


Integrating Neo4j With LangChain4j for GraphRAG Vector Stores and Retrievers

Software Developer, LARUS Business Automation
15 min read
A brief overview about the integration of Neo4j in LangChain4j
A Quick Overview
LangChain4j is a Java library — similar to LangChain for Python and JavaScript — that simplifies the integration of AI/LLM capabilities into Java applications. It provides a clean API for working with a variety of LLM providers and embedding stores.
In addition, LangChain4j includes tools for AI tasks such as sentiment analysis and information extraction. Although the library is still in active development, its core functionalities are stable and available.
This article demonstrates how to set up and use the LangChain4j framework with Neo4j — a high-performance, open-source graph database designed for managing connected data — to perform graph-based question answering. By integrating LangChain4j with Neo4j, you can leverage advanced language models and graph data to answer complex queries based on the relationships and properties stored within the database.
This guide is based on version 1.0.0-beta4, and it’s important to note that future releases may introduce changes or additional features that could alter some of the behaviors or interfaces described here.
Neo4j Classes
LangChain4j provides the following classes for Neo4j integration:
- Neo4jEmbeddingStore — Implements the EmbeddingStore interface, enabling storing and querying vector embeddings in a Neo4j database
- Neo4jText2CypherRetriever — Implements the ContentRetriever interface for generating and executing Cypher queries from user questions, improving content retrieval from Neo4j databases
The EmbeddingStore interface defines a standard way to store and search embeddings (vector representations of data). It has three main sets of methods:
- add/addAll— Adds one or multiple embeddings.
- search(EmbeddingSearchRequest request) — Searches for similar embeddings based on a query embedding and search parameters. The EmbeddingSearchRequest is a builder that contains the query embedding (what you’re searching with), and optionally maxResults (how many matches you want) and minScore (optional minimum similarity threshold).
- remove/removeAll — Removes embeddings by their IDs.
The ContentRetriever interface defines a simple contract for retrieving relevant content based on a query. It has one main method: retrieve(String query), which takes a Query (which can contain text, filters, etc.) and returns a list of relevant Content items.
ContentRetriever is a high-level abstraction. It can be backed by different systems like databases, vector stores, search engines, or even custom logic.
Neo4j Embedding Store
We have to add the following dependencies:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-neo4j</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId>
<version>${langchain.version}</version>
</dependency>In the following examples, we use langchain4j-embeddings-all-minilm-l6-v2 to create an AllMiniLmL6V2EmbeddingModel, which implements the EmbeddingModel interface. Alternatively, we can use one of the numerous models provided by LangChain4j, like the OpenAiEmbeddingModel in the langchain4j-open-ai module.
Connect to the Neo4j Database and Create the Embedding Store Instance
We can create it in this way:
Driver graphDatabaseDriver = /* org.neo4j.driver.Driver instance */
Neo4jEmbeddingStore.builder()
.withBasicAuth("bolt://<neo4jBoltUrlHost>:<port>", "<user>", "<password>")
.dimension(384)
.build();or equivalently:
Driver graphDatabaseDriver = /* org.neo4j.driver.Driver instance */
Neo4jEmbeddingStore.builder()
.driver(graphDatabaseDriver)
.dimension(384)
.build();As we can see, the required configurations are the Neo4j index dimension parameter and the Neo4j Java Driver connection instance. As an alternative to the Neo4j Java driver, we can create a Neo4jEmbeddingStore.builder().withBasicAuth(<url>, <username>, <password>), which will create a Driver connection instance under the hood.
It’s possible to add other optional configurations via the builder, as we’ll see later.
