








Explore Iterative Refinement for Text2Cypher

Machine Learning Engineer, Neo4j
5 min read
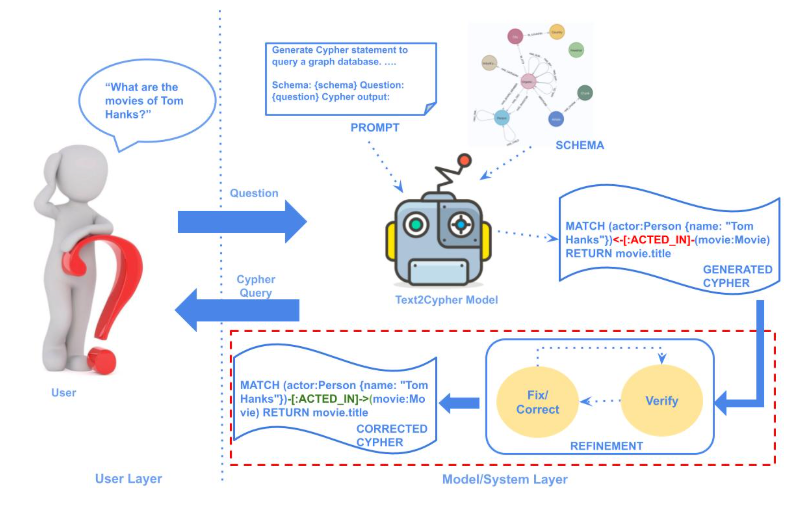
The Text2Cypher task focuses on converting natural language questions into Cypher queries, which are used to interact with Neo4j graph databases. For example, the question “What are the movies of Tom Hanks?” should be translated into the Cypher query MATCH (actor:Person {name: “Tom Hanks”})-[:ACTED_IN]->(movie:Movie) RETURN movie.title.
While LLMs often generate the correct Cypher query, they can also produce invalid outputs. To address this, we explore an iterative refinement process aimed at improving Text2Cypher performance. The initial version of this process consists of two steps executed after the first generation:
- Verification: Check whether the generated Cypher is valid.
- Correction: If it’s invalid, refine the Cypher accordingly.
These steps can be executed in an iterative loop until a stop criteria is met.
In this blog post, we describe our implementation of this verification and correction process and share initial empirical observations.
Iterative Refinement Loop
After generating the Cypher query based on the user question, we can further refine it using an iterative approach.

In general:
Given generated Cypher query (together with input question, schema, other metadata)
Iterate until stop critera:
Verify the Cypher query
If it is valid: Accept/Return to the user
Otherwise: Correct itAs highlighted in the pseudo-code, there are three configurations to set up:
- Stop criteria
- Verification techniques
- Correction techniques
Stop Criteria
Even though stop criteria could be set to any value depending on the task and the developer’s decision, in the experiments, we used:
- Max three iterations
- Early stop if there aren’t any remaining invalid queries
Verification Techniques
We implemented four verification approaches:
- Rule-Based Relation Direction Verification
- CyVer-Based Verification
- Execution-Based Verification
- LLM-Based Verification

Correction Techniques
We implemented two correction approaches:
- Rule-Based Relation Direction Correction
- LLM-Based Correction

Experimental Setup
For the experiments, I used the test split of text2cypher25 dataset. For all analyses, previously generated outputs were used, such that prediction results served as input and only the iterative refinement loop was explored.
During the experiments, we can use one or more techniques together. For example:
TARGET_VERIFIER_TYPES = [
VerifierType.LANGCHAIN, VerifierType.CYVER, VerifierType.LLM_BASED]
TARGET_CORRECTION_TYPES = [
CorrectionType.RULE_BASED, CorrectionType.LLM_BASED]When multiple techniques are used, the following execution orders are used:
Execution order of verifiers: [
VerifierType.LANGCHAIN, VerifierType.CYVER,
VerifierType.EXECUTION_BASED, VerifierType.LLM_BASED]
Execution order of correctors: [
CorrectionType.RULE_BASED, CorrectionType.LLM_BASED]Verifiers return additional metadata (e.g., error messages) together with Boolean valid/invalid indicators. The usage of metadata in the correction stage is also provided as a configuration parameter.
Output Analysis — Empirical Results
In this blog post, we present some sample configurations and sampled outputs from iterations. In the future, statistical experiments will be conducted and shared.
Sample Execution Statistics
As highlighted in the verifiers section, accessing databases or calling LLMs for verification (and correction) is a slow process. However, they’re able to identify more questions as invalid.

Empirical Observations
🟢 Example — Refinement loops fixes the invalid Cypher:
- Instance ID:
instance_id_41936 - Question: List the top three users who have rated at least one movie in each genre available
Db-Reference:neo4jlabs_demo_db_recommendations- Verifiers:
[LC, CYVER], Correctors:[RB, LLM], Metadata:Yes - At the end of the second iteration, the problems in the Cypher query are fixed, and an execution output is obtained.

🔴Example — Refinement loops couldn’t fix the invalid Cypher:
- Instance ID:
instance_id_30297 - Question: List the questions asked by users with a reputation less than the average reputation of all users
Db-Reference:neo4jlabs_demo_db_buzzoverflow- Verifiers:
[LLM], Correctors:[RB, LLM], Metadata:Yes - No change observed

Observations
Verifiers:
- Performance: Rule-based verifiers are the fastest (~1.5 ms, ~600x faster than others).
- Verifier behavior: LLM-based flags 15–20x more invalids (could be many false positives); rule-based depends on regex/string quality.
Correctors:
- Performance: Most correction is already done after the first iteration. However, as exemplified in empirical outputs, multiple iterations can help to fix more issues.
- Corrector behavior: The LLM-based approach is slow and costs more, but the rule-based approach has low capacity (i.e., only fixing relation direction).
Summary and Future Work
We explored an iterative refinement process aimed at improving Text2Cypher performance. The initial version of this process consists of two steps executed after the first generation: verification and correction. These steps can be executed in an iterative loop until a stop criteria is met.
Our initial analysis revealed that the iterative refinement is a promising direction but requires further exploration. To reduce reliance on costly external calls (to either the database or an LLM), alternative strategies should be considered. Inspired by some recent academic publications (Make Every Penny Count: Difficulty-Adaptive Self-Consistency for Cost-Efficient Reasoning and Learning How Hard to Think: Input-Adaptive Allocation of LM Computation), one potential improvement lies in the first iteration’s validation step, which currently checks all inputs. By incorporating a complexity analysis beforehand, we could skip verification for simpler Cypher queries and thereby reduce the time spent in the initial validation stage.
Resources
- Verify Neo4j Cypher Queries With CyVer
- Neo4j Cypher Query Language
- Effortless RAG With Text2CypherRetriever
- Neo4j Text2Cypher: Analyzing Model Struggles and Dataset Improvements
Exploring Iterative Refinement for Text2Cypher was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.



