








From Legal Documents to Knowledge Graphs

Graph ML and GenAI Research, Neo4j
10 min read
This blog post was co-authored with Tuana Çelik
Create a free graph database instance in Neo4j AuraDB
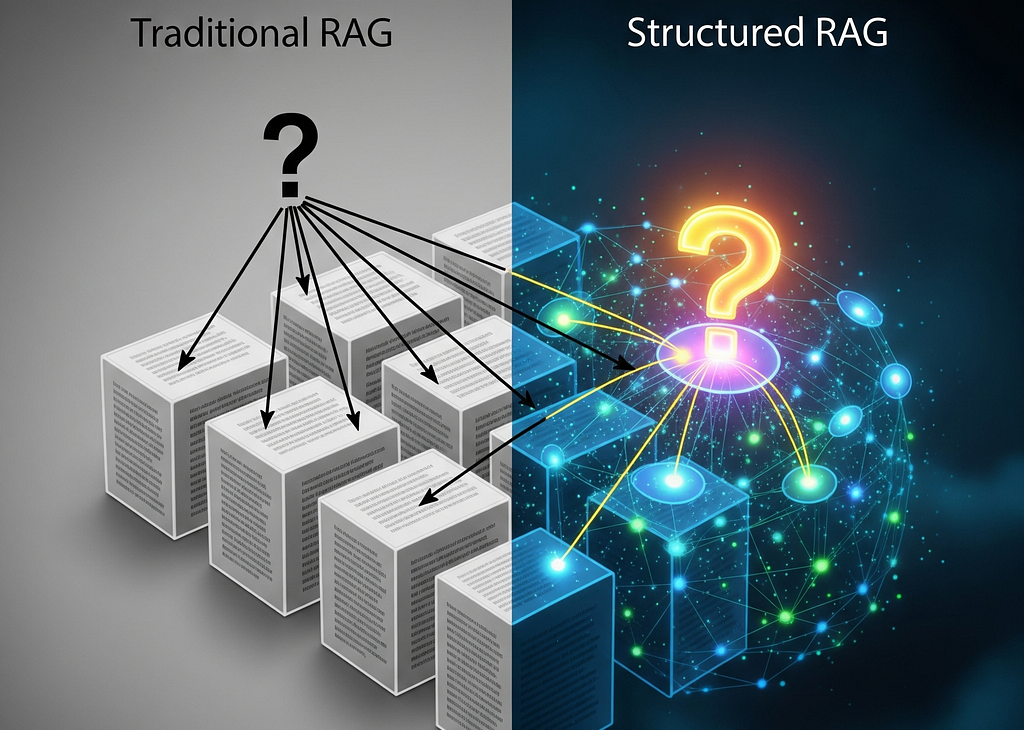
Retrieval-augmented generation (RAG) has emerged as a powerful technique for enhancing LLMs with external knowledge, but traditional vector-based RAG approaches are increasingly showing their limitations when dealing with complex, interconnected information. Simple semantic similarity searches often fail to capture nuanced relationships between entities, struggle with multi-hop reasoning, and can miss critical context that spans across multiple documents.
While there are various approaches to address these challenges, one particularly promising solution lies in structuring data to unlock more sophisticated retrieval and reasoning capabilities. By transforming unstructured documents into structured knowledge representations, we can perform complex graph traversals, relationship queries, and contextual reasoning that goes far beyond simple similarity matching.
This is where tools like LlamaCloud become invaluable. It provides robust parsing and extraction capabilities to convert raw documents into structured data. Neo4j serves as the backbone for knowledge graph representation, forming the foundation of GraphRAG architectures that can understand not just what information exists but how it all connects together.
The legal domain represents one of the more compelling use cases for structured data approaches to RAG, where the accuracy and precision of information retrieval can have significant real-world consequences. Legal documents are inherently interconnected, with complex webs of references between cases, statutes, regulations, and precedents that traditional vector search often fails to capture effectively. The hierarchical nature of legal information, coupled with the critical importance of understanding relationships between entities, clauses, and legal concepts, makes structured knowledge graphs particularly valuable for improving retrieval accuracy.
To demonstrate this potential, we’ll walk through a comprehensive example of legal document processing that showcases the full pipeline shown below.
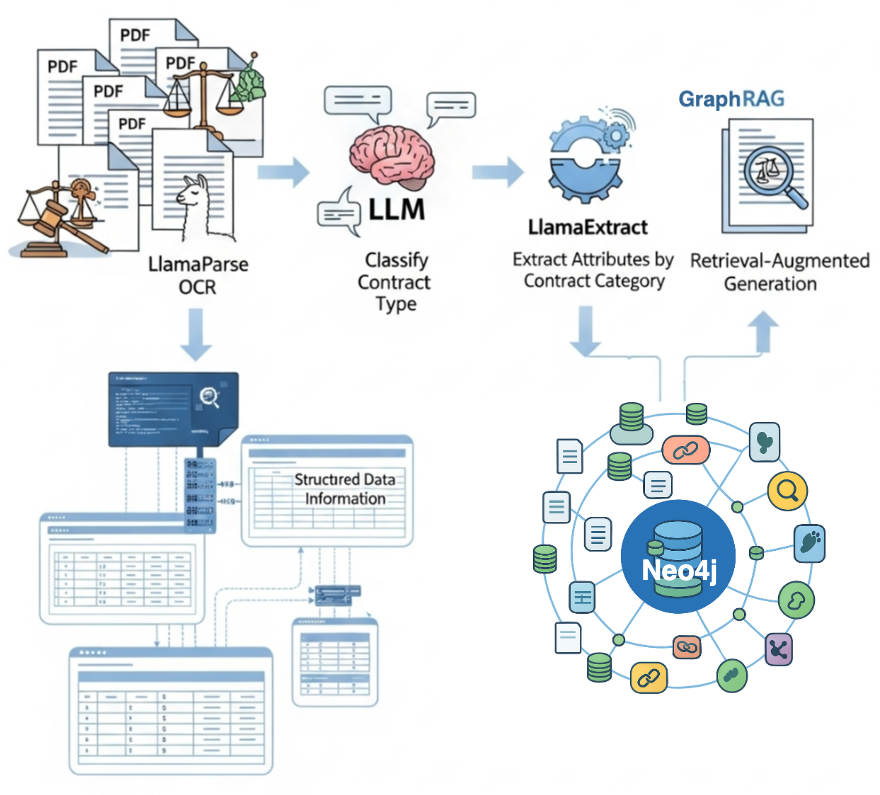
The pipeline process:
- Use LlamaParse to parse PDF documents and extract readable text.
- Employ an LLM to classify the contract type, enabling context-aware processing.
- Leverage LlamaExtract to extract different sets of relevant attributes tailored to each specific contract category based on the classification.
- Store all structured information into a Neo4j knowledge graph, creating a rich, queryable representation that captures both content and intricate relationships within legal documents.
The code is available as a LlamaIndex cookbook.
Environment Setup
Before running this code, you need to set up API keys from LlamaCloud and OpenAI. For Neo4j, the simplest approach is to create a free Aura database instance.
OCR With LlamaParse
For this tutorial, we’ll analyze a sample commercial contract from the Contract Understanding Atticus Dataset (CUAD).
Now we’ll parse our contract document using LlamaParse to extract its text content:
# Initialize parser with specified mode
parser = LlamaParse(
api_key=llama_api_key,
parse_mode="parse_page_without_llm"
)
pdf_path = "CybergyHoldingsInc_Affliate Agreement.pdf"
results = await parser.aparse(pdf_path)The code creates a LlamaParse instance and processes our sample contract PDF.
Document Classification