Store Embeddings
EmbeddingStore<TextSegment> minimalEmbedding = Neo4jEmbeddingStore.builder()
.withBasicAuth(neo4j.getBoltUrl(), "neo4j", neo4j.getAdminPassword())
.dimension(embeddingModel.dimension())
.build();
// or use OpenAIEmbeddingModel or other EmbeddingModel implementations
EmbeddingModel embeddingModel = new AllMiniLmL6V2QuantizedEmbeddingModel();
// add a single embedding
TextSegment segment = TextSegment.from("I like football.");
Embedding embedding = embeddingModel.embed(segment).content();
minimalEmbedding.add(embedding, segment);The above code will create a node with Label Document and the following properties:
- Embedding with the embedded text
- Text with the original text
- ID with a UUID
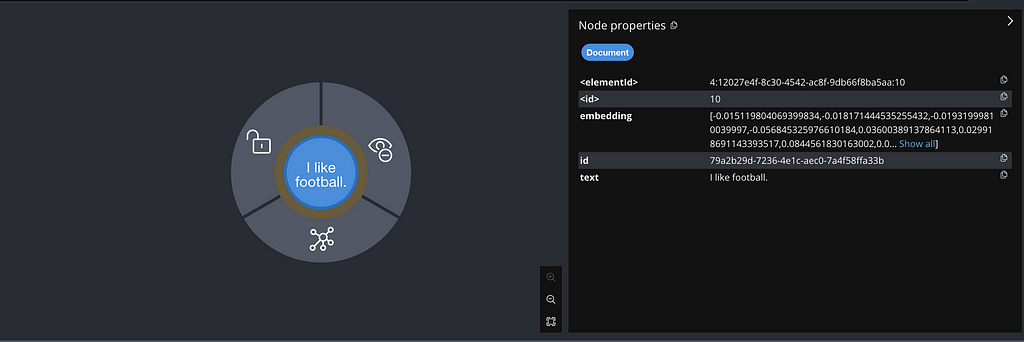
Based on the above example, we can execute the following code to get the embeddings from Neo4j:
Embedding queryEmbedding = embeddingModel.embed("What is your favourite sport?").content();
final EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
List<EmbeddingMatch<TextSegment>> relevant = minimalEmbedding.search(request).matches();
EmbeddingMatch<TextSegment> embeddingMatch = relevant.get(0);
System.out.println(embeddingMatch.score());
// result like this: 0.8144289255142212
System.out.println(embeddingMatch.embedded().text());
// I like football.Under the hood, it will execute:
CALL db.index.vector.queryNodes(<indexName>, <maxResults>, <embeddingValue>)
YIELD node, score
WHERE score >= <minScore>
// <retrievalQuery>maxResult and minScore are based on the EmbeddingSearchRequest, and <indexName> and <retrievalQuery> are customizables. The first has a default value ‘vector’ and the second has the following default:
RETURN properties(node) AS metadata,
node.<idProperty> AS <idProperty>,
node.<textProperty> AS <textProperty>,
node.<embeddingProperty> AS <embeddingProperty>,
score<idProperty>, <textProperty>, and <embeddingProperty> values are customizable as well, as we can see later.
In the above case (the default one), the complete query is:
CALL db.index.vector.queryNodes('vector', 1, 'What is your favourite sport?')
YIELD node, score
WHERE score >= 0.0
RETURN properties(node) AS metadata,
node.id AS id,
node.text AS text,
node.embedding AS embedding,
scoreOptional Configurations
As partially mentioned above, there are optional configurations. As of this writing, the following are present:
- Index name (with default vector)
- Neo4j node label (with default Document)
- Neo4j property key, which saves the embeddings (with default embeddingProp)
- Neo4j index distanceType parameter
- Metadata prefix (with default metadata)
- Text property key (with default text), which stores the text field
- Retrieval query
