







Natural Language Analytics made simple and visual with Neo4j

Head of Product Innovation & Developer Strategy, Neo4j
9 min read
I was really impressed by this blog post on Summarizing Opinions with a Graph from Max and always waited for Part 2 to show up 🙂
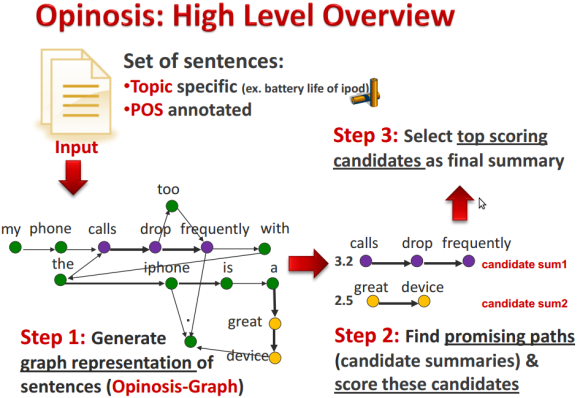
By just looking at the graph structure, it turns out that the most significant statements (positive or negative) are repeated across many reviews.
Differences in formulation or inserted fill words only affect the graph structure minimally but reinforce it for the parts where they overlap.
You can find all the details of the approach in this presentation or the accompanying research.
// "Great device but the calls drop too frequently"
WITH split("My phone calls drop frequently with the iPhone"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
CREATE (w1)-[:NEXT]->(w2);
WITH split("Great device but the calls drop too frequently"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2);

MATCH path = (w:Word {name:"calls"})-[:NEXT*..3]->()
RETURN [n in nodes(path) | n.name] as phrase
LIMIT 5;
| phrase |
| [calls, drop] |
| [calls, drop, frequently] |
| [calls, drop, frequently, with] |
| [calls, drop, too] |
| [calls, drop, too, frequently] |
The Cypher features used so far:
WITH to provide data to the next query statement
split() to split text along delimiters
size() for the size of collections and strings
range() to create a range of numbers
UNWIND to turn a collection into result rows
collection index access to get the individual words
MERGE to “find-or-create” data in the graph, with a label :Word for each of the nodes and a property name
CREATE to create the relationship between two nodes (You would want to use MERGE on the relationship in this concrete case)
But I wanted moar features!
So I added one after the other in quick succession, becoming happier as I went along as I didn’t hit any real stumbling blocks.
I want to record followship frequency
WITH split("My phone calls drop frequently with the iPhone"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[r:NEXT]->(w2)
ON CREATE SET r.count = 1 ON MATCH SET r.count = r.count +1;
I want to record the word frequencies too
WITH split("My phone calls drop frequently with the iPhone"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
ON CREATE SET w1.count = 1 ON MATCH SET w1.count = w1.count + 1
MERGE (w2:Word {name:words[idx+1]})
ON CREATE SET w2.count = 1
ON MATCH SET w2.count = w2.count + (case when idx = size(words)-2 then 1 else 0 end)
MERGE (w1)-[r:NEXT]->(w2)
ON CREATE SET r.count = 1
ON MATCH SET r.count = r.count +1;
I also want to sentence number and word position
I pass the sentence number from the the outside as sid, the position is `idx`
WITH 1 as sid, split("My phone calls drop frequently with the iPhone"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
ON CREATE SET w1.count = 1 ON MATCH SET w1.count = w1.count + 1
MERGE (w2:Word {name:words[idx+1]})
ON CREATE SET w2.count = 1
ON MATCH SET w2.count = w2.count + (case when idx = size(words)-2 then 1 else 0 end)
MERGE (w1)-[r:NEXT]->(w2)
ON CREATE SET r.count = 1, r.pos = [sid,idx]