Before we extract relevant information from our contract, we need to determine what type of contract we’re dealing with. Different contract types have different clause structures and legal information, so we need the contract type to dynamically select the appropriate extraction schema.
openai_client = AsyncOpenAI(api_key=openai_api_key)
classification_prompt = """You are a legal document classification assistant.
Your task is to identify the most likely contract type based on the content of the first 10 pages of a contract.
Instructions:
Read the contract excerpt below.
Review the list of possible contract types.
Choose the single most appropriate contract type from the list.
Justify your classification briefly, based only on the information in the excerpt.
Contract Excerpt:
{contract_text}
Possible Contract Types:
{contract_type_list}
Output Format:
<Reason>brief_justification</Reason>
<ContractType>chosen_type_from_list</ContractType>
"""
async def classify_contract(contract_text: str, contract_types: list[str]) -> dict:
prompt = classification_prompt.format(
contract_text=file_content,
contract_type_list=contract_types
)
history = [{"role": "user", "content": prompt}]
response = await openai_client.responses.create(
input=history,
model="gpt-4o-mini",
store=False,
)
return extract_reason_and_contract_type(response.output[0].content[0].text)This code sets up an OpenAI client and creates a classification system with two parts: a prompt template that instructs the LLM how to classify contracts and a function that handles the actual classification process.
Now we execute the classification process with our parsed contract data:
contract_types = ["Affiliate_Agreements", "Co_Branding", "Development"]
# Take only the first 10 pages for contract classification as input
file_content = " ".join([el.text for el in results.pages[:10]])
classification = await classify_contract(file_content, contract_types)Extraction With LlamaExtract
LlamaExtract is a cloud service that transforms unstructured documents into structured data using AI-powered schema-based extraction.
Define the Schema
Here we define two Pydantic models: Location captures structured address information with optional fields for country, state, and address; and Party represents contract parties with a required name and optional location details. The field descriptions help guide the extraction process by telling the LLM exactly what information to look for in each field.
class Location(BaseModel):
"""Location information with structured address components."""
country: Optional[str] = Field(None, description="Country")
state: Optional[str] = Field(None, description="State or province")
address: Optional[str] = Field(None, description="Street address or city")
class Party(BaseModel):
"""Party information with name and location."""
name: str = Field(description="Party name")
location: Optional[Location] = Field(None, description="Party location details")Remember, we have multiple contract types, so we need to define specific extraction schemas for each type and create a mapping system to dynamically select the appropriate schema based on our classification result.
class BaseContract(BaseModel):
"""Base contract class with common fields."""
parties: Optional[List[Party]] = Field(None, description="All contracting parties")
agreement_date: Optional[str] = Field(None, description="Contract signing date. Use YYYY-MM-DD")
effective_date: Optional[str] = Field(None, description="When contract becomes effective. Use YYYY-MM-DD")
expiration_date: Optional[str] = Field(None, description="Contract expiration date. Use YYYY-MM-DD")
governing_law: Optional[str] = Field(None, description="Governing jurisdiction")