Neo4jEmbeddingStore customEmbeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth("bolt URI", "neo4j", neo4j.getAdminPassword())
.dimension(embeddingModel.dimension())
.indexName("customIdx")
.label("MyCustomLabel")
.embeddingProperty("customProp")
.idProperty("customId")
.textProperty("customText")
.build();
TextSegment segment = TextSegment.from("I like tennis");
Embedding embedding = embeddingModel.embed(segment).content();
customEmbeddingStore.add(embedding, segment);
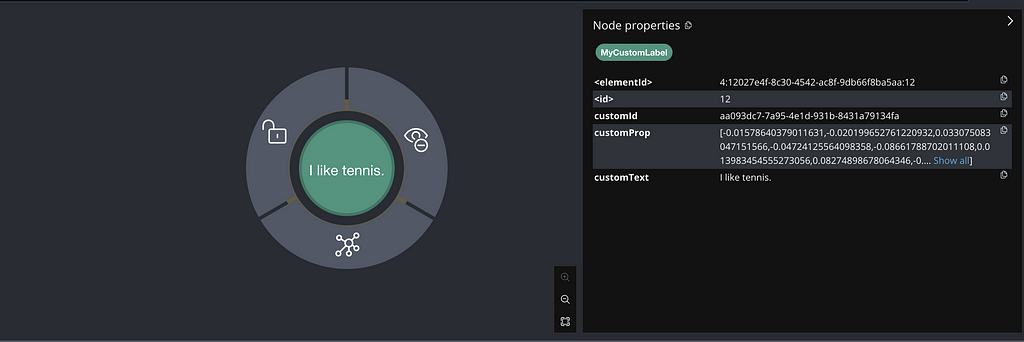
// customEmbeddingStore.search(..).matches();The above example executes a CREATE VECTOR INDEX customIdx IF NOT EXISTS FOR (m:MyCustomLabel) ON m.customId and creates a node with label MyCustomLabel and the following properties:
- customId with a UUID
- customProp with the embedded text
- customText with the original text
We can insert metadata with a custom prefix (or they will have a default value metadata) in this way:
Neo4jEmbeddingStore customEmbeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth("bolt://localhost:7687", "neo4j", "pass1234")
.dimension(embeddingModel.dimension())
.indexName("customIdxName")
.label("MyCustomLabel")
.embeddingProperty("customProp")
.idProperty("customId")
.textProperty("customText")
.metadataPrefix("metaCustom")
.build();
TextSegment segment = TextSegment.from("I like volleyball.", Metadata.from(Map.of("foo", "bar", "baz", 1)));
Embedding embedding = embeddingModel.embed(segment).content();
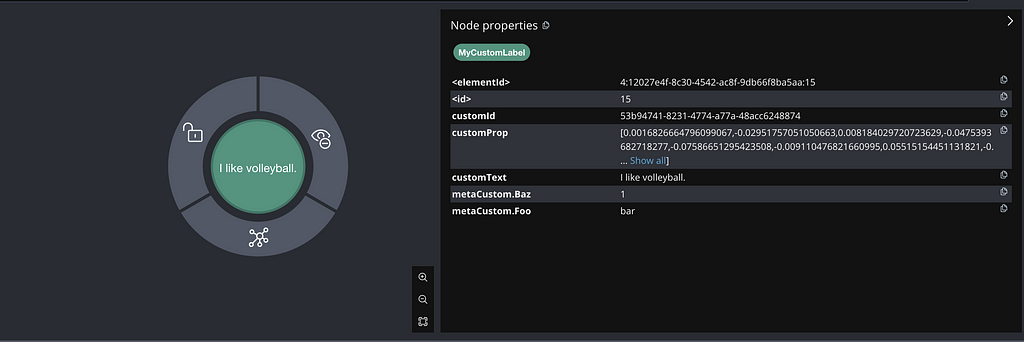
customEmbeddingStore.add(embedding, segment);With the following result, we can see metaCustom.Foo and metaCustom.Baz properties, defined in the TextSegment’s Metadata.from() method:
Metadata Filter
The metadata filter is based on the Filter LangChain4j class and represents a condition used to filter search results during an embedding search.
Note that by specifying the Filter builder parameter, the query is different since the db.index.vector.queryNodes doesn’t currently provide the ability to perform WHERE clauses.
The query:
CYPHER runtime = parallel parallelRuntimeSupport=all
MATCH (n:<label>)
WHERE n.<embeddingProperty> IS NOT NULL
AND size(n.<embeddingValue>) = toInteger(<dimension>)
AND <metadataFilter>
WITH n,
vector.similarity.cosine(n.<embeddingProperty>, <embeddingValue>) AS score
WHERE score >= <minScore>
WITH n AS node, score
ORDER BY score DESC
LIMIT <maxResults>When you perform a search with EmbeddingSearchRequest, you can attach a Filter to restrict results — for example, only returning embeddings that match certain metadata (like a document type, user ID, etc.). It’s typically used to build expressions like value1 = value2 , value1 > value2 , value1 <= value2, and complex logical combinations with AND, OR, and NOT.