ON MATCH SET r.count = r.count +1, r.pos = r.pos + [sid,idx];
I want all words to be lower-case
WITH "My phone calls drop frequently with the iPhone" as text
WITH split(tolower(text)," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)
I want to clean up punctuation
Just use replace() repeatedly with the text
with "Great device, but the calls drop too frequently." as text
with replace(replace(tolower(text),".",""),",","") as normalized
with split(normalized," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)
I want to remove many punctuation symbols
with "Great device, but the calls drop too frequently." as text
with reduce(t=tolower(text), delim in [",",".","!","?",'"',":",";","'","-"] | replace(t,delim,"")) as normalized
with split(normalized," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)
I want to trim whitespace
Use trim() with each word of the collection
with "Great device, but the calls drop too frequently." as text
with replace(replace(tolower(text),".",""),",","") as normalized
with [w in split(normalized," ") | trim(w)] as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)
I want to filter out stop words
Filter the words after splitting and trimming by checking against a collection with `IN`
with "Great device, but the calls drop too frequently." as text
with replace(replace(tolower(text),".",""),",","") as normalized
with [w in split(normalized," ") | trim(w)] as words
with [w in words WHERE NOT w IN ["the","an","on"]] as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)
match (n) optional match (n)-[r]-() delete n,r
I want to load the text from a file
We use the Lord of the Rings poem of the One Ring as input, located in a dropbox text file.
If we choose a full stop as a field terminator, it actually splits on sentence ends (mostly).
So we can just unwind each row into it’s cells (text fragments) and then treat each of those as we did a piece of text before.
Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Nine for Mortal Men doomed to die, One for the Dark Lord on his dark throne In the Land of Mordor where the Shadows lie. One Ring to rule them all, One Ring to find them, One Ring to bring them all and in the darkness bind them In the Land of Mordor where the Shadows lie.
load csv from "https://dl.dropboxusercontent.com/u/14493611/one-ring.txt" as row fieldterminator "."
with row
unwind row as text
with reduce(t=tolower(text), delim in [",",".","!","?",'"',":",";","'","-"] | replace(t,delim,"")) as normalized
with [w in split(normalized," ") | trim(w)] as words
unwind range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[r:NEXT]->(w2)
ON CREATE SET r.count = 1 ON MATCH SET r.count = r.count +1
I want to ingest really large files
Prefix your LOAD CSV with USING PERIODIC COMMIT X for committing after X rows
using periodic commit 1000
load csv from "https://dl.dropboxusercontent.com/u/14493611/one-ring.txt" as row fieldterminator "."
with row
unwind row as text
with reduce(t=tolower(text), delim in [",",".","!","?",'"',":",";","'","-"] | replace(t,delim,"")) as normalized
with [w in split(normalized," ") | trim(w)] as words
unwind range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[r:NEXT]->(w2)

Look for paths with high reference counts and compute a score of total reference counts of the paths and order by it.
MATCH path = (w:Word)-[:NEXT*..5]->() WHERE ALL (r IN rels(path) WHERE r.count > 1) RETURN [w IN nodes(path)| w.name] AS phrase, reduce(sum=0,r IN rels(path)| sum + r.count) as score ORDER BY score DESC LIMIT 1
| phrase | score |
| [one, ring, to] |
6 |
Want to learn more about graph databases? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technologies for your application today.
Share Article



Explore
Related Articles
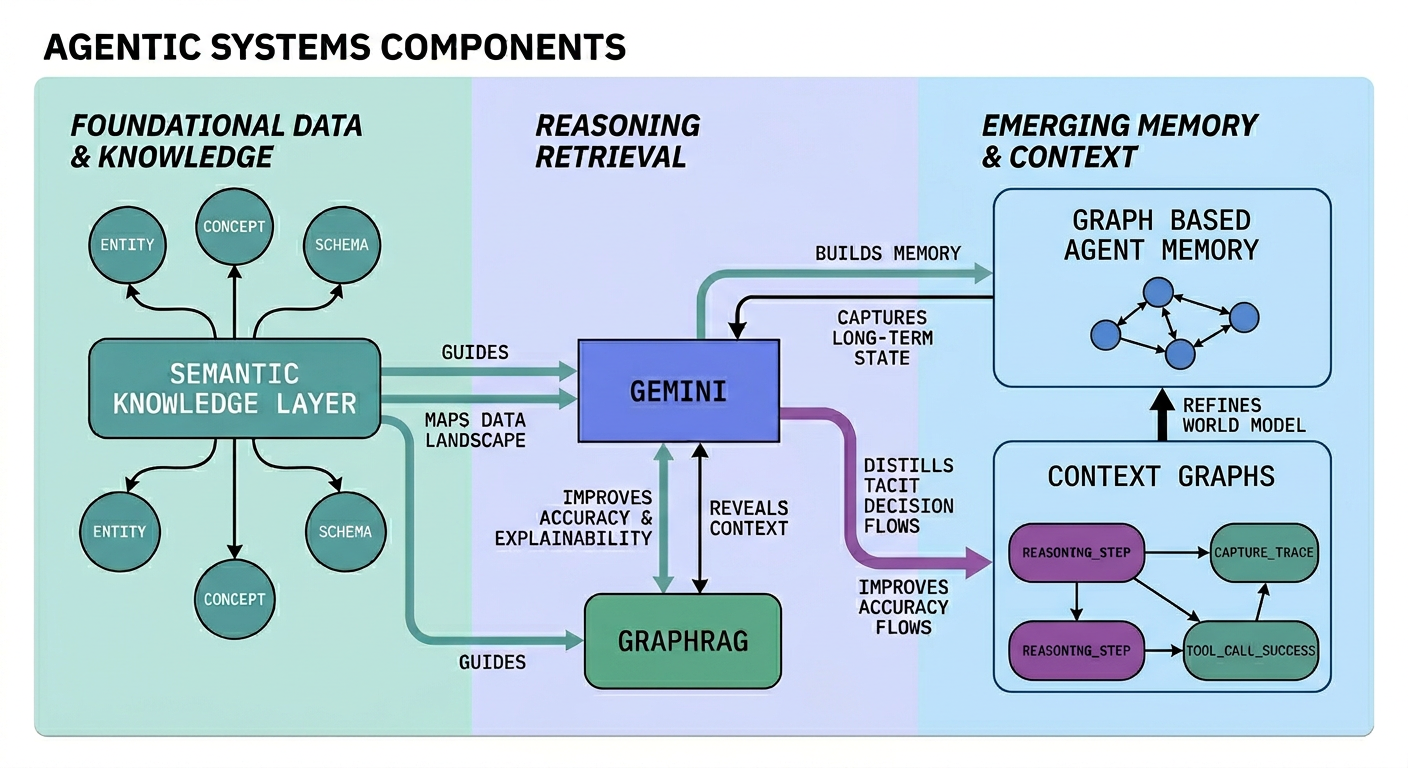
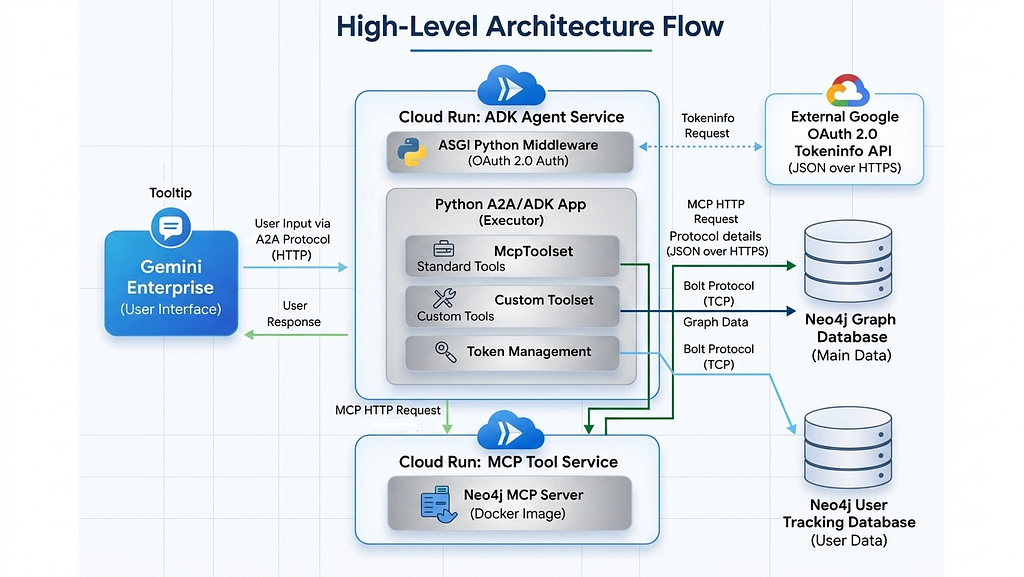


Architecting Graph-Based Agentic System: When a Regulator Asks “Why Was This Loan Approved?”
