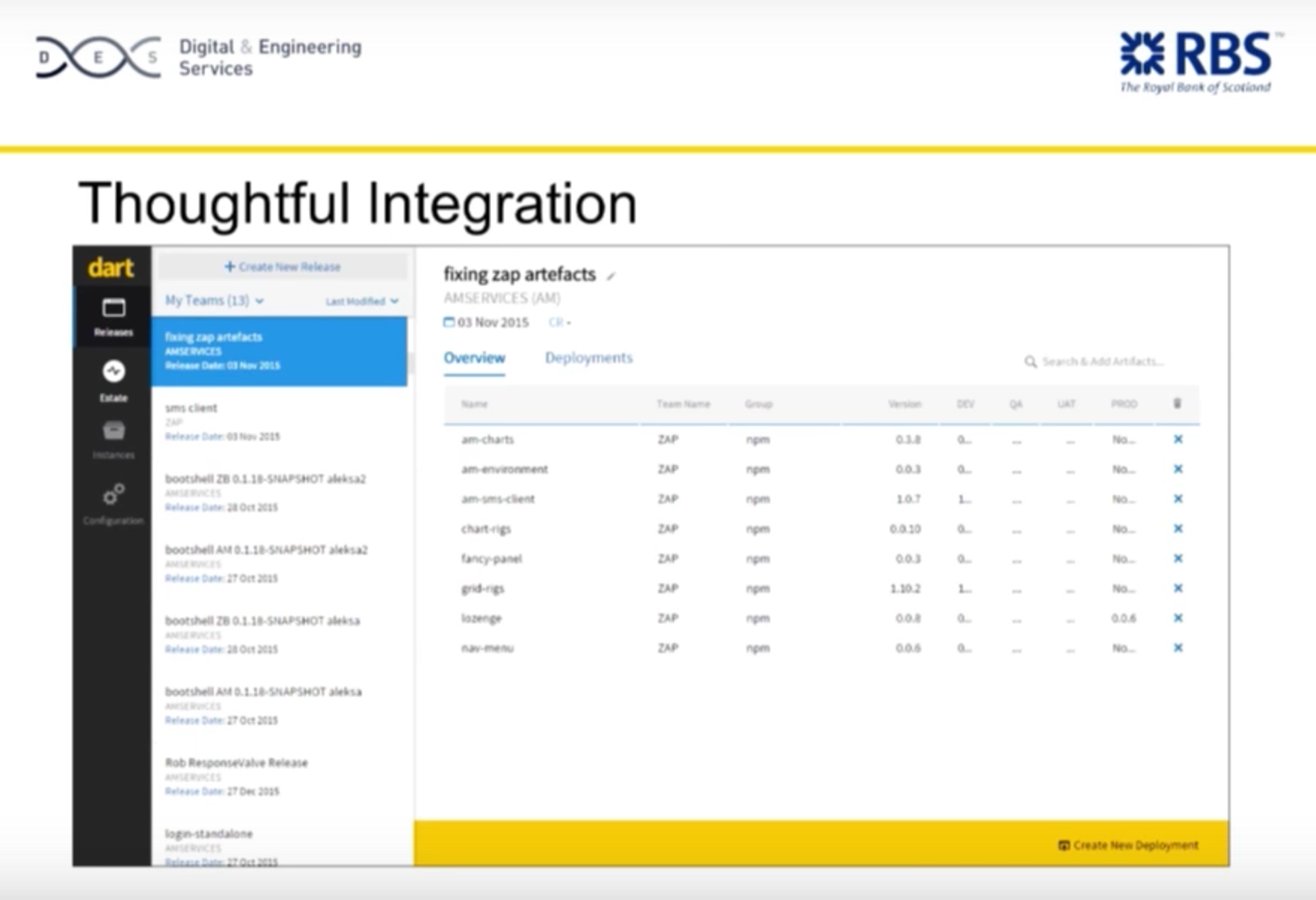
Dependency Management + Neo4j at RBS
We needed full flexibility and control, and it became clear that starting with a tool that already existed would require us to completely rewrite it. It’s for this reason that we decided to start from a clean slate.
This is all powered by Neo4j. Why?