termination_for_convenience: Optional[bool] = Field(None, description="Can terminate without cause")
anti_assignment: Optional[bool] = Field(None, description="Restricts assignment to third parties")
cap_on_liability: Optional[str] = Field(None, description="Liability limit amount")
class AffiliateAgreement(BaseContract):
"""Affiliate Agreement extraction."""
exclusivity: Optional[str] = Field(None, description="Exclusive territory or market rights")
non_compete: Optional[str] = Field(None, description="Non-compete restrictions")
revenue_profit_sharing: Optional[str] = Field(None, description="Commission or revenue split")
minimum_commitment: Optional[str] = Field(None, description="Minimum sales targets")
class CoBrandingAgreement(BaseContract):
"""Co-Branding Agreement extraction."""
exclusivity: Optional[str] = Field(None, description="Exclusive co-branding rights")
ip_ownership_assignment: Optional[str] = Field(None, description="IP ownership allocation")
license_grant: Optional[str] = Field(None, description="Brand/trademark licenses")
revenue_profit_sharing: Optional[str] = Field(None, description="Revenue sharing terms")
mapping = {
"Affiliate_Agreements": AffiliateAgreement,
"Co_Branding": CoBrandingAgreement,
}This schema design includes both structured extraction fields like party names, dates, and boolean flags, as well as more summarization-like fields for complex clauses such as exclusivity terms, revenue-sharing arrangements, and IP ownership details.
Now we can use our defined schema with our parsed contract text to extract the structured information. LlamaExtract will analyze the entire document content and pull out the specific fields we’ve defined.
extractor = LlamaExtract(api_key=llama_api_key)
agent = extractor.create_agent(
name=f"extraction_workflow_import_{uuid.uuid4()}",
data_schema=mapping[classification['contract_type']],
config=ExtractConfig(
extraction_mode=ExtractMode.BALANCED,
),
)
result = await agent.aextract(
files=SourceText(
text_content=" ".join([el.text for el in results.pages]),
filename=pdf_path
),
)Neo4j Knowledge Graph
The final step is to take our extracted structured information and build a knowledge graph that represents the relationships between contract entities. We need to define a graph model that specifies how our contract data should be organized as nodes and relationships in Neo4j.
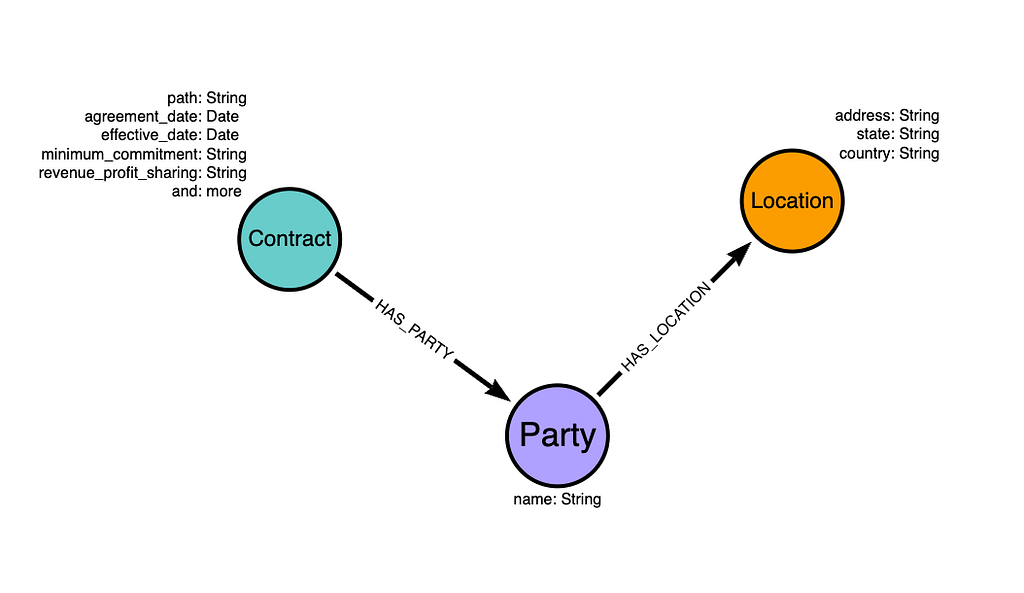
Our graph model consists of three main node types:
- Contract nodes store the core agreement information, including dates, terms, and legal clauses.
- Party nodes represent the contracting entities with their names.
- Location nodes capture geographic information with address components.
Now we’ll import our extracted contract data into Neo4j according to our defined graph model:
import_query = """WITH $contract AS contract
MERGE (c:Contract {path: $path})
SET c += apoc.map.clean(contract, ["parties", "agreement_date", "effective_date", "expiration_date"], [])
// Cast to date
SET c.agreement_date = date(contract.agreement_date),
c.effective_date = date(contract.effective_date),
c.expiration_date = date(contract.expiration_date)
// Create parties with their locations
WITH c, contract
UNWIND coalesce(contract.parties, []) AS party
MERGE (p:Party {name: party.name})
MERGE (c)-[:HAS_PARTY]->(p)
// Create location nodes and link to parties
WITH p, party
WHERE party.location IS NOT NULL
MERGE (p)-[:HAS_LOCATION]->(l:Location)
SET l += party.location
"""
response = await neo4j_driver.execute_query(import_query, contract=result.data, path=pdf_path)
response.summary.countersAfter importing the data, your Neo4j graph should look like the following image:

