


Context Graphs and AI Memory Across the Globe



8 min read

From Berlin to San Francisco
On the same day, two technical communities one in Berlin and one in San Francisco gathered to discuss the same architectural question: how should memory be designed for agentic AI systems?
In Berlin, AI Memory and Founders Night brought together founders, engineers, and architects working on production AI systems. At the same time, the inaugural Context Graph Meetup in San Francisco convened researchers and practitioners exploring context graphs as an emerging architectural pattern. The speakers, the cities, and the formats were different, however the conclusions were remarkably aligned.


What Is a Context Graph?
The San Francisco meetup opened with Will Lyon establishing a working definition: a context graph is a knowledge graph that contains all the information necessary to make decisions throughout an organization, with decision traces connected to entities, policies, and precedents in a single queryable structure.
Jessica Talisman articulated that what the industry is now calling a context graph has traditionally been known in knowledge management as procedural knowledge, and the concept of context itself — meaning derived from relationships between things — is precisely what graphs have always been built to represent.
Yann Bilien described a context graph as the sum of two graphs: a knowledge graph and a graph of actions and processes.
Dave Bennett framed it as a matter of dimensionality — a knowledge graph is a superset, and the context graph adds extra dimensionality beyond the simple triple: decision traces, provenance, and temporal validity.
Emil Eifrem offered practical framing: take your domain data, model it in graph form, and when you connect the decision traces on top of that knowledge graph, that is a context graph.


The Berlin discussions arrived at a similar working definition from a different angle. Berlin’s practitioners dove into what the pattern needs to do: preserve explicit connections between entities ownership, hierarchy, dependency, temporal sequence that vector retrieval alone cannot encode.
Both communities landed in the same place. The value of a context graph lies in connecting structured domain knowledge to the history of how decisions were made, in a form that is queryable, traversable, and auditable.
Why AI Memory Is Moving to the Center
Over the past year, many AI applications have relied only on retrieval-augmented generation. While vector search is effective for retrieving semantically similar content, it does not preserve structured relationships between entities.
As systems become more agentic, capable of planning, using multiple tools, and coordinating multi-step tasks, teams in both Berlin and San Francisco described encountering the same recurring limitations: memory that does not persist across sessions, relationships between entities that are implicit rather than explicit, and reasoning chains that cannot be inspected or audited.
Several attendees highlighted Andreas Kollegger’s session (Neo4j) on context graphs as particularly clarifying. While vector search remains effective for semantic retrieval, context graphs make relationships between entities explicit — enabling agents to reason across workflows, systems, and evolving context.


Emil Eifrem framed the structural gap clearly during the San Francisco panel. Agents need four things to be useful in production: access to systems of record, access to data platforms, agentic memory for conversational and session state, and a fourth piece that has lacked a clear name until recently the decision traces and institutional knowledge that encode how an organization actually operates.
Will Lyon highlighted this as well, as noted that in The State of AI in Business 2025, a report done by MIT, 95% of AI projects fail to deliver value, and that the root cause is agents not having access to the right context.


