








Unleashing the Power of Schema: What’s New in the Neo4j GraphRAG Package for Python

Senior Software Engineer, Neo4j
9 min read
Imagine effortlessly turning your unstructured data into rich knowledge graphs and querying them with natural language. Over the past year, GraphRAG applications have gotten a lot of attention, yet creating high-quality knowledge graphs from raw data remains a major bottleneck.
The use of large language models (LLMs) for entity relationship extraction (ERE) tasks has significantly eased the knowledge graph construction process. That said, without proper guidance, even the most powerful LLM can produce irrelevant or inconsistent nodes and relationships, leading to poor downstream question-answering performance.
This is exactly why a schema matters! Think of a schema as your blueprint, guiding the LLM in what to extract. However, defining a schema can be challenging, especially for non-experts or when dealing with complex and evolving data.
The good news: Whether you’re a knowledge graph novice or seasoned graph pro, you can now improve your knowledge graph construction process thanks to the new schema capabilities introduced in the Neo4j GraphRAG Package for Python (neo4j-graphrag). As of version 1.8.0, you can now:
- Automatically infer schema from text
- Apply flexible schema enforcement options
- Have granular control over the extraction process
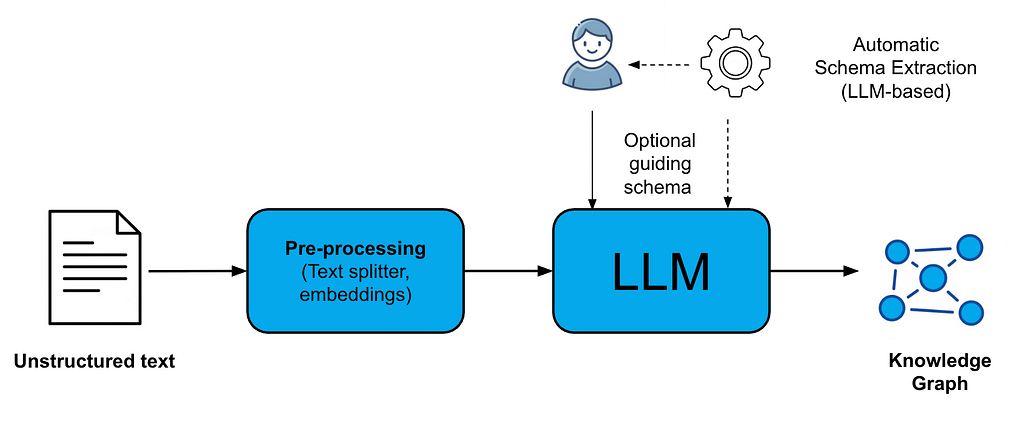
In this blog, we’ll take a closer look at each of these features.
Example: Constructing Knowledge Graphs for Cyber Threat Intelligence
Cyber threat intelligence (CTI) involves collecting, analyzing, and sharing information about potential or ongoing cyber threats to proactively identify, mitigate, and respond to cyberattacks.
Consider extracting insights from the Cybersecurity and Infrastructure Security Agency (CISA) advisory, such as AA21–287A: Ongoing Cyber Threats to U.S. Water and Wastewater Systems. The latter describes threat actors targeting water infrastructure, lists real incidents, and includes recommended mitigations.
For Beginners: Effortless Schema Integration Guiding Knowledge Graph Construction
If you’re new to knowledge graphs and just getting started with the neo4j-graphrag Python package, building a cybersecurity knowledge graph from advisories like AA21–287A is straightforward.
