Architecting graph-based agentic system: When a regulator asks “Why was this loan approved?”

Solutions Engineering Leader for ANZ, Neo4j
11 min read
LoanGuard AI: Graph-based agentic AI for compliance & investigation – Part 1 of 2

There’s a question that doesn’t get asked often in financial services.
But when it does, everything stops.
Why was this loan approved?
Not did it meet the checklist.
But: walk me through the reasoning.
Show me how this borrower, with this Loan-to-Value Ratio (LVR), was assessed against the standards that applied to them. Show me the chain.
The teams that get asked this are rarely unprepared. They know the rules. The process was followed.
The problem is that nothing was built to hold it together.
- The reasoning lived in analyst notes.
- The policy lived in a PDF.
- The approval lived in a workflow tool that recorded what happened, not why.
All the right pieces existed. They just weren’t connected.
That gap isn’t a compliance failure. It’s a structural one. And as AI becomes part of the picture across every regulated industry, that gap is only going to grow.
That’s what LoanGuard AI is built around. A knowledge graph-based agentic AI system for loan compliance monitoring and financial crime investigation in Australian financial services. Checking loan applications against Australian Prudential Regulation Authority (APRA) prudential standards (Australia’s banking regulator, similar to the OCC or EBA), surfacing risk signals across borrower networks, and writing every decision back to a knowledge graph with full reasoning chains and cited evidence.
The goal was never a score. It was an answer.
This is Part 1 of that architecture.
Explainability is an architectural decision
There’s a common assumption in AI development that explainability is something you layer on top.
Build the model. Tune the outputs. Then add explainability after the fact.
That assumption is the challenge.
Explainability isn’t a feature. It’s a consequence of how a system is designed. If the connection between a decision and the rule that governed it doesn’t exist in the system, you can’t retrieve it at query time. You can approximate it. You can infer it. But you can’t trace it.
Traceability has to be structural. It has to be designed in.
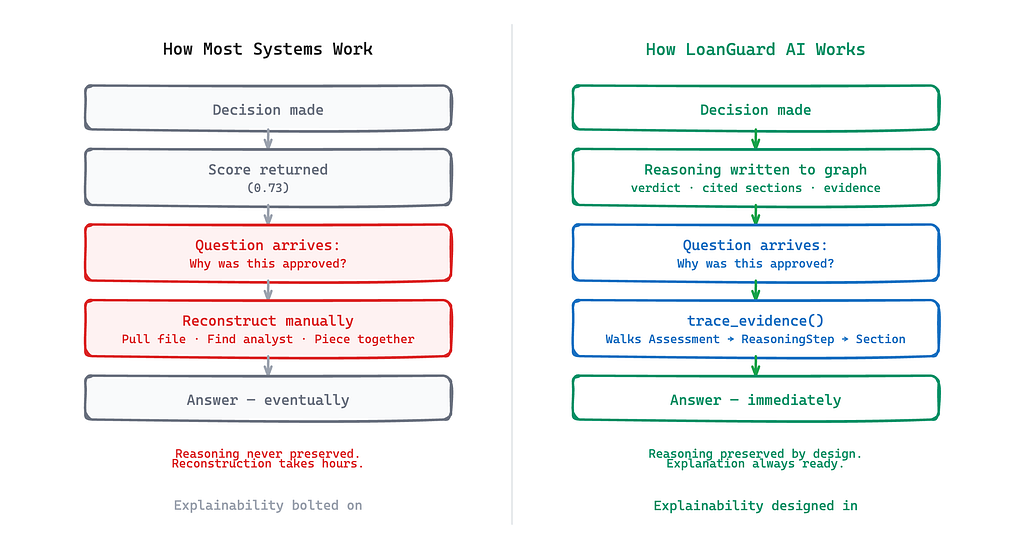
The question that shaped LoanGuard AI wasn’t “how do we make outputs more explainable?”
It was: “How do we build a system where the explanation is already there, waiting to be retrieved?”
The answer is a graph.
Why knowledge graph for compliance and investigation?
Most data systems are built for storage and retrieval. A graph is built for connection.
In a typical lending environment, the borrower lives in a CRM. The policy lives in a document repository. The approval lives in a workflow tool. They reference each other but they aren’t connected. To answer a question that crosses those boundaries, someone has to do the joining manually.
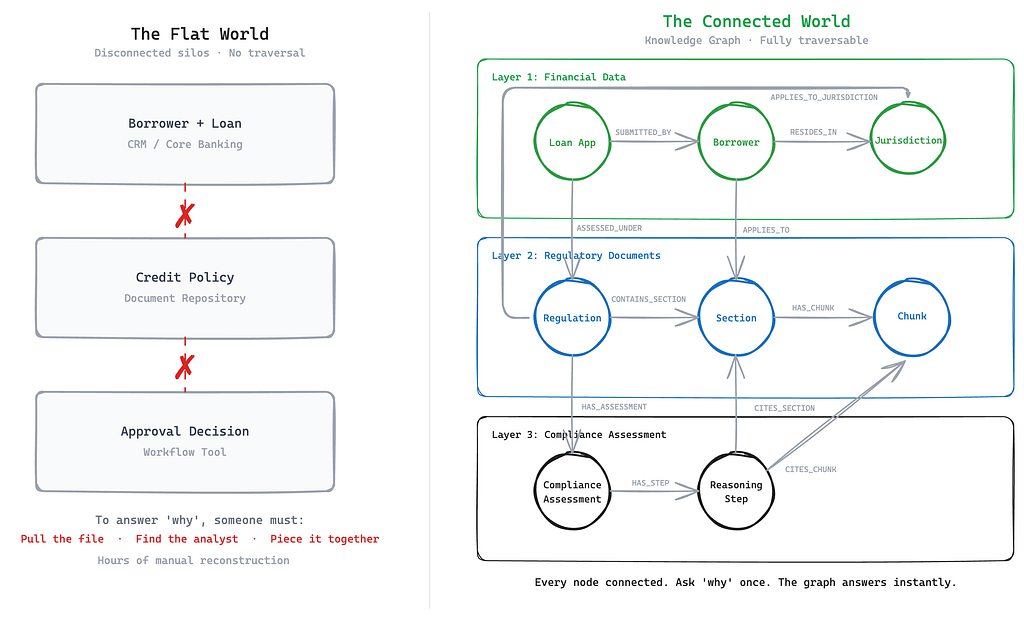
A knowledge graph changes that. Every entity, every relationship, every rule exists as a node, connected, traversable, queryable in a single step.
In LoanGuard AI, the graph spans three layers.
- Layer 1 holds the financial entities: the borrower, the loan application, the jurisdiction.
- Layer 2 holds the regulatory knowledge: APRA standards parsed into regulations, sections, and embeddable chunks.
- Layer 3 holds the runtime results: compliance assessments and the reasoning steps that produced them, each one citing the exact section it drew from.
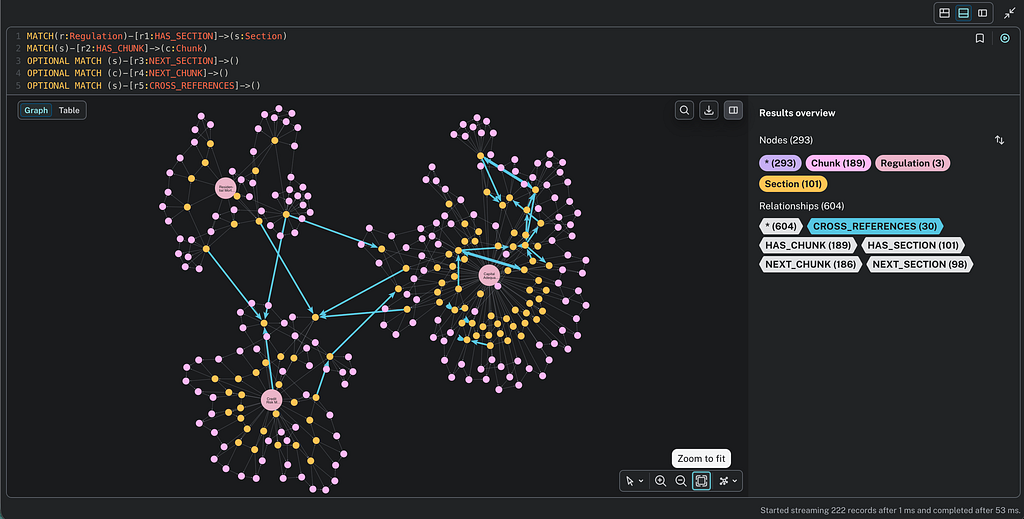
When a compliance officer asks “Is this loan compliant?”, the system traverses from loan application, down through regulation, all the way to the compliance assessment and every reasoning step in between.