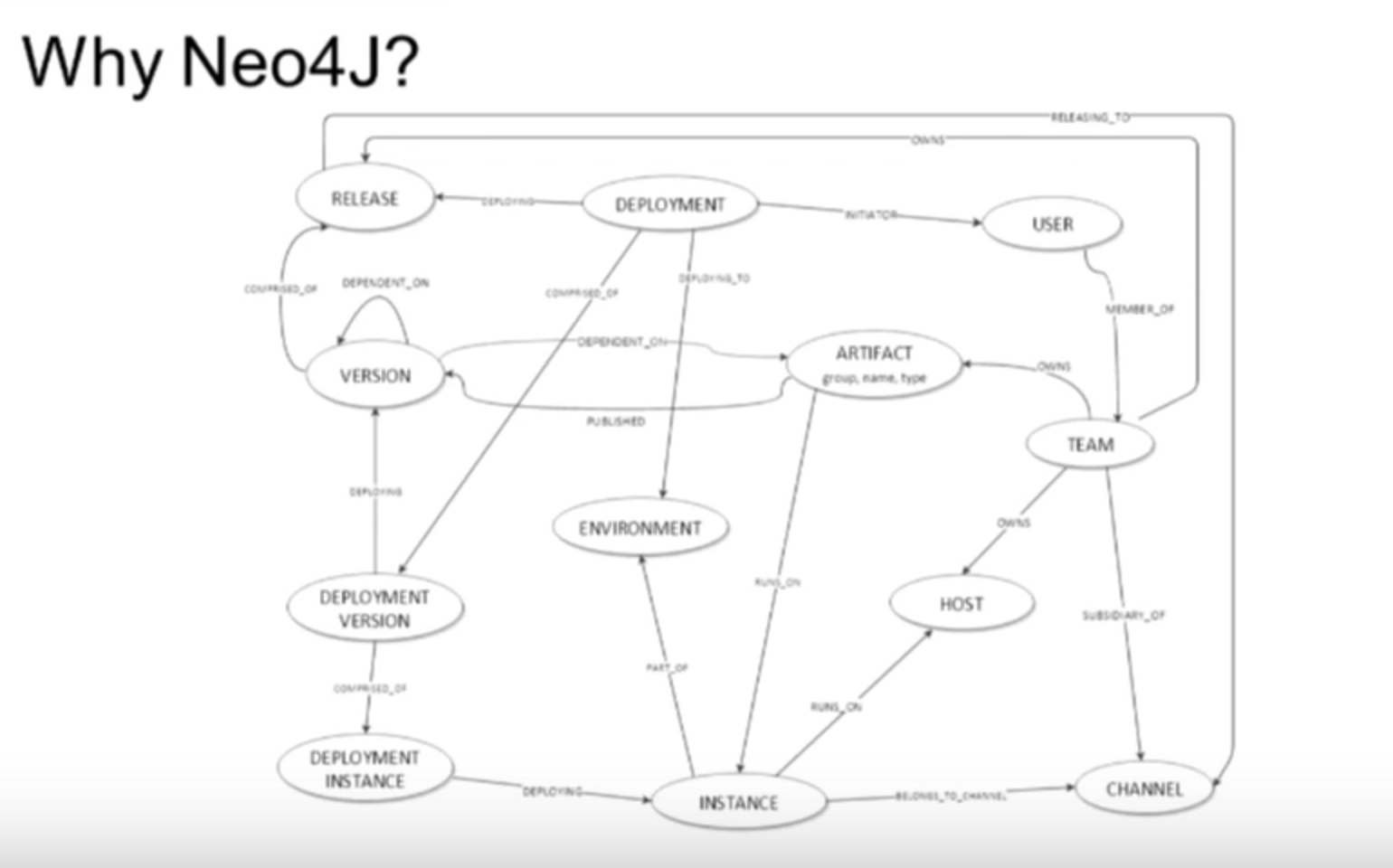
Our whole process started by sitting down in front of a whiteboard and asking: what are our requirements? What’s our business model? What do we want to support? And we started drawing something that wasn’t too different from what you see here — a conceptual dump or schema — of our current graph database:
We saw that this could be modeled as an entity-relationship diagram (E-R diagram), but that felt like trying to fit a square peg into a round hole. It was also necessary that we be able to change our data model easily and on a continuing basis. Neo4j gives us the flexibility to continually make these changes, something that isn’t possible with a relational database (RDBMS).
Another strong feature of Neo4j is Cypher. In the below queries, we started from an environment and returned everything attached to the environment at a depth of two relationships. And we wanted to have a true state query so that we could determine what was deployed where and when.
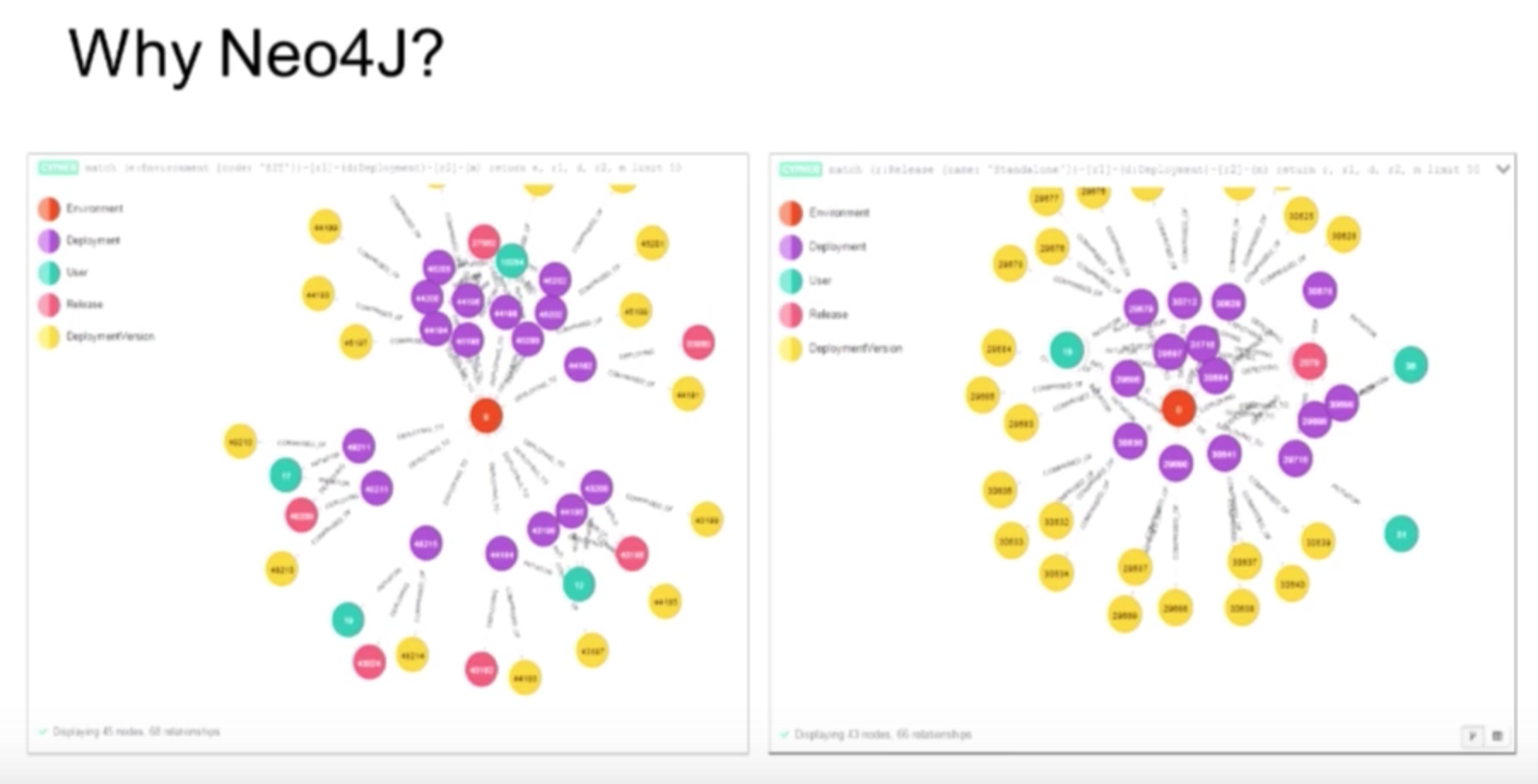
We were lost when we tried to express that as an SQL query. I don’t know how many lines of JOINs — inner JOINs and outer JOINs — SQL required, but in Neo4j it was just natural.
But the most important benefit was how easy it was to integrate everything with Neo4j. We aspire to have a true microservices architecture. We wanted to be able to deploy Dart as another microservice.
It’s very easy to embed Neo4j in your service and spin up a cluster without any external housekeeping service required. We knew this would be incredibly important when deploying our conceptual services to the cloud because it would deploy as one package.
This made us feel empowered. Now we could type in a few keystrokes to find out what was deployed and where, who did the deployment and when. It also allowed us to turn back the clock and explore the prior state of our environment at a specific moment in time — for example, yesterday at 3:00 p.m.
