Beyond Vector Search: Unleashing the Power of GraphRAG for Smarter Recommendations

Developer Relations Lead, APAC, Neo4j
4 min read

What if your GenAI chatbot could not only understand what you’re saying but also why it matters — and respond with rich, connected context from a knowledge graph?
Welcome to the next frontier of GenAI-powered retrieval: GraphRAG.

🎬 From Embeddings to Intelligence: Why Vector RAG Isn’t Enough
When I first built a movie recommendation chatbot using Neo4j and Google Vertex AI, the approach was simple but effective: generate text embeddings from movie overviews, store them in Neo4j, and use vector similarity search to recommend movies based on user queries. That version worked well. It understood “movies like Interstellar” and returned relevant results based on plot similarity.
- “Because you liked this director’s sci-fi work …”
- “This actor starred in another movie with similar themes …”
- “This genre blend has been trending in the same decade …”
To make this leap, we need more than vectors. We need reasoning.
🔁 Enter GraphRAG: Retrieval That Thinks in Relationships
Graph-based Retrieval-Augmented Generation (GraphRAG) is a game-changer. It still starts with vector search — using embeddings to narrow down relevant documents or nodes. But here’s the magic: It doesn’t stop there.
Once the relevant context is found, GraphRAG uses LLMs to generate Cypher queries (in Neo4j’s case) based on the ontology of your knowledge graph. This enables it to:
- Traverse multi-hop relationships
- Enrich responses with structured context
- Execute precise queries over a graph
- Generate answers that are grounded, explainable, and connected

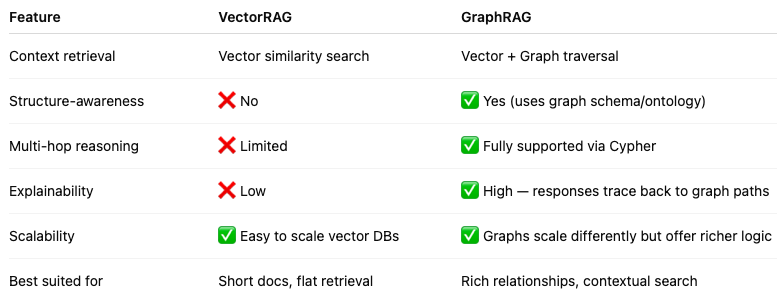
🧠 VectorRAG vs. GraphRAG: What’s the Real Difference?
🛠️ Bringing GraphRAG to Life: Movie Chatbot Edition
I recently reworked the original Neo4j and Vertex AI movie chatbot to incorporate GraphRAG. The architecture now looks like this:
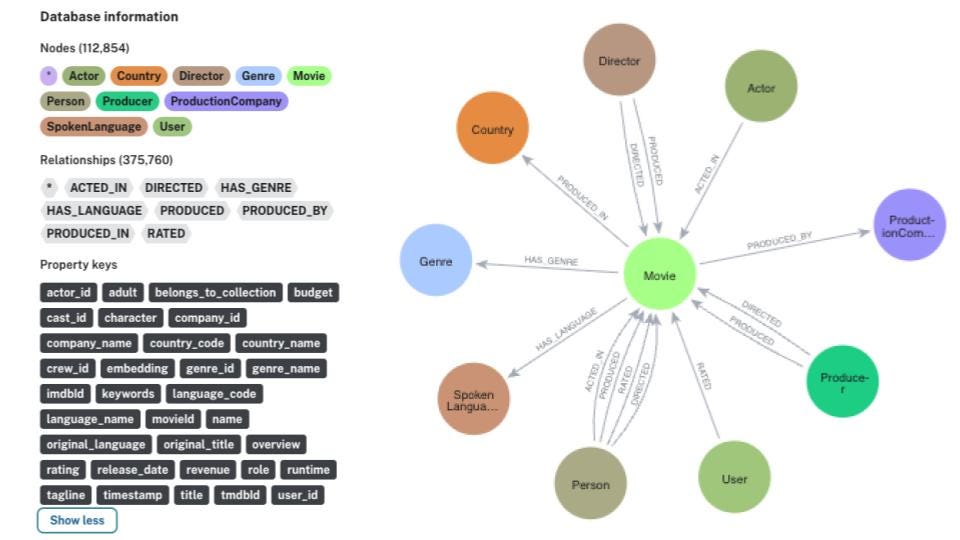
- Build a knowledge graph of movies, actors, genres, directors, etc.
- Generate embeddings for movie overviews using Vertex AI’s text-embedding-004.
- Use vector search to find semantically similar movies.
- Use Gemini (via Vertex AI) to:
– Interpret the user query
– Generate Cypher queries
– Execute them on Neo4j
– Summarize results in conversational format - Deploy the chatbot to Google Cloud Run — serverless and scalable.
Now, when a user asks:
“What should I watch if I liked Interstellar?”
The system understands the plot, pulls in vector-similar movies, identifies directors, genres, and timeframes, then responds with contextual, multi-hop, personalized suggestions.
🌐 Deploying to the Cloud (Bonus!)
Want to take your chatbot from local to global? You can deploy the entire app — built with Python, Gradio, and Docker — to Google Cloud Run, a fully managed serverless platform from Google Cloud.
✅ No servers to manage
✅ No GPUs required
✅ Just semantic graph-powered intelligence running securely, scalably, and globally
🚀 Step-by-Step Deployment
1. Set Your Environment Variables
export GCP_PROJECT='your-project-id' # Change this
export GCP_REGION='us-central1' # Or your preferred region
export AR_REPO='movies-reco' # Artifact Registry repo name
export SERVICE_NAME='movies-reco' # Cloud Run service name2. Create Your Docker Image and Push It
# Create Artifact Registry repo (if not already created)
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker to use Google Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit your container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"3. Prepare Your Environment Config
Create a .env.yaml file in your project root with:
NEO4J_URI: "bolt+s://<your-neo4j-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>"This file securely passes required variables to your Google Cloud Run service at runtime.
4. Deploy to Google Cloud Run
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml🎯 That’s It!
You’ll get a live URL like https://movies-reco-xyz123-uc.a.run.app.
Visit the link to chat with your LLM-powered GraphRAG-enabled movie recommender — running serverlessly on the cloud!
🚀 Want to Try It Yourself?
You can explore the full walkthrough in this updated hands-on GraphRAG-powered codelab — no prior experience with graphs or GenAI required.
👀 If you’re just getting started, you might want to check out my earlier post that walks through the basics of loading movie data, building the knowledge graph, and generating embeddings:
👉 Build an Intelligent Movie Search with Neo4j and Vertex AI
💭 Final Thoughts
As GenAI continues to evolve, it’s becoming increasingly clear: Data alone isn’t enough. The real power comes from structure + semantics + language — and that’s exactly what GraphRAG delivers.
Whether you’re building movie recommenders, enterprise search, legal research tools, or knowledge assistants, if relationships matter, GraphRAG is your edge.
So go ahead: embed, connect, and generate. The graph is your playground.
Have thoughts or feedback? Drop them in the comments or connect with me on social media. Learn more about me at https://meetsid.dev/.
If you enjoyed this post, give it a 👏 below and follow me on Medium and LinkedIn to get updates on upcoming articles. And don’t forget to ★ the GitHub repo.
Beyond Vector Search: Unleashing the Power of GraphRAG for Smarter Recommendations was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles