


Text2Cypher Across Languages: Evaluating Foundational Models Beyond English


5 min read

Written by Makbule Gulcin Ozsoy and William Tai
The Text2Cypher task focuses on converting natural language questions into Cypher queries, which are used to interact with Neo4j graph databases. For example, the question “What are the movies of Tom Hanks?” should be translated into the following Cypher query: MATCH (actor:Person {name: "Tom Hanks"})-[:ACTED_IN]->(movie:Movie) RETURN movie.title.
This question can be asked in different languages, such as English, Spanish, or Turkish. No matter the language, the correct Cypher query should remain the same. In late 2024, we released the Neo4j Text2Cypher (2024) dataset and shared our first analysis of model performance on this task.
In this blog post, we focus on evaluating how well large language models (LLMs) perform on this task across multiple languages. Our main goal is to understand how the input language affects the quality of the generated Cypher queries. To do this, we:
- Created a test set with questions in English, Spanish, and Turkish, all linked to the same Cypher query
- Released this multilingual test set publicly for others to use and build upon
- Evaluated several foundational LLMs using standard prompts and metrics and compared their performance
Text2Cypher Dataset In Multiple Languages
The original Neo4j Text2Cypher (2024) dataset is in English. It includes natural language questions, the database schema, the corresponding Cypher queries (ground truth), and related metadata. To evaluate how well LLMs perform across different languages, we translated the test split’s question field into Spanish and Turkish. This allows us to compare model performance in English, Spanish, and Turkish using the same Cypher queries for all three.
Why Spanish and Turkish?
We selected Spanish and Turkish for two main reasons:
- Language resource levels — Language resource levels indicate how well-resourced a language is in terms of available data, tools, and research support. While English is a high-resource language, Spanish is also high-resource, and Turkish is a medium-resource language.
- Language families — Language families indicate relationships between languages, grouping them based on common origins and shared linguistic features. While English and Spanish are Indo-European languages, Turkish is an Altaic language with distinct linguistic traits.
These languages were chosen to represent a diverse range of linguistic and resource characteristics. We also aimed to include less-studied languages to support broader research and give back to the community.
How We Translated the Dataset
We followed these steps to translate the questions while keeping important information intact:
- Masking named entities and quotes: To prevent translation errors, we first masked named entities (e.g., names, places) and quoted strings with placeholders.
For example:
Original: “Hello, I work at ‘Neo4j’ in London”
Masked: “Hello, I work at QUOTE_0 in LOCATION_0” - Translation using an LLM: We used the GPT-4o mini model to translate the masked sentences into Spanish and Turkish. We provided a structured prompt to guide the model.

- Restoring masks: After translation, we replaced the placeholders with the original named entities and quoted text to recreate the final question.
Note that the ground-truth Cypher queries were not translated. These queries contain Cypher-specific syntax (e.g., MATCH, WHERE), terms from the schema (e.g., Person, ACTED_IN, Movie), and user-provided literals (e.g., “Tom Hanks”), all of which are intended to remain in their original form.
We have publicly shared the multilingual version of the Text2Cypher test set in our HuggingFace repository. This enables others to conduct their own cross-lingual evaluations and contribute to multilingual research in structured query generation.
Three GraphRAG Patterns Every Developer Should Know
Transform your RAG system from vague to precise. Learn to use three retrieval patterns that bring context and relationships into your applications.
Experimental Setup
We execute the experiments on the publicly shared multilingual Text2Cypher test set. We use the Unsloth versions of foundational models (with Instruct and quantized to 4-bit precision):
- Gemma-2–9b-it: Released in June 2024; primarily supports English
- Meta-Llama-3.1–8B-Instruct: Released in July 2024; primarily supports English and several European languages
- Qwen2.5–7B-Instruct: Released in September 2024; primarily supports Chinese and English and maintains multilingual support for more than 29 languages
For the Text2Cypher task, we use the same prompts as in previous works.

After generation, an additional post-processing step is used for removing unwanted text, such as the ‘cypher:’ suffix. We use the HuggingFace Evaluate library to compute evaluation metrics. We employ two evaluation procedures:
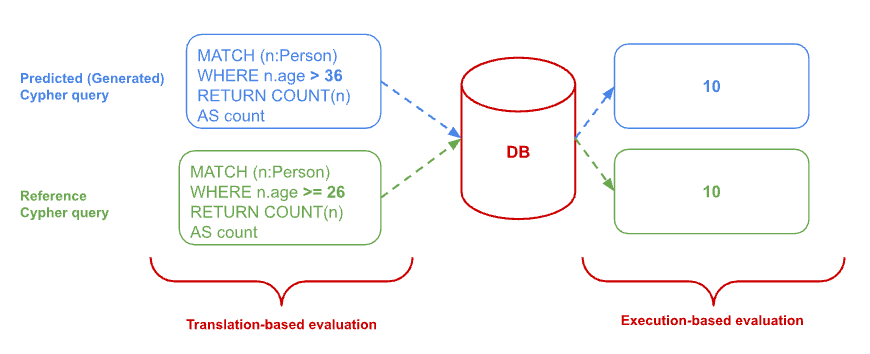
- Translation (Lexical)-based evaluation: This approach compares the generated Cypher queries with the ground-truth queries textually. Here, we present the ROUGE-L score as our metric for translation-based evaluation.
- Execution-based evaluation: In this procedure, both the generated and ground-truth Cypher queries are executed on the target database. The outputs are then compared using the same evaluation metrics applied in the translation-based evaluation. Here, we present the ExactMatch score as our metric for this kind of evaluation.
Experimental Results
We evaluate foundational LLMs on the Text2Cypher task across English, Spanish, and Turkish, focusing on how both the question and prompt language influence results.
Question Language
We first tested how the language of the input question affects performance, keeping the prompt in English across all cases.
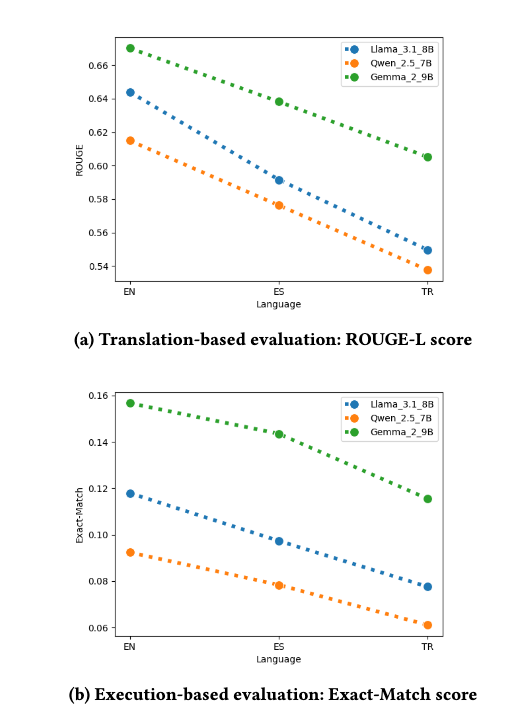
- Models performed best on English, followed by Spanish, and worst on Turkish.
- This trend reflects differences in language resource levels; LLMs generally do better with languages that have more training data.
- Linguistic similarity also plays a role. Models often generalize better across related languages (Dhamecha et al., 2021). English and Spanish are both Indo-European languages, while Turkish belongs to a different family (Altaic), which may make generalization harder.
Prompt Language
Next, we examined whether translating the prompt to match the question language would improve results. We translated prompts into Spanish and Turkish and evaluated models using matching prompts and questions.

The prompt translation had limited impact on final performance in this setup. Translation-based evaluation’s ROUGE-L scores improved slightly (by 1–1.5 percent), but execution-based evaluation’s ExactMatch score remained about the same.
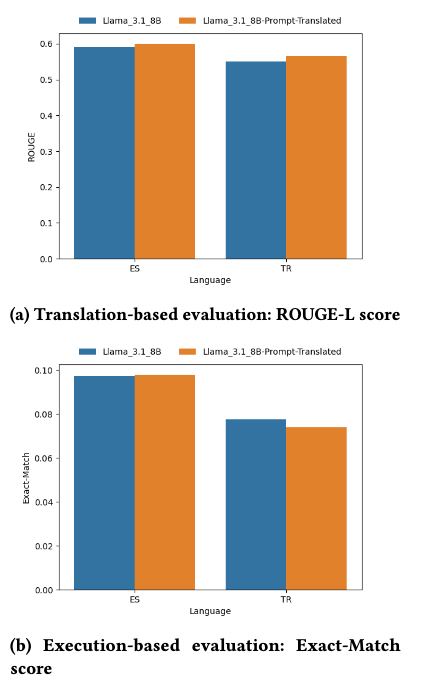
Note that the schema elements (e.g., node and relationship names) were kept in English. Future work could explore fully localized setups, where the schema is also translated, to better understand the interaction between language and model performance.
Summary and Next Steps
In this post, we explored how question language impacts model performance on the Text2Cypher task. Using translated questions in Spanish and Turkish, we created a multilingual test set with shared Cypher queries to enable fair comparisons across languages.
Our findings show that models perform best in English, followed by Spanish, and lowest in Turkish — likely due to differences in training data and language structure. Translating the task prompts provided a small improvement in text-based metrics, but had little effect on execution accuracy.
Future work could explore schema localization, language-specific fine-tuning, and expanding evaluations to more languages, especially those that are less commonly represented in current datasets.
Text2Cypher Across Languages: Evaluating Foundational Models Beyond English was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