For instance, we can build an equal Filter:
IsEqualTo filter = new IsEqualTo("key", value);
final EmbeddingSearchRequest requestWithFilter = EmbeddingSearchRequest.builder()
.filter(filter)
.queryEmbedding(/*embeddingToSearch*/)
.build();
final EmbeddingSearchResult<TextSegment> searchWithFilter = embeddingStore.search(requestWithFilter);
This creates a <metadataFilter> to be executed with the query above:
WHERE n['key'] = 'value'The possible filters to use are:
- IsEqualTo(key, value)
- IsNotEqualTo(key, value)
- IsGreaterThan(key, value)
- IsGreaterThanOrEqualTo(key, value)
- IsLessThan(key, value)
- IsLessThanOrEqualTo(key, value)
- IsIn(key, setOfValues)
- IsNotIn(key, setOfValues)
- And(subFilter, subFilter)
- Not(subFilter)
- Or(subFilter, subFilter)
For instance, we can create a more complex filter:
Or filter = new Or(
new And(new IsEqualTo("key1", "value1"), new IsGreaterThan("key2", "value2")),
new Not(new And(new IsIn("key3", valueKey3), new IsLessThan("key4", "value4"))));
// requestWithFilter and search ...This creates a <metadataFilter>:
WHERE (
(n['key1'] = 'value1' AND n['key2'] > 'value2')
OR NOT ( (any(x IN ['1', '2'] WHERE x IN n['key3']) AND n['key4'] < 'value4') )
)Hybrid Search
We can improve the results by implementing a hybrid search, which combines vector similarity search with a full-text search.
The hybrid approach ensures comprehensive query responses, leveraging the strengths of both data types (vectors and text).
Under the hood, if the autoCreateFullText builder parameter (default: false) is set to true, it will create:
CREATE FULLTEXT INDEX <fullTextIndexName> IF NOT EXISTS FOR (n:<label>) ON EACH [n.<idProperty>]Executing thesearch(EmbeddingSearchRequest request) method, the following query will be executed:
CALL db.index.vector.queryNodes($indexName, $maxResults, $embeddingValue)
YIELD node, score
WHERE score >= $minScore
// <retrievalQuery>
UNION
CALL db.index.fulltext.queryNodes($fullTextIndexName, $fullTextQuery, {limit: $maxResults})
YIELD node, score
WHERE score >= $minScore
// fullTextRetrievalQueryThe fullTextQuery builder method is required to append the “UNION <fullTextSearch>” part.
The minimum settings:
Neo4jEmbeddingStore embeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth(...)
.dimension(384)
.fullTextIndexName("movie_text")
.fullTextQuery("Matrix")
.build()
// ... add embeddings, e.g. with embeddingStore.addAll(embeddings);
final EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.minScore(0.5)
.maxResults(1)
.build();
// get embeddings
List<EmbeddingMatch<TextSegment>> results =
embeddingStore.search(embeddingSearchRequest).matches();The executed Neo4j query:
// CALL db.index.fulltext.queryNodes part
UNION
CALL db.index.fulltext.queryNodes('movie_text', 'Matrix', {limit: 1})
YIELD node, score
WHERE score >= 0.5
RETURN properties(node) AS metadata, node.id AS id, node.text AS text, node.embedding AS embedding, scoreIf needed, we can also customize the fullTextRetrieval query and the fullTextIndexName:
Neo4jEmbeddingStore embeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth(...)
.dimension(...)
.fullTextIndexName("elizabeth_text")
.fullTextQuery("elizabeth*")
.fullTextRetrievalQuery("RETURN node.test AS metadata, score, datetime() as datetime")This will create a Neo4j query:
// CALL db.index.vector.queryNodes part
UNION
CALL db.index.fulltext.queryNodes('elizabeth_text', 'elizabeth*', {limit: $maxResults})
YIELD node, score
WHERE score >= $minScore
RETURN node.test AS metadata, score, datetime() as datetimeSpring Boot Example
To create a Spring Boot starter example, we can add dependencies:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-neo4j-spring-boot-starter</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain.version}</version>
</dependency>
<!-- or other embedding models, like langchain4j-open-ai -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId>
<version>${langchain.version}</version>
</dependency>The Neo4j starter currently provides the following application.properties:
# the builder.dimension(dimension) method
langchain4j.community.neo4j.dimension=<dimension>
# the builder.withBasicAuth(uri, username, password) method
langchain4j.community.neo4j.auth.uri=<boltURI>
langchain4j.community.neo4j.auth.user=<username>
langchain4j.community.neo4j.auth.password=<password>
# the builder.label(label) method
langchain4j.community.neo4j.label=<label>
# the builder.indexName(indexName) method
langchain4j.community.neo4j.indexName=<indexName>
# the builder.metadataPrefix(metadataPrefix) method
langchain4j.community.neo4j.metadataPrefix=<metadataPrefix>
# the builder.embeddingProperty(embeddingProperty) method
langchain4j.community.neo4j.embeddingProperty=<embeddingProperty>
# the builder.idProperty(idProperty) method
langchain4j.community.neo4j.idProperty=<idProperty>
# the builder.textProperty(textProperty) method
langchain4j.community.neo4j.textProperty=<textProperty>
# the builder.databaseName(databaseName) method
langchain4j.community.neo4j.databaseName=<databaseName>
# the builder.retrievalQuery(retrievalQuery) method
langchain4j.community.neo4j.retrievalQuery=<retrievalQuery>
# the builder.awaitIndexTimeout(awaitIndexTimeout) method
langchain4j.community.neo4j.awaitIndexTimeout=<awaitIndexTimeout>Therefore, assuming we have a Neo4j instance with Bolt URI bolt://localhost:7687, username ‘neo4j’ and password ‘pass1234’, we can set the following properties:
server.port=8083
langchain4j.community.neo4j.dimension=384
langchain4j.community.neo4j.auth.uri=bolt://localhost:7687
langchain4j.community.neo4j.auth.user=neo4j
langchain4j.community.neo4j.auth.password=pass1234
langchain4j.community.neo4j.label=CustomLabelWe create a Spring Boot project like below, where we have a main class with the SpringBootApplication annotation and an API REST controller with two endpoints: /add to store the embeddings and /search to get the five most similar.