Bringing It All Together in a Workflow
Finally, we can combine all of this logic into one executable agentic workflow. Let’s make it so that the workflow can run by accepting a single PDF, adding new entries to our Neo4j graph each time.

You’ll find all the code to create this workflow in the corresponding notebook. We’ve kept it there to avoid cluttering this post with lengthy code blocks.
The workflow is designed for simplicity to allow you to process any document with a single command.
knowledge_graph_builder = KnowledgeGraphBuilder(
parser=parser,
affiliate_extract_agent=affiliage_extraction_agent,
branding_extract_agent=cobranding_extraction_agent,
classification_prompt=classification_prompt,
timeout=None,
verbose=True,
)
response = await knowledge_graph_builder.run(
pdf_path="CybergyHoldingsInc_Affliate Agreement.pdf"
)Summary
Traditional RAG systems rely on semantic similarity search through document chunks, which often loses critical context and relationships between entities. By structuring our contract data as a knowledge graph, we create a more intelligent retrieval system that understands how contracts, parties, and locations interconnect. Instead of searching through unstructured text fragments, your LLM can now leverage precise entity relationships to answer complex queries like, “What are the locations of all parties in contracts with Cybergy Holdings?” Or “Show me all affiliate agreements involving companies in New York.”
The code is available as a LlamaIndex cookbook.
Resources
- The Developer’s Guide: How to Build a Knowledge Graph
- What Is Retrieval-Augmented Generation (RAG)?
- What Is a Knowledge Graph?
- Building Knowledge Graph Agents With LlamaIndex Workflows
From Legal Documents to Knowledge Graphs was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

Share Article



Explore
Related Articles

From Data to Intelligence: Why Every Enterprise Needs an AI Knowledge Layer


Why Healthcare CIOs Can’t Afford to Scale AI Without a Knowledge Graph Foundation

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

