


Under the Covers With LightRAG: Retrieval

Solutions Engineer, Neo4j
15 min read

Disclaimer: At Neo4j, we see LightRAG as a technique classified under GraphRAG. There are currently no production-level statistics showing that LightRAG delivers meaningful improvements in real-world enterprise environments.
In this second part of this blog series, we’ll take a deep dive into how the LightRAG retrieval engine works. If you jumped straight here, you might want to check out the first installment, where we explored how LightRAG transforms unstructured documents into structured knowledge. Think of it like learning how the engine works before taking the car for a spin.
TL;DR
- Get comprehensive answers from multiple angles: LightRAG runs two searches simultaneously: one that follows relationship patterns in your knowledge graph and another that finds semantically similar content from a vector store. Both retrievals then tap into a key-value store based on the retrieved information to enrich context with stored metadata.
- Questions are understood more naturally: Instead of basic keyword matching or pure semantic search based on the user’s query, LightRAG extracts two types of keywords from the user’s question — high-level themes (what the query is about) and low-level specifics (who or what it’s about). This helps it understand both the big picture and the important details, making retrieval more precise and contextual.
- Prioritize what matters most in your knowledge: Rather than just finding relevant information, LightRAG prioritizes based on how well-connected and central things are in your knowledge network. It surfaces the most influential relationships and entities that act as bridges between concepts first. This ensures that you get the most important context, not just the most similar text.
Retrieval Process: A Dual-Level Hybrid Strategy
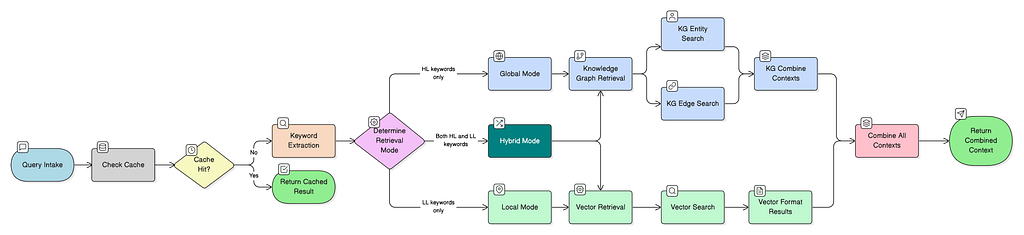
The retrieval strategy used in LightRAG combines graph traversal with semantic vector similarity. This hybrid approach aims to be accurate and explainable, which is ideal for tasks that require contextual depth and traceability. For this discussion, we’ll focus on the hybrid retrieval strategy.
Overview: Two Parallel Retrieval Paths
In LightRAG’s mix mode, retrieval happens along two parallel paths:
(A) get_kg_context() retrieves structured knowledge from the graph and surrounding documents using:
- Dual-level keyword semantic search
- Graph traversal over entities and relationships
(B) get_vector_context() retrieves unstructured semantic matches using:
- Full query embedding (with optional chat history)
- Pure vector similarity search across raw document chunks
# lightrag/operate.py
kg_context, vector_context = await asyncio.gather(
get_kg_context(), get_vector_context()
)Dual-Level Keyword Extraction
One of the most interesting aspects of this process is how LightRAG handles a user’s query using a concept the authors call dual-level keyword extraction. In this approach, an LLM is prompted to extract two complementary sets of keywords — high-level and low-level keywords — as shown in the prompt below:
# lightrag/prompts.py
PROMPTS["keywords_extraction"] = """---Role---
You are a helpful assistant tasked with identifying both high-level and low-level keywords in the user's query and conversation history.
---Goal---
Given the query and conversation history, list both high-level and low-level keywords. High-level keywords focus on overarching concepts or themes, while low-level keywords focus on specific entities, details, or concrete terms.
---Instructions---
- Consider both the current query and relevant conversation history when extracting keywords
- Output the keywords in JSON format, it will be parsed by a JSON parser, do not add any extra content in output
- The JSON should have two keys:
- "high_level_keywords" for overarching concepts or themes
- "low_level_keywords" for specific entities or details
######################
---Examples---
######################
{examples}
#############################
---Real Data---
######################
Conversation History:
{history}
Current Query: {query}
######################
The `Output` should be human text, not unicode characters. Keep the same language as `Query`.
Output:
"""- High-level keywords: broad concepts or themes
- Low-level keywords: specific entities or terms
Let’s say the user query is:
“What are the environmental consequences of deforestation on biodiversity?”
{
"high_level_keywords": ["Environmental consequences", "Deforestation", "Biodiversity loss"],
"low_level_keywords": ["Species extinction", "Habitat destruction", "Carbon emissions", "Rainforest", "Ecosystem"]
}High-level keywords help LightRAG understand what the query is about. Low-level keywords help LightRAG identify who or what it’s about. Together, they drive a hybrid retrieval strategy that’s both explainable and semantically rich.
(A) Dual-Level Keyword Retrieval
LightRAG takes a hybrid approach that blends semantic vector search with the power of graphs to power a grounded, explainable and flexible retrieval. Both paths leverage 1) vector similarity to surface semantically relevant content and 2) enrich it with graph traversal and metadata. For context, the discussion below is based on Neo4j’s implementation.

1) High-Level Keywords — Relationship-Centric Context Retrieval
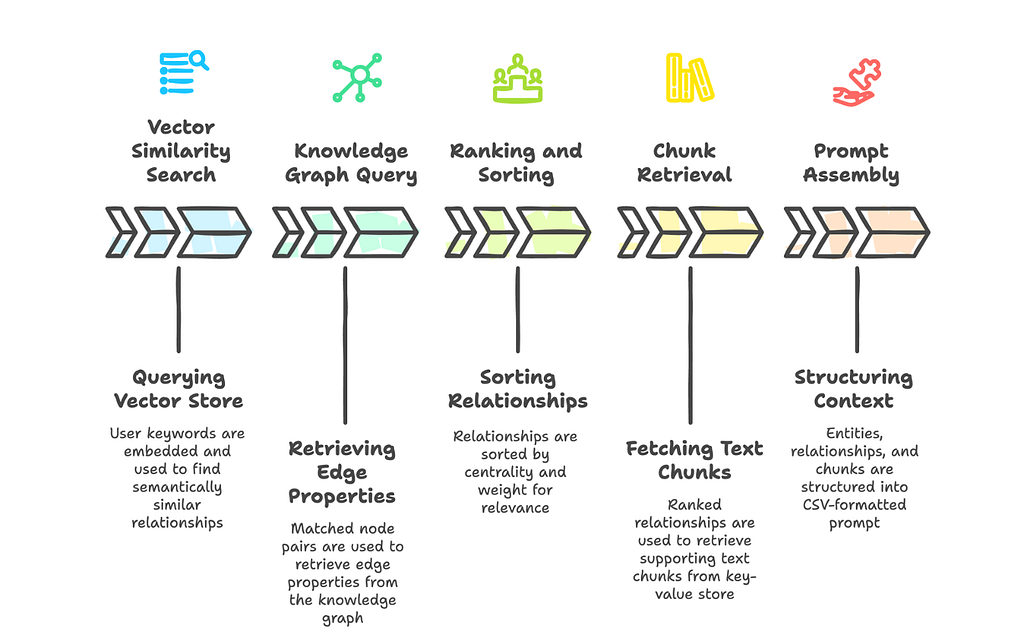
Recall that in the dual-level extraction process, each relationship is summarized using high-level keywords. From the extraction prompt, the keywords refer to abstract terms that encapsulate the overarching nature of the connection, rather than its surface details.
Step 1: Vector Similarity Search
These embedded content strings were previously indexed in a vector store during the extraction pipeline earlier:
# For relationship
content = f"{src_id}\t{tgt_id}\n{keywords}\n{description}"The high-level keywords extracted from the user’s query are then converted into a query embedding, which is then used for vector similarity comparison against the former to find semantically relevant relationships, even if the exact keywords don’t appear.
#lightrag/operate.py
results = await relationships_vdb.query(
keywords, top_k=query_param.top_k, ids=query_param.ids
)Step 2: Retrieving Relationship/Edge Properties From the Knowledge Graph
With the vector similarity search results, we’ll use the node pairs (src_id and tgt_id) to subsequently query the knowledge graph for an actual edge between the two matched nodes. This returns all edge properties — weight , description , keywords , source_id.
#lightrag/kg/neo4j_impl.py
query = """
MATCH (start:base {entity_id: $source_entity_id})-[r]-(end:base {entity_id: $target_entity_id})
RETURN properties(r) as edge_properties
"""Step 3a: Quantifying Graph Importance of the Relationship
Retrieves the degree of each source node and target node pair involved in the relationship. Computes the sum of their degrees to represent the combined centrality of the edge.
#lightrag/kg/neo4j_impl.py
query = """
MATCH (n:base {entity_id: $entity_id})
OPTIONAL MATCH (n)-[r]-()
RETURN COUNT(r) AS degree
"""Step 3b: Sort Relationships by Rank and Weight
The enriched relationships are sorted in descending order using two keys:
- rank — How central the nodes are (sum of degrees)
- weight — How strong the relationship is (from earlier extraction)
This ensures that well-connected and highly relevant relationships as judged by LLMs are surfaced first.
Recall that this weight property is based on the earlier extracted
relationship_strengthscore which comes from the LLM’s interpretation, not hard data. It’s like asking someone, “How close do you think these two people are?” rather than counting actual interactions. The LLM is making an educated guess based on context.
#lightrag/operate.py
edge_datas = sorted(
edge_datas, key=lambda x: (x["rank"], x["weight"]), reverse=True
)This process aims to ensure answers generated are not just relevant but highly centralized within the graph.
Step 3c: Retrieve Node Properties From the Knowledge Graph
After sorting the relationships, metadata for each unique entity involved in those top-ranked edges is retrieved. This includes attributes like entity_type and description.
#lightrag/kg/neo4j_impl.py
query = "MATCH (n:base {entity_id: $entity_id}) RETURN n"
...
node = records[0]["n"]
node_dict = dict(node) # Node metadata returned
...
return node_dictSimilarly, node_degree is calculated for each entity pair for subsequent ranking. If the total token size of the assembled node_datas exceeds the limit max_token_size, the result will be truncated to limit the token size.
#lightrag/operate.py
node_datas = [
{**n, "entity_name": k, "rank": d}
for k, n, d in zip(entity_names, node_datas, node_degrees)
if n is not None
]Step 4: Retrieve Text Chunks From Key-Value store
Using the ranked relationships from edge_datas in Step 3b), chunk IDs for each relationship’s source_id (which may look like “chunk-001|||chunk-002“) are split based on the delimiter and searched in the key-value store to retrieve the full chunk metadata. The final output is then sorted based on the original order of ranked relationships and then truncated if it exceeds the max_token_size.
#lightrag/operate.py
async def fetch_chunk_data(c_id, index):
if c_id not in all_text_units_lookup:
chunk_data = await text_chunks_db.get_by_id(c_id)
# Only store valid data
if chunk_data is not None and "content" in chunk_data:
all_text_units_lookup[c_id] = {
"data": chunk_data,
"order": index,
}Step 5: Combining Node, Relationship and Chunk Context
After retrieving:
- Semantically matched relationships via high-level keywords
- Corresponding edge metadata from the knowledge graph
- The entities involved in those edges (source and target nodes)
- The document chunks that referenced or supported those entities and relationships
The transformation assembles a prompt-ready, structured context in three sections:
#lightrag/operate.py
# structuring entities
entites_section_list.append(
[
i,
n["entity_name"],
n.get("entity_type", "UNKNOWN"),
n.get("description", "UNKNOWN"),
n["rank"],
created_at,
file_path,
]
)
entities_context = list_of_list_to_csv(entites_section_list)
...
# structuring relationships
relations_section_list = [
[
"id",
"source",
"target",
"description",
"keywords",
"weight",
"rank",
"created_at",
"file_path",
]
]
relations_context = list_of_list_to_csv(relations_section_list)
...
# structuring chunks
text_units_section_list = [["id", "content", "file_path"]]
text_units_context = list_of_list_to_csv(text_units_section_list)
...
return entities_context, relations_context, text_units_contextThese are returned as CSV-formatted string blocks, which seems to be advantageous as highlighted by another article, making it easy for the model to parse, reason over, and generate responses from.
#lightrag/operate.py
# structuring entities
entites_section_list.append(
[
i,
n["entity_name"],
n.get("entity_type", "UNKNOWN"),
n.get("description", "UNKNOWN"),
n["rank"],
created_at,
file_path,
]
)
entities_context = list_of_list_to_csv(entites_section_list)
...