@SpringBootApplication
public class SpringBootExample {
public static void main(String[] args) {
SpringApplication.run(SpringBootExample.class, args);
}
@Bean
public AllMiniLmL6V2EmbeddingModel embeddingModel() {
return new AllMiniLmL6V2EmbeddingModel();
}
}
@RestController
@RequestMapping("/api/embeddings")
public class EmbeddingController {
private final EmbeddingStore<TextSegment> store;
private final EmbeddingModel model;
public EmbeddingController(EmbeddingStore<TextSegment> store, EmbeddingModel model) {
this.store = store;
this.model = model;
}
// add embeddings
@PostMapping("/add")
public String add(@RequestBody String text) {
TextSegment segment = TextSegment.from(text);
Embedding embedding = model.embed(text).content();
return store.add(embedding, segment);
}
// search embeddings
@PostMapping("/search")
public List<String> search(@RequestBody String query) {
Embedding queryEmbedding = model.embed(query).content();
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(5)
.build();
return store.search(request).matches()
.stream()
.map(i -> i.embedded().text()).toList();
}
}With the above code, we can integrate the REST APIs like this:
# to create a new embedding
# and store it with a label "SpringBoot"
curl -X POST localhost:8083/api/embeddings/add -H "Content-Type: text/plain" -d "embeddingTest"
# to search the first 5 embeddings
curl -X POST localhost:8083/api/embeddings/search -H "Content-Type: text/plain" -d "querySearchTest"Neo4j Text2Cypher Retriever
We add the following dependencies:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-neo4j-retriever</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain.version}</version>
</dependency>This component dynamically translates natural language questions into Cypher queries, unlocking powerful, context-aware access to data stored in Neo4j. By bridging user intent with graph-based search, it significantly boosts the accuracy and relevance of retrieved content, making Neo4j not just a database but an intelligent knowledge engine.
Neo4jGraph Class
This leverages Neo4jGraph, a class designed for enhanced interaction with Neo4j databases, including read/write operations and schema management. We can use it to create read/write operations:
Neo4jGraph neo4jGraph = Neo4jGraph.builder()
.driver(driver)
.build();
neo4jGraph.executeRead("<Neo4j read query>");
neo4jGraph.executeWrite("<Neo4j write query>");It can also be used to get a Neo4j entity overview, which we’ll see in detail below:
Neo4jGraph neo4jGraph = /* Neo4jGraph instance */;
String schema = neo4jGraph.getSchema();Content Retriever Examples
A basic example:
Driver driver = /* org.neo4j.driver.Driver instance */
Neo4jGraph neo4jGraph = Neo4jGraph.builder()
.driver(driver)
.build();
// create simple dataset
driver.session()
.run("CREATE (book:Book {title: 'Dune'})<-[:WROTE {when: date('1999')}]-(author:Person {name: 'Frank Herbert'})")
Neo4jText2CypherRetriever retriever = Neo4jText2CypherRetriever.builder()
.graph(neo4jGraph)
.chatLanguageModel(chatLanguageModel)
.build();
// retrieve the result
Query query = new Query("Who is the author of the book 'Dune'?");
List<Content> contents = retriever.retrieve(query);
System.out.println(contents.get(0).textSegment().text());
// output: "Frank Herbert"It will execute a chat request with the following prompt string:
Task:Generate Cypher statement to query a graph database.
Instructions
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{{schema}}
{{examples}}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
The question is: {{question}}where {{question}} is Who is the author of the book ‘Dune’? with the above code, {{example}} is empty (by default) and {{schema}} is handled by the Neo4j Graph, which uses the apoc.meta.data procedure to retrieve and stringify the current Neo4j schema.
By default, it samples 1,000 nodes for each label to calculate the pattern, but this behavior can be changed by doing the following:
// it samples 3000 nodes for each label
Neo4jGraph neo4jGraph = Neo4jGraph.builder()
.driver(driver)
.sample(3000L)
.build();With the dataset above, the schema string is:
Node properties are the following:
:Book {title: STRING}
:Person {name: STRING}
Relationship properties are the following:
:WROTE {when: DATE}
The relationships are the following:
(:Person)-[:WROTE]->(:Book)We can also change the default prompt if needed:
Neo4jText2CypherRetriever.builder()
.neo4jGraph(/* Neo4jGraph instance */)
.promptTemplate("<custom prompt>")
.build();Moreover, we can enrich and improve the result by just adding few-shot examples to prompt the <examples>section. For instance:
Neo4jGraph neo4jGraph = /* Neo4jGraph instance */
List<String> examples = List.of(
"""
# Which streamer has the most followers?
MATCH (s:Stream)
RETURN s.name AS streamer
ORDER BY s.followers DESC LIMIT 1
""",
"""
# How many streamers are from Norway?
MATCH (s:Stream)-[:HAS_LANGUAGE]->(:Language {{name: 'Norwegian'}})
RETURN count(s) AS streamers
""");
Neo4jText2CypherRetriever neo4jContentRetriever = Neo4jText2CypherRetriever.builder()
.graph(neo4jGraph)
.chatLanguageModel(openAiChatModel)
// add the above examples
.examples(examples)
.build();
// retrieve the optimized results
final String textQuery = "Which streamer from Italy has the most followers?";
Query query = new Query(textQuery);
List<Content> contents = neo4jContentRetriever.retrieve(query);
System.out.println(contents.get(0).textSegment().text());
// output: "The most followed italian streamer"More to Come
LangChain4j and its Neo4j core functionalities are relatively new tools for integrating AI/LLM capabilities into Java applications. While the library is still in active development, its core functionality is already available.
Neo4j integration as well is evolving, with many improvements and new features on the horizon. The integration is progressing rapidly. What’s available today is just the beginning. Some features that will be included soon:
- LLMGraphTransformer — A package to transform one or more documents in a graph. It’s database-agnostic; it transforms text into a set of Nodes and Edges that can also be used for other graph databases.
- Graph Converter — Uses LLMGraphTransformer to convert Node and Edge to Neo4j entities.
- GraphRAG concepts — A set of utilities that enable the implementation of Retrieval-Augmented Generation (RAG) using a knowledge graph. For instance, it will implement a parent-child retriever that splits documents into (bigger) chunks (parent chunks) and further splits these chunks into smaller chunks (child chunks), which will be embeddable and can be used via an ad-hoc retrieval query.
- Chat memory — A ChatMemory implementation will save conversations in a Neo4j database via Message and Session nodes, and LAST_MESSAGE and NEXT_MESSAGE relationships.
Future updates will not only align more closely with the broader LangChain ecosystem but will also introduce entirely new capabilities — think graph-aware transformers like LLMGraphTransformer, advanced GraphRAG patterns, and persistent chat memory designed for graph-structured data. As AI and knowledge graphs grow, the tools for smart retrieval and reasoning will improve, too.
Additionally, minor improvements and configurations of the existing components, such as enhanced retry handling for embeddings and retrievers, will also be included:
- retry handling — To retry execution in case the queries generated by the ChatModels are found to be invalid
- cypher-dsl — A Java Builder with the goal of having a type-safe way of creating Cypher queries targeted
Resources
- The implementations in the LangChain4j repo: Embedding Store, Content Retriever, Spring Boot Starter
- More examples in the langchain4j-examples repository
- LangChain4j documentation
- Neo4j Labs docs
Integrating Neo4j With LangChain4j for GraphRAG Vector Stores and Retrievers was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Why Healthcare CIOs Can’t Afford to Scale AI Without a Knowledge Graph Foundation

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.