Simply configure your pipeline by specifying your preferred embedding model, the LLM along with relevant parameters for ERE, and your Neo4j database connection details where the resulting knowledge graph will be stored:
import neo4j
import os
from dotenv import load_dotenv
from neo4j_graphrag.embeddings import OpenAIEmbeddings
from neo4j_graphrag.llm import OpenAILLM
# This example requires adding OPENAI_API_KEY, and Neo4j connection details to a .env file
load_dotenv()
# Create the embedder instance
embedder = OpenAIEmbeddings()
# Create the llm instance
llm = OpenAILLM(
model_name="gpt-4o",
model_params={
"max_tokens": 2000,
"response_format": {"type": "json_object"},
"temperature": 0,
},
)
# Initialize the Neo4j driver
# If a local Neo4j dbms instance is used, this example requires the APOC plugin to be installed
URI = os.getenv("NEO4J_URI")
AUTH = (os.getenv("NEO4J_USER"), os.getenv("NEO4J_PASSWORD"))
driver = neo4j.GraphDatabase.driver(URI, auth=AUTH)Run SimpleKGPipeline with the embedder, LLM, and Neo4j driver instances. Under the hood, the pipeline automatically infers a schema to guide the LLM in the extraction of relevant nodes and relationships:
from neo4j_graphrag.experimental.pipeline.kg_builder import SimpleKGPipeline
# Create a SimpleKGPipeline instance without providing a schema
# This will trigger automatic schema extraction
kg_builder = SimpleKGPipeline(
llm=llm,
driver=driver,
embedder=embedder,
from_pdf=True,
)
# Run the pipeline on the PDF file
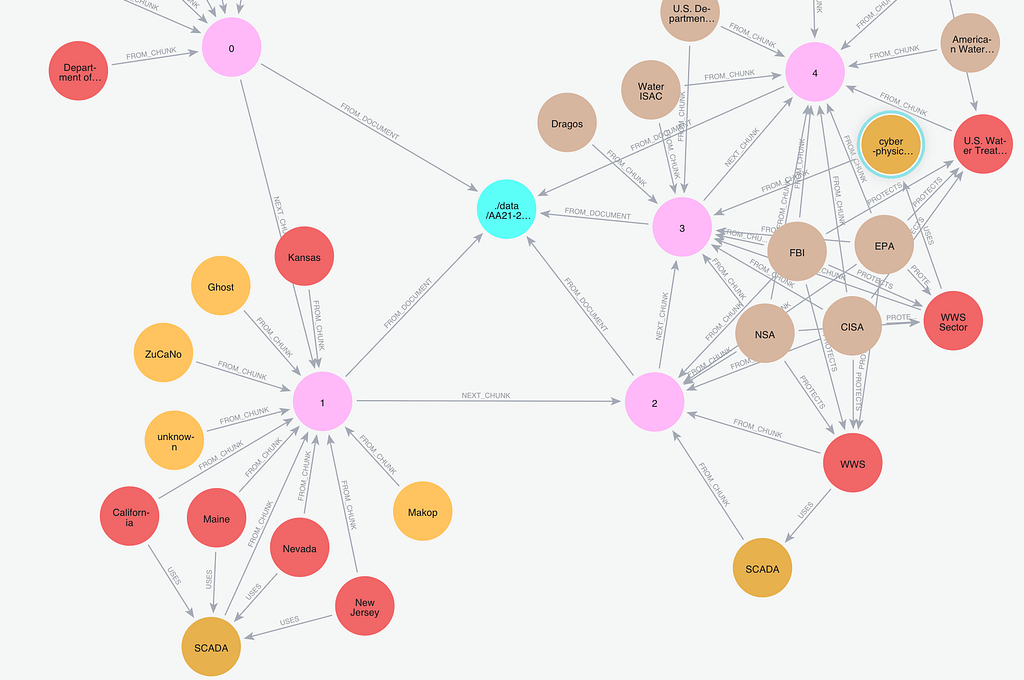
await kg_builder.run_async(file_path="AA21–287A.pdf")Now, a knowledge graph is created, highlighting key entities and relationships described in the advisory. Here’s an illustrative example of how such a graph may appear:
The resulting graph consists of two complementary parts:
- The lexical subgraph describes the knowledge that is purely related to the processing of the text into chunks, their characteristics (e.g., embeddings, etc.), and the relationships between them (e.g.,
FROM_DOCUMENT,NEXT_CHUNK). - The domain subgraph describes the knowledge related to the domain (e.g., cybersecurity) — real-world entities (e.g.,
Ransomware,Organization,ThreatActor) and relationships between them (TARGETS,PROTECTS,USES).
For more details on the graph shape, see GraphRAG.