# structuring relationships
relations_section_list = [
[
"id",
"source",
"target",
"description",
"keywords",
"weight",
"rank",
"created_at",
"file_path",
]
]
relations_context = list_of_list_to_csv(relations_section_list)
...
# structuring chunks
text_units_section_list = [["id", "content", "file_path"]]
text_units_context = list_of_list_to_csv(text_units_section_list)
...
return entities_context, relations_context, text_units_context2) Low-Level Keywords — Entity-Centric Context Retrieval

Similarly, during the dual-level extraction process, each entity is summarized using low-level keywords; they are the specific nouns, terms or concepts mentioned directly in the user’s query. These low-level keywords drive entity-focused retrieval where the most semantically and structurally relevant nodes from the knowledge graph are surfaced.
Step 1: Vector Similarity Search
Each entity’s content string was embedded in the vector store during the extraction pipeline using the format below.
# For entities
content = f"{entity_name}\n{description}"
# e.g., "Alex\nAlex is a character..."Identical to high-level relationship embeddings, these entity vectors were pre-indexed into the vector store. Low-level keywords are embedded at query time and compared against this index to retrieve semantically similar entities/nodes.
# lightrag/operate.py
results = await entities_vdb.query(
query, top_k=query_param.top_k, ids=query_param.ids
)Step 2: Retrieve Node Properties From the Knowledge Graph
Once vector similarity results are returned, each matched entity/node is looked up in the knowledge graph to retrieve its properties.
#lightrag/kg/neo4j_impl.py
query = "MATCH (n:base {entity_id: $entity_id}) RETURN n"
...
node = records[0]["n"]
node_dict = dict(node) # Node metadata returned
...
return node_dictStep 3a: Quantifying Graph Importance of the Entity
Just as relationships are ranked by edge centrality, entities are ranked by node degree, which is calculated based on the number of relationships a node has.
#lightrag/kg/neo4j_impl.py
query = """
MATCH (n:base {entity_id: $entity_id})
OPTIONAL MATCH (n)-[r]-()
RETURN COUNT(r) AS degree
"""A highly connected node is more likely to be influential or serve as a bridge in multihop reasoning.
Step 3b: Sort Entities by Degree (Rank)
Each entity is assigned a rank based on its node degree. The list of entities is sorted and then truncated based on the defined token limit.
# lightrag/operate.py
node_datas = [
{**n, "entity_name": k, "rank": d}
for k, n, d in zip(entity_names, node_datas, node_degrees)
if n is not None
]Step 3c: Retrieve Related Relationships From the Knowledge Graph
To enrich entity context, one–hop relationships are gathered for each retrieved entity. For each entity name, the one-hop edges are retrieved giving a list of node pairs.
#lightrag/kg/neo4j_impl.py
query = """MATCH (n:base {entity_id: $entity_id})
OPTIONAL MATCH (n)-[r]-(connected:base)
WHERE connected.entity_id IS NOT NULL
RETURN n, r, connected"""
...
source_label = (
source_node.get("entity_id")
if source_node.get("entity_id")
else None
)
target_label = (
connected_node.get("entity_id")
if connected_node.get("entity_id")
else None
)
if source_label and target_label:
edges.append((source_label, target_label))
...
return edgesFor each unique set of node pairs, edge/relationship metadata is fetched in parallel with the information of edge degree (sum of degrees of source and target node).
#lightrag/operate.py
all_edges_pack, all_edges_degree = await asyncio.gather(
asyncio.gather(*[knowledge_graph_inst.get_edge(e[0], e[1]) for e in all_edges]),
asyncio.gather(
*[knowledge_graph_inst.edge_degree(e[0], e[1]) for e in all_edges]
),
)Cypher query for the retrieval of edge properties:
#lightrag/kg/neo4j_impl.py
query = """
MATCH (start:base {entity_id: $source_entity_id})-[r]-(end:base {entity_id: $target_entity_id})
RETURN properties(r) as edge_properties
"""After the edge metadata and edge degree scores are collected, each relationship is represented as a dictionary that includes the source and target nodes, description, computed rank, and weight. These relationships are then sorted in descending order, first by rank (i.e., degree centrality), then by weight, then added to the final context.
#lightrag/operate.py
all_edges_data = [
{"src_tgt": k, "rank": d, **v}
for k, v, d in zip(all_edges, all_edges_pack, all_edges_degree)
if v is not None
]
all_edges_data = sorted(
all_edges_data, key=lambda x: (x["rank"], x["weight"]), reverse=True
)This sorting process is vital for the identification of highly influential relationships.
Step 4: Retrieve Text Chunks From the Key-Value Store
Similar to the relationship-based approach, this alternative implementation retrieves text chunks, but starts from ranked entity nodes rather than relationships. Both approaches follow the same core pattern:
- Extract chunk IDs from source fields
- Retrieve full chunk data from the key-value store
- Sort by relevance and truncate based on defined token limits
The key difference in this implementation is the relationship analysis. While the first approach directly retrieves chunks referenced by relationships, this version:
- Identifies one-hop neighboring entities in the knowledge graph
- Counts relationship occurrences for each chunk
- Uses these counts as an additional ranking factor
#lightrag/operate.py
# Retrieve chunks with batch processing
batch_size = 5
results = []
for i in range(0, len(tasks), batch_size):
batch_tasks = tasks[i : i + batch_size]
batch_results = await asyncio.gather(
*[text_chunks_db.get_by_id(c_id) for c_id, _, _ in batch_tasks]
)
results.extend(batch_results)
# Track relationship density for each chunk
for (c_id, index, this_edges), data in zip(tasks, results):
all_text_units_lookup[c_id] = {
"data": data,
"order": index,
"relation_counts": 0, # Relationship density tracking
}The final output is sorted by the original entity ranking order first, then by relationship density, ensuring that chunks that connect multiple entities are prioritized.
#lightrag/operate.py
# Sort by entity order and relationship density
all_text_units = sorted(
all_text_units, key=lambda x: (x["order"], -x["relation_counts"])
)
# Truncate to respect token limits
all_text_units = truncate_list_by_token_size(
all_text_units,
key=lambda x: x["data"]["content"],
max_token_size=query_param.max_token_for_text_unit,
)What’s unique in the entity-centric path is that chunk scoring incorporates graph neighbor overlap.
Step 5: Combining Node, Relationship, and Chunk Context
Regardless of whether entities or relationships served as the starting point for retrieval, both approaches are similar in the post-processing of retrieval outputs. These components are then finally transformed into a structured, prompt-ready CSV-formatted context. Refer to Step 5 in the section under Relationship-Centric Context Retrieval above for an in-depth explanation of how each component is extracted and assembled.
Combined Context — Relationship- and Entities-Centric
After separately retrieving context using both low-level (entities) and high-level (relationships) keywords, the combined contexts are again cleaned, de-duplicated, and recombined into CSV-formatted string blocks.
#lightrag/utils.py
def process_combine_contexts(hl: str, ll: str):
header = None
list_hl = csv_string_to_list(hl.strip())
list_ll = csv_string_to_list(ll.strip())
...
combined_sources = []
seen = set()
for item in list_hl + list_ll:
if item and item not in seen:
combined_sources.append(item)
seen.add(item)
...
for i, item in enumerate(combined_sources, start=1):
combined_sources_result.append(f"{i},\t{item}")
return "\n".join(combined_sources_result)(B) Pure Semantic Vector Similarity Retrieval
While the dual-level keyword retrieval (discussed in Section A) focuses on retrieval via knowledge graph, LightRAG simultaneously runs a semantic vector search in parallel.
Step 1: Query Augmentation With Conversation History
To make the vector search more conversationally aware, the user’s current query is augmented with the conversation history.
#lightrag/operate.py
async def get_vector_context():
# Consider conversation history in vector search
augmented_query = query
if history_context:
augmented_query = f"{history_context}\n{query}"
...The addition of conversation history aims to capture ongoing intent, topic continuity, and implicit references from earlier turns, which could be useful for multi-turn interactions.
Step 2: Retrieval Via Vector Store and Key-Value Store
The augmented query is then embedded and used to retrieve semantically similar chunks from a pre-indexed vector store. For each result, the actual content is also retrieved from a key-value store using the unique chunk ID.
#lightrag/operate.py
# Reduce top_k for vector search in hybrid mode since we have structured information from KG
mix_topk = min(10, query_param.top_k)
results = await chunks_vdb.query(
augmented_query, top_k=mix_topk, ids=query_param.ids
)
if not results:
return None
# key-value chunk lookup
chunks_ids = [r["id"] for r in results]
chunks = await text_chunks_db.get_by_ids(chunks_ids)When running in hybrid mode, the vector search uses a smaller top_k value since the knowledge graph already provides structured information.
Step 3: Chunk Metadata Enrichment
Each chunk is then formatted and enriched with important metadata:
- File path
- Creation timestamp
#lightrag/operate.py
# Include time information in content
formatted_chunks = []
for c in maybe_trun_chunks:
chunk_text = "File path: " + c["file_path"] + "\n" + c["content"]
if c["created_at"]:
chunk_text = f"[Created at: {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(c['created_at']))}]\n{chunk_text}"
formatted_chunks.append(chunk_text)
...
return "\n--New Chunk--\n".join(formatted_chunks)The chunks are carefully formatted with the --New Chunk-- delimiter to avoid context bleeding across chunks and ease of tracking based on timestamp.
Combining Hybrid Retrieval Results
After retrieving results from both the knowledge graph and document chunk vector search pathways, the two retrieval results will be carefully merged. This marks the final phase of the retrieval pipeline before the answer generation prompt is constructed.
#lightrag/prompts.py
sys_prompt = PROMPTS["mix_rag_response"].format(
kg_context=kg_context or "No relevant knowledge graph information found",
vector_context=vector_context or "No relevant text information found",
response_type=query_param.response_type,
history=history_context,
)
PROMPTS["mix_rag_response"] = '''
---Role---
You are a helpful assistant responding to user query about Data Sources provided below.
---Goal---
Generate a concise response based on Data Sources...
---Conversation History---
What did we discuss about deforestation last time?
---Data Sources---
1. From Knowledge Graph(KG):
Alex → Taylor: "Power dynamic conflict" [2023-10-15], weight: 7
2. From Document Chunks(DC):
[Created at: 2023-11-12 14:02:31]
File path: reports/biodiversity_impacts.txt
Deforestation disrupts ecosystems and can lead to extinction-level threats...
---Response Rules---
- Use markdown formatting with appropriate section headings
- Organize in sections like: **Causes**, **Consequences**, **Recent Observations**
- Reference up to 5 most important sources with `[KG/DC] file_path`
'''This approach provides the LLM with both structured knowledge graph information and unstructured vector-retrieved content, offering complementary perspectives on the user’s query:
- Knowledge graph context: Explicit entities, relationships, and supporting facts with clear structure
- Vector context: Broader semantic matching with full textual context
By combining these approaches, LightRAG leverages the strengths of both retrieval methods:
- Knowledge graphs excel at capturing explicit relationships and structured information.
- Vector search excels at capturing semantic similarity and implicit connections.
The resulting hybrid context delivers more comprehensive, accurate, and contextually grounded responses to user queries.
Summary
By bringing together knowledge graph-based reasoning and semantic search, LightRAG may offer incremental improvements in academic settings, though conclusive production-level results have yet to be demonstrated. LightRAG represents just one limited implementation within the more mature and broader GraphRAG ecosystem.
What makes it special is how graph structure is used to prioritize information. Instead of just storing facts in a graph, it uses connection patterns to determine what’s most important. This means the system surfaces central, relevant information first rather than just finding keyword matches.
The practical benefits are clear: With its flexible design, you can add new information without rebuilding everything. This makes it particularly valuable for businesses where knowledge constantly evolves.
Next Steps
Stay tuned for the final installment of Under the Covers With LightRAG: Neo4j Meets LightRAG, where we will bring it all together and walk through the implementation of LightRAG with Neo4j.
Ready to take LightRAG for a spin? Check it out on GitHub, drop me a comment below, or connect with me via email or on LinkedIn.
See you next time!
Under the Covers With LightRAG: Retrieval was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
The Developer’s Guide:
How to Build a Knowledge Graph
This ebook gives you a step-by-step walkthrough on building your first knowledge graph.
Share Article



Explore
Related Articles