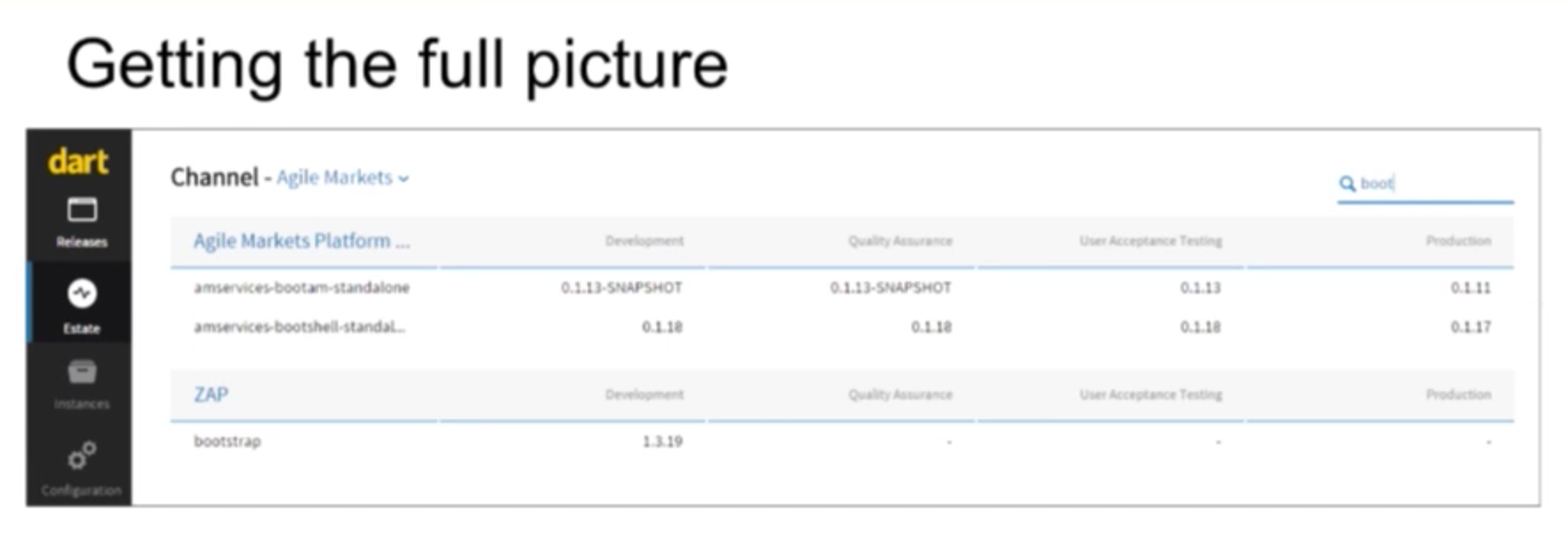
Even more importantly, we can implement early warning systems. We have information from the NPM registry, artifacts and the artifact dependencies.
You can determine the impact of upgrading a certain code library by determining how many people are using it, which other apps you need to examine to determine whether or not you can safely duplicate it. And all the information was readily available:

The Future of Automated Deployments at the RBS Group
We feel this has been a huge success. Over the past seven months, usage has grown by 50% each month. People find it easier to automate their deployments and push things into development and user acceptance testing (UAT), which translates to increased developer productivity.
We’re rolling this out to all of the organizations in the RBS group — such as Lombard Insurance, NatWest, AloStar Bank — so in the end our internal market is going to be roughly 10,000 developers. While we’re currently at tens of deployments per day, we want to move to hundreds of successful deployments per day. With this knowledge, we can take things to the next level.
We can perform cascaded regression testing to all the downstream apps to make sure that the library works for everyone before it potentially breaks down the target environment we’re aiming for. We can now also measure analytics on things such as productivity and where most of the deployments are happening in each environment.
Most importantly, now that everyone is using this common tool, it’s much easier to move everyone to the cloud. Having everyone on the same page, and then move everyone together to a Platform-as-a-Service (PaaS) infrastructure — OpenShift, containerized deployments, hybrid infrastructure — which before would just be a dream.
The major takeaway from all of this is that there are friction points in even the slightest things — like building artifacts and pushing them into an environment — and not everything is well oiled. But there are tools out there, like Neo4j, that can help you identify these pain points, solve your problems and generate additional information.
Inspired by Stelios’ talk? Click below to register for GraphConnect San Francisco and see even more presentations, talks and workshops from the world’s leading graph technology experts.
Share Article



Explore
Related Articles


Text2Cypher Across Languages: Evaluating Foundational Models Beyond English