If you’re curious about what happens under the hood, neo4j-graphrag allows you to enable detailed logging so you can inspect each step of the pipeline, including the schema inferred from your documents. To do this, configure logging before running the pipeline:
import logging
# Set log level to Debug
logging.basicConfig()
logging.getLogger("neo4j_graphrag").setLevel(logging.DEBUG)With logging enabled, you’ll see a JSON-formatted schema output in your logs, particularly from the SchemaFromTextExtractor component. This inferred schema includes the extracted node types, relationship types, their optional properties, and the patterns that describe how these elements are connected. Here’s an example:
{
"node_types": [
{
"label": "Organization",
"description": "",
"properties": [
{
"name": "name",
"type": "STRING",
"description": "",
"required": false
}
],
"additional_properties": false
},
{
"label": "Facility",
"description": "",
"properties": [
{
"name": "location",
"type": "STRING",
"description": "",
"required": false
}
],
"additional_properties": false
},
{
"label": "ThreatActor",
"description": "",
"properties": [],
"additional_properties": true
},
{
"label": "Ransomware",
"description": "",
"properties": [],
"additional_properties": true
},
{
"label": "System",
"description": "",
"properties": [
{
"name": "type",
"type": "STRING",
"description": "",
"required": false
}
],
"additional_properties": false
}
],
"relationship_types": [
{
"label": "TARGETS",
"description": "",
"properties": [],
"additional_properties": true
},
{
"label": "USES",
"description": "",
"properties": [],
"additional_properties": true
},
{
"label": "PROTECTS",
"description": "",
"properties": [],
"additional_properties": true
}
],
"patterns": [
["ThreatActor", "TARGETS", "Facility"],
["ThreatActor", "USES", "Ransomware"],
["Organization", "PROTECTS", "Facility"],
["Facility", "USES", "System"]
],
"additional_node_types": false,
"additional_relationship_types": false,
"additional_patterns": false
}Once the schema is inferred, the pipeline also attaches default enforcement flags, which we’ll explore in the next section.
For Graph Experts: Flexible Schema Enforcement at Different Schema Levels
If you’d like more control over the guiding schema without having to configure the full knowledge graph pipeline manually, you can still use SimpleKGPipeline and supply your own schema using the schema parameter. This gives you the flexibility to shape what gets extracted while keeping the developer experience simple. You can pass the schema in two ways:
- As a dictionary: Define keys like
node_types,relationship_types, andpatterns, each containing a list of definitions. These can be as minimal as labels or as detailed as descriptions and property lists, along with triples representing connection patterns. - As a literal:
–“FREE”disables schema enforcement entirely.
–“EXTRACTED”enables automatic schema inference from text.
NODE_TYPES = [
# Node types can be defined with a simple label
"Facility",
"Organization",
# or with a dict if more details are needed
# such as a description
{"label": "ThreatActor", "description": "Represents an individual, group, or organization responsible for carrying out or coordinating malicious cyber activities."},
# or a list of properties
{"label": "Ransomware", "properties": [{"name": "name", "type": "STRING", "required": True}, {"name": "family", "type": "STRING"}]},
]
# Same for relationships:
RELATIONSHIP_TYPES = [
"TARGETS",
{
"label": "USES",
"description": "Indicates that an entity is using a malware or tool to carry out an action on another entity.",
},
{"label": "PROTECTS", "properties": [{"name": "protectionLevel", "type": "STRING"}]},
]
PATTERNS = [
("ThreatActor", "TARGETS", "Facility"),
("ThreatActor", "USES", "Ransomware"),
("Organization", "PROTECTS", "Facility"),
]
kg_builder = SimpleKGPipeline(
llm=llm,
driver=driver,
embedder=embedder,
schema ={
"node_types": NODE_TYPES,
"relationship_types": RELATIONSHIP_TYPES,
"patterns": PATTERNS,
"additional_node_types": False,
},
# schema="EXTRACTED" # enable automatic schema extraction
# schema="FREE", # no guiding schema at all in the extraction process
from_pdf=True,
)In addition to defining schema elements, the neo4j-graphrag Python package allows you to control schema enforcement at multiple levels of granularity. This lets you tune how strictly the output of the model should adhere to your definitions when constructing the graph. You can enforce schema at:
- Property level — Any property in a node or relationship type can be marked as required. If a required property is missing in an extracted entity, that entity will be excluded from the graph.
- Node/Relationship level — Use
additional_propertiesto allow/disallow, for that node/relationship type, additional properties not explicitly defined in the schema. - Graph level — Use
additional_node_types,additional_relationship_types, andadditional_patternsto allow/disallow nodes, relationship types, and patterns not explicitly defined in the schema.
A rule of thumb: The more detail you define, the stricter the pipeline becomes by default. For example, if you define a list of relationship types or patterns, the pipeline assumes you only want those unless you override that with an explicit enforcement flag.
For example, when using the schema defined above to guide the extraction process, the resulting graph will include only the node and relationship types listed in the schema. For Facility and Organization nodes, any extra properties identified by the LLM will be retained. For ThreatActor and Ransomware, only the properties explicitly defined in the schema will be included. If a Ransomware node lacks the required name property, it’ll be excluded entirely from the final graph. On the relationship side, additional properties will be accepted on TARGETS and USES. For PROTECTS, only the schema-defined properties will be included.
This layered enforcement gives you fine-grain control over the quality and precision of your graph.
Understanding Additional Graph Cleanup Operations
In addition to the pruning operations done based on the user-defined schema enforcement configurations, the knowledge graph construction pipeline includes built-in graph cleanup operations that help ensure consistency and quality in the final graph. These include:
- Removing nodes and relationships with empty labels and types, respectively
- Removing nodes that have no remaining properties
- Removing relationships whose source or target nodes no longer exist in the graph
- Correcting relationship directionality when misaligned with schema-defined patterns
You can monitor pruning operations to better understand how the final graph takes shape. The Graph Pruner component logs its actions during the pipeline run, making it easy to trace why certain nodes or relationships were excluded. For example, in the case above, if a ThreatActor node was extracted, but ended up with no valid properties after schema enforcement, the following log entry might appear, indicating that the node was pruned:
{
'pruning_stats': {
'pruned_nodes': [
{
'label': 'ThreatActor',
'item': {
'id': '82e2fc31-59a8-42d6-a88c-faadfc63863d:6',
'label': 'ThreatActor',
'properties': {},
'embedding_properties': None
},
'pruned_reason': 'NO_PROPERTY_LEFT',
'metadata': {}
}
]
}
}These logs provide transparency into the pruning logic, helping you debug, refine your schema, or adjust enforcement levels with confidence.
For Advanced Users: Customize Your Schema Workflow
If you’re already familiar with the package and you prefer hands-on pipeline configuration, neo4j-graphrag lets you swap out the default pipeline for your own schema components, whether you’re providing a hand-crafted GraphSchema object via the SchemaBuilder or inferring one on the fly with SchemaFromTextExtractor. This approach gives you granular control over every aspect of knowledge graph construction.
Why you’d do this:
- Align with existing data models — For instance, import an external schema from a relational database or an existing Neo4j graph as the foundation for your knowledge graph.
- Fine-tune schema inference — For instance, override the default LLM and prompt template used for automatic schema extraction (you could instruct the model to “focus on ransomware families and MITRE ATT&CK® techniques”).
- Iterate and refine — Generate a schema from text, save it to a JSON file, tweak the schema, then reload it for subsequent extraction runs (ideal for rapidly evolving domains like cybersecurity).
from neo4j_graphrag.experimental.components.pdf_loader import PdfLoader
from neo4j_graphrag.experimental.components.schema import SchemaFromTextExtractor, GraphSchema
from neo4j_graphrag.experimental.pipeline.kg_builder import SimpleKGPipeline
# Extract schema and save to JSON file or YAML file
schema_extractor = SchemaFromTextExtractor(llm=llm, prompt_template=custom_template)
inferred_schema = await schema_extractor.run(text=PdfLoader.load_file("AA21–287A.pdf")
inferred_schema.save(JSON_FILE_PATH)
# load schema and use it in the pipeline
schema = GraphSchema.from_file(JSON_FILE_PATH)
kg_builder = SimpleKGPipeline(
# ...
schema=schema,
# ...
)Summary
The neo4j-graphrag 1.8.0 Python package brings schema-driven knowledge graph construction within everyone’s reach — whether you’re just starting with automatic schema inference or you’re an expert crafting custom schemas and enforcement rules. By combining powerful schema guidance and granular pruning, you’ll turn your unstructured data into more accurate and queryable graphs. Give it a try and see how schema-guided extraction can improve your RAG and QA workflows.
Unleashing the Power of Schema: What’s New in the neo4j-graphrag Python Package was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Essentials of GraphRAG
Pair a knowledge graph with RAG for accurate, explainable GenAI. Get the authoritative guide from Manning.
Share Article



Explore
Related Articles

Enhancing Hybrid Retrieval With Graph Traversal Using the GraphRAG Python Package
Hybrid Retrieval for GraphRAG Applications Using the GraphRAG Python Package