This Is a Knowledge Management Problem
The most substantive challenge raised across the San Francisco meetup and one that resonated through the panel discussion was that building a context graph is not primarily an engineering problem.
It is a knowledge management problem. Jessica Talisman drew on peer-reviewed research with the Sephrial group on Procedural Knowledge Ontologies, citing deployments at Siemens, Belco, and Bosch to this argument directly: decision traces are not data, they are knowledge, and capturing them requires knowledge elicitation, formal encoding, and ontologies disciplines that most engineering teams are not applying.
Her prescription was practical: build the knowledge model before the persistence layer, invest in elicitation infrastructure that involves humans, and treat knowledge capture as the primary objective rather than just execution traces.
The concluding panel reinforced this point broadly. The reason most context graph initiatives jump straight to the operational layer capturing execution traces without doing the foundational work is that knowledge management is genuinely difficult and has historically been under-invested across organizations. So what does it look like when we do it right?
Building Context Graphs in Production
Yann Bilien (Rippletide) emphasized that contradictions must be resolved at build time rather than inference time. If two data sources disagree on a policy detail, that inconsistency needs to be handled during graph construction, not left for a language model to arbitrate at runtime. And Dave Bennett (Indykite) demonstrated that governance must be designed in from the start: his live demo showed how full delegation chains, built using OAuth token exchange, tie every agent action back to the originating human user, with the same query correctly blocked for one user and permitted for another based on department-level graph policies.
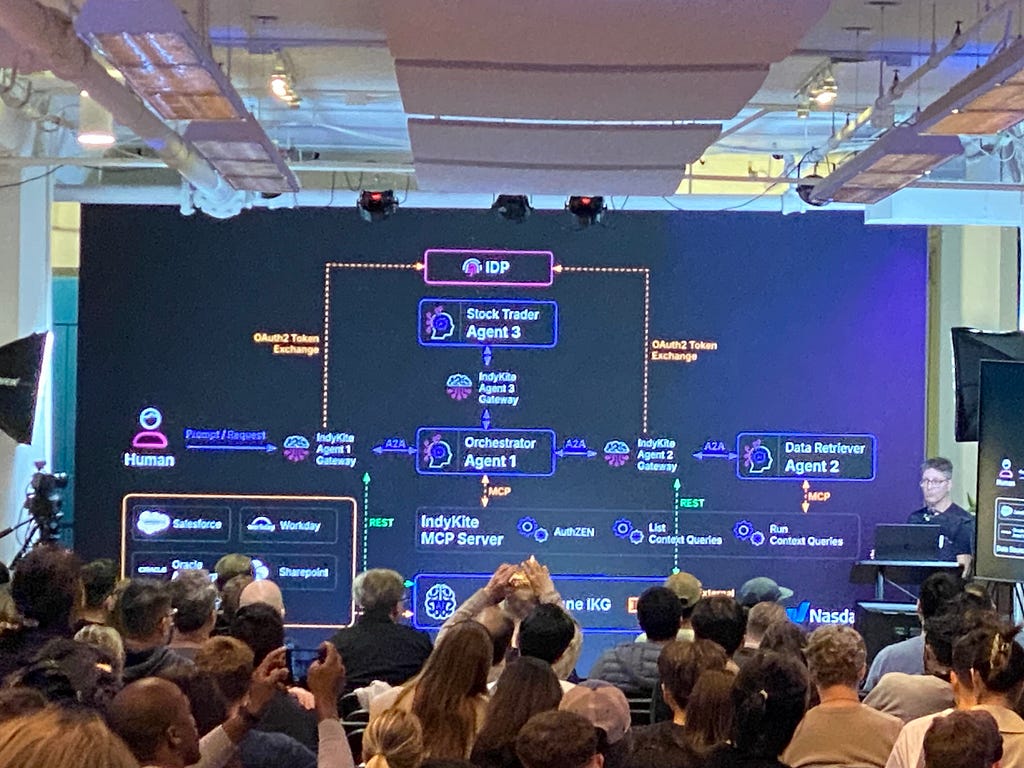

Both themes, build-time rigor and runtime governance, echoed the focus Berlin practitioners brought to questions of traceability and audit paths in production systems.
Insights from the Berlin AI Builder Community
Many of the most valuable insights from the Berlin event emerged during discussions between sessions, where builders compared how they are currently designing memory layers for agentic systems.
From the ecosystem perspective, Wynand Viljoen (Delta Campus) framed the broader opportunity for founders and builders: as AI development accelerates, the architectural choices teams make today will shape the reliability and trustworthiness of the systems they deploy.

Abdel Sghiouar (Google) sparked conversations about the operational realities of agentic AI. His session focused on how to safely execute agent-generated code and maintain control when systems become increasingly autonomous.
Participants also pointed to Christian Glessner’s talk (Microsoft MVP) on building agents with Microsoft Foundry, which connected memory architectures with practical developer tooling and real implementation patterns.


The Direction Is Aligned
What stands out from both events is not simply that two communities discussed similar ideas on the same day. It is that independent engineering communities working in different contexts, on different problems, in different parts of the world are arriving at the same architectural conclusions.
The emerging pattern looks increasingly consistent: models generate responses, agent frameworks coordinate workflows, a structured memory layer maintains entities and relationships, and governance and execution layers ensure safety and reproducibility. Within this stack, context graphs are becoming central to the memory layer.
Emil Eifrem’s closing vision from the San Francisco panel captured the direction well: the ideal future is one where encoding institutional knowledge and decision traces into a structured layer becomes standard hygiene in building AI-capable software as unremarkable as writing unit tests.
From Berlin to San Francisco, the direction is aligned. The patterns are converging. Let’s start building.
Thank You to Our Speakers, Partners and Friends
In Berlin, AI Memory and Founders Night brought together: Neo4j, Delta Campus , Cognee, Riverty, MemVerge, AWS, Microsoft, Google, Global AI Community and the Google Developer Group Cloud Berlin community for helping create such an open and thoughtful environment for discussing AI memory and context graphs.
In San Francisco, the Context Graph Meetup brought together an equally passionate community. A big thank you to our speakers and contributors from Neo4j, Contextually, Indykite, and Rippletide, who shared their cutting-edge research on context graphs as a core architectural pattern for agentic AI systems.
Both events were made possible by the incredible collaboration between speakers, partners, and developer communities who are actively shaping the future of AI systems.

Context Graphs and AI Memory Across the Globe was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles




Graph-Driven AI for All: Neo4j Aura Agent Enters General Availability