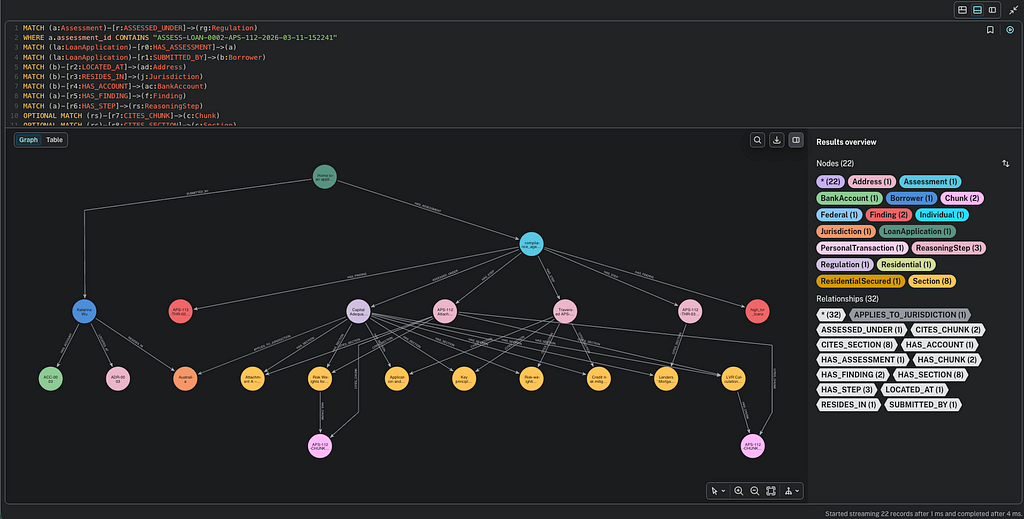
That traversal is the business value. Faster investigations. Audit readiness built into the system rather than assembled before every review cycle.
A vector database can find relevant text. Only a graph can tell you why a specific borrower, under a specific regulation, received a specific verdict.
That distinction matters enormously in a regulated industry.
How I designed LoanGuard AI

The system has two agents sitting behind an orchestrator. When a query comes in, the orchestrator reads the intent (using claude-haiku-4–5) and routes it: compliance check, financial crime investigation, or both.

Compliance agent
The Compliance Agent takes a loan application, traverses the graph to find the applicable APRA standards, retrieves the relevant regulatory chunks, and runs a structured assessment against each requirement.
It checks capital adequacy thresholds under APS-112, mortgage lending controls under APG-223, and credit risk management obligations under APS-220.
Every finding is written back to Layer 3 as a reasoning step with a cited source, a compliance status, and the specific threshold it was assessed against.

Investigation agent
The Investigation Agent does something different. It looks for patterns across borrower networks: shared accounts, linked entities, transaction timing, jurisdiction mismatches. The kind of signals that only become visible when the data is connected. A single loan application might look clean in isolation. Across a network of related entities, the picture changes.
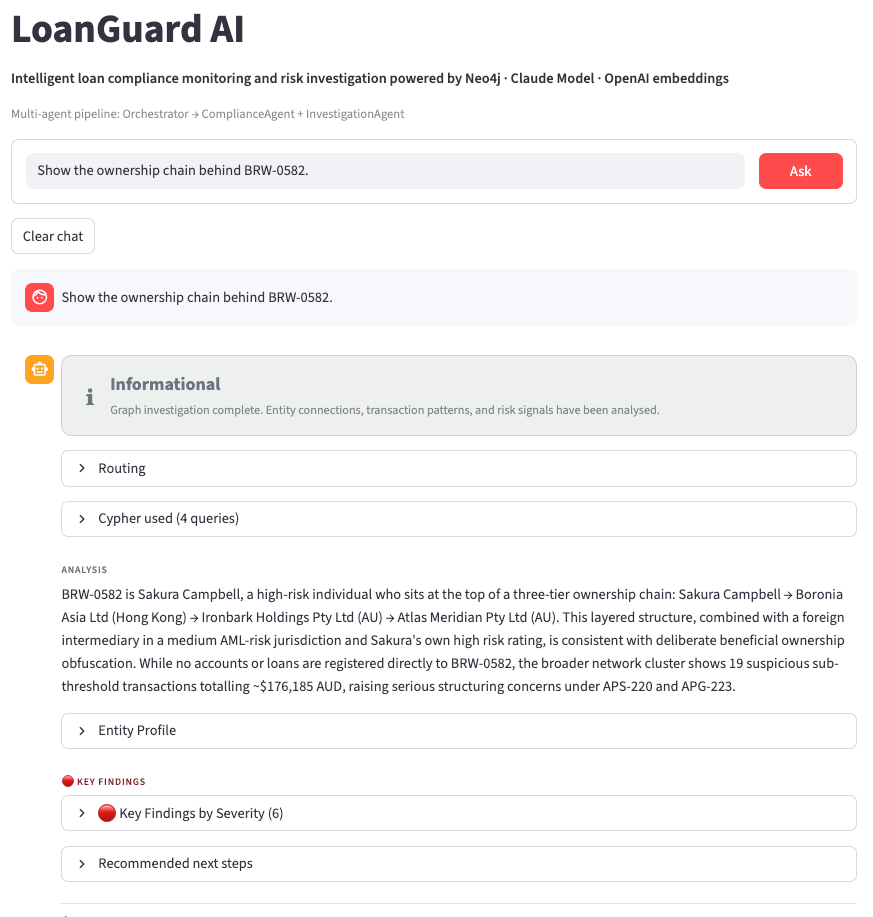
Three layer graph
The three-layer graph data model is what makes this possible.
- Layer 1 stores the structured financial loan data: the borrower, the loan, the accounts, the jurisdiction.
- Layer 2 stores the regulatory knowledge: APRA standards parsed into structured nodes, with sections, thresholds, and requirements each existing as traversable entities rather than buried text.
- Layer 3 stores the runtime truth: every assessment, every finding, every reasoning step, written back to the graph at query time with a cited source and a compliance verdict.
The graph doesn’t just hold the answer. It holds the chain of reasoning that produced it.
Both agents use claude-sonnet-4-6 model as the reasoning engine, with temperature set to zero. Consistency matters more than creativity when you’re writing compliance verdicts.
Prompt caching is applied to the Compliance Agent, where the regulatory context is large and largely static across requests.
The graph is the memory. The agents are the reasoning. The orchestrator is the intent router. Each layer does one thing well.
The full source code is available on GitHub.
Three design decisions I’d make again
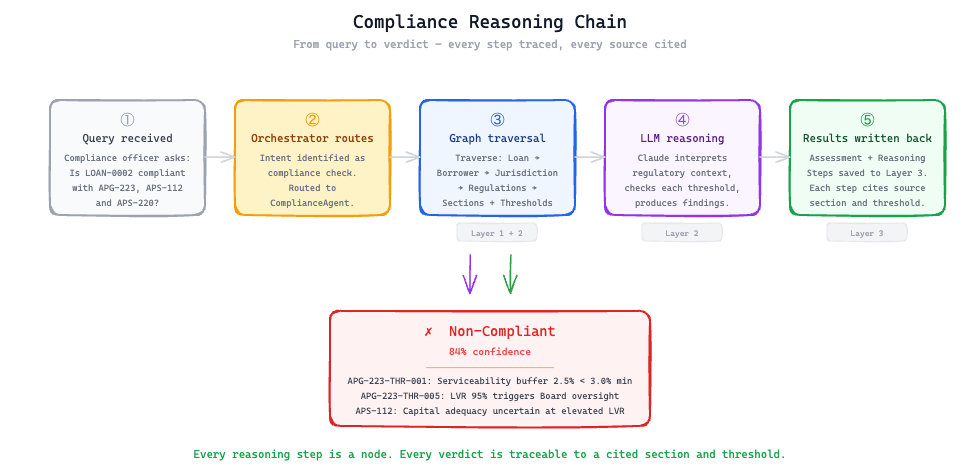
1. Write every reasoning step back to the graph.
Not just the verdict. Every step. The section cited, the threshold checked, the value observed, the conclusion reached.
This is what makes the system auditable.
A compliance officer can open any assessment and follow the chain: here is the regulation that applied, here is the threshold, here is how this borrower’s LVR was measured against it, here is why it passed or failed.

You can reconstruct any decision from first principles, without relying on analyst notes, without pulling a file, without finding the person who ran the original check.
2. Separate retrieval from reasoning.
The graph retrieves the relevant regulations. The LLM reasons over them. These are two different jobs, and mixing them creates systems that are hard to debug and harder to trust.
When retrieval and reasoning are distinct, failures are traceable.
If the verdict is wrong, you check the retrieval first: did the graph return the right regulatory context?
If yes, you check the reasoning: did the LLM interpret it correctly? Separation gives you a clean fault boundary. That matters in a production compliance system more than it matters almost anywhere else.
3. Parse APRA standards as structured nodes, not raw documents.
Chunking regulatory PDFs into embeddable text gets you semantic search. Parsing them into a graph gets you structure: which section sits under which regulation, which threshold applies under which condition, which requirements are enforceable versus advisory.
That structure is what enables precise, citation-level compliance verdicts rather than approximate matches. When the system says a loan fails APS-112 Section 4.2, it means it. The section is a node. The threshold is a node. The relationship between them is traversable. There is no ambiguity about what was assessed or why.
From architecture to business value
The business value shows up differently depending on who’s asking.

The common thread is explainability at query time. Not reconstructed after the fact. Not approximated from logs. Already there, waiting to be retrieved.
For compliance teams, that means investigations that take minutes rather than days. For auditors, it means a system that can answer questions without requiring someone to reassemble the reasoning from scratch. For executives and risk committees, it means confidence that when a regulator asks why, the answer is structurally available, not dependent on institutional memory.
This is the shift that matters: from systems that record what happened, to systems that preserve why.
What I learned building this
The data model is the system.
The hardest part wasn’t the AI. It was the data modelling.
Getting the three-layer graph architecture right, deciding what lives as a node versus a property, figuring out how reasoning steps should connect back to regulatory chunks, determining the right granularity for APRA sections.
That work happens before you write a single line of agent code, and it determines everything downstream. A poorly modelled graph produces well-structured confabulation. A well-modelled graph produces auditable truth and lends itself well to a well designed application.
Explainability is a forcing function for quality.
When every verdict has to cite a source, vague or hallucinated reasoning becomes immediately visible. You can’t hide imprecision behind a confidence score. The requirement to explain forces the system to be precise, and precision forces the data model to be systematic.
Keeping retrieval and reasoning separate pays off at debug time.
It’s tempting to let the LLM handle everything in a single call, especially when early results look promising. But when something goes wrong in a compliance system, you need to know exactly where.
In LoanGuard AI, the graph handles retrieval: traverse from loan application to jurisdiction, pull the applicable APRA regulation, return the relevant section and threshold.
The LLM handles reasoning: interpret that context, apply it to the borrower, produce a verdict with a cited source.
When a verdict is incorrect, the fault boundary is clear. Either the graph returned the wrong regulation, or the LLM misread the right one. That clarity matters in a regulated environment where you need to explain not just what the system decided, but how.
Call to action
LoanGuard AI isn’t a chatbot on top of documents. It’s a system where financial data, regulatory knowledge, and compliance reasoning are structurally connected, and where every answer comes with a traceable chain of evidence.
That’s what it looks like when explainability is designed in from the start, not bolted on after the model is already running.
The question I keep coming back to: in the systems your organisation is building today, where does the reasoning actually live? Is it retrievable, or does someone have to reconstruct it?
Part 2 goes inside the system: the agent pipeline, the Cypher retrievers, the prompt architecture, execution details and improvements from the last iteration. Coming next.
If you want to explore the architecture before Part 2, the repo is here: GitHub.
Architecting Graph-Based Agentic System: When a Regulator Asks “Why Was This Loan Approved?” was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher




