


How to Convert Unstructured Text to Knowledge Graphs Using LLMs

Software Engineer, Neo4j
12 min read
Unstructured text is everywhere — emails, PDFs, internal documents, webpages — and it’s full of insights that are hard to access without structure. If you’re working on retrieval-augmented generation (RAG) and building large language model (LLM) applications, you’ve probably run into this challenge: how do you transform raw, messy text into something structured and usable?
That’s where knowledge graphs come in.
A knowledge graph provides a structured, connected view of your data, mapping out the relationships between entities. Unlike traditional databases or vector search tools that treat documents as standalone chunks, a knowledge graph shows you how ideas, people, or events in those chunks relate to each other across all your sources.
More in this guide:
From Raw Text to a Graph
So, how do you go from a pile of unstructured text to an organized knowledge graph?
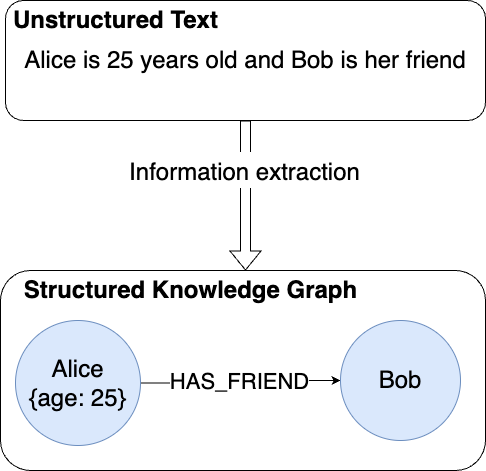
Until recently, this required time-consuming manual work. But now, with the help of LLMs and tools like the LLM Knowledge Graph Builder, most of the heavy lifting can be automated.
In this guide, we’ll walk through a simple but powerful 3-step process for turning text into a knowledge graph:
- Extracting nodes and edges from the text using LLMs
- Performing entity disambiguation to merge duplicate entities
- Importing the data into Neo4j to store and analyze the knowledge graph
You can explore a working example of this approach in the LLM Knowledge Graph Builder GitHub repo, which includes code, prompts, and sample data to get you started.
Now, let’s dive in.
What Are Knowledge Graphs and Why Do They Matter for Unstructured Data?
A knowledge graph is a way to organize information by showing how things are connected. Instead of storing data in rows and columns (like in a spreadsheet or in a relational database), a knowledge graph represents data as a network, where data entities like people, places, or concepts are connected to each other by relationships.
Think of it like a mind map for your data — a structure that mirrors how people naturally understand the world in terms of people, places, events, and how they relate.
What makes knowledge graphs especially useful is their flexibility. You can use them to organize:
- Structured data (like spreadsheets or databases)
- Semi-structured data (like JSON or XML)
- Unstructured data (like PDFs, documents, or websites)
That last category — unstructured text — is where knowledge graphs stand out.
Large language models can help extract meaning from raw text, but those insights are often short-lived or buried within big blocks of content. A knowledge graph captures those insights in a way that’s persistent, connected, and easy to query.
By converting unstructured data into chunks for a knowledge graph, you can:
- Reveal relationships across documents or sources
- Answer complex questions that require the LLM to synthesize multiple facts
- Build smarter applications, like personalized recommendations or enterprise search powered by reasoning
Why Not Just Use a Vector Database?
If you’re already familiar with RAG pipelines, you may be using a vector database to embed and search unstructured content. Vector databases excel at finding semantically similar chunks of text, meaning they can retrieve passages that “feel” relevant, even if the exact words don’t match.
However, vector search alone isn’t enough to get the information you need from unstructured data. You need to know how pieces of information relate to one another, but a vector search doesn’t provide this information. Vector search cannot show you how people, ideas, and organizations connect across documents. A knowledge graph provides organization so that you can see these relationships. A knowledge graph can:
- Represent structured and unstructured data together
- Model real-world relationships explicitly (not just implied by proximity)
- Support reasoning and inference across connected facts
In short…
GraphRAG (Graph Retrieval-Augmented Generation) builds on the RAG framework by introducing structured, graph-based retrieval. Instead of just retrieving “similar” chunks of text, GraphRAG uses a knowledge graph to surface relevant entities, relationships, and facts, giving the LLM better context and enabling multi-hop reasoning across connected knowledge.
If you’re working with unstructured data and want to go beyond keyword search or similarity scoring, knowledge graphs give you a smarter foundation. They help you organize messy information, surface hidden patterns, and power LLM applications that need context-aware, relationship-driven insights.
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

How to Convert Text to a Knowledge Graph Using LLMs
But how do you go from a pile of unstructured text documents to an organized knowledge graph? Previously, it would have required time-consuming manual work, but LLMs have made it possible to automate most of this process.
You don’t need to write custom extractors or manually define every relationship. The LLM can handle the heavy lifting, and you can step in later to refine the output.
Here’s how the process works:
1. Extracting Nodes and Relationships
The simplest way to start is to pass your input text to an LLM and let it decide which nodes and relationships to extract. You just need to ask the model to return each entity in a consistent format—with a name, a type, and any properties it finds. This method of guiding the LLM to return entities in a consistent format makes it possible to extract nodes and relationships from the input text.
LLMs can only handle a limited amount of text at once, usually between 4,000 to over 100,000 tokens. If your input is too long, the model won’t be able to process it all. To work around this, break the text into smaller chunks that fit within the model’s limit.
Determining the optimal splitting points for the text is a challenge in itself. To keep things simple, divide the text into chunks that are as large as possible without exceeding the model’s limit.
You might also introduce some overlap from the previous chunk to account for cases where a sentence or description spans multiple chunks. This approach allows you to extract nodes and relationships from each chunk, representing the information contained within it.
To maintain consistency in labeling different types of entities across chunks, provide the LLM with a list of node types extracted in the previous chunks. Those start forming the extracted “schema.” This approach enhances the uniformity of the final labels. For example, instead of the LLM generating separate types for “Company” and “Gaming Company,” it consolidates all types of companies under a “Company” label.
One notable hurdle in this approach is the problem of duplicate entities. Since each chunk is processed semi-independently, information about the same entity found in different chunks will create duplicates when we combine the results.
That brings us to the next step: entity disambiguation.
2. Entity Disambiguation
Typically, your dataset will contain duplicates once you’ve extracted a set of entities. This duplication occurs because each chunk of text is processed separately. The same entity may appear more than once with different names or partial properties.
You can use the LLM to resolve duplicate entities. First, organize the extracted entities into groups based on their type (for example, all Person entities together). Then, ask the model to identify and merge duplicates by combining their properties.
LLMs are especially useful here because you don’t always know what name or format was used for each entity. For example, your initial extraction could have created two nodes that refer to the same entity: (Alice {name: “Alice Henderson”}) and (Alice Henderson {age: 25}). Like this:
(Alice {name: “Alice Henderson”})(Alice Henderson {age: 25})
The LLM should recognize the duplication and merge the entities into a single node with both properties included (name and age).
By repeating this process across all entity types, you end up with a much cleaner, more consistent dataset, ready to be imported into Neo4j.
3. Importing the Data Into Neo4j
In the final step, you’ll import the LLM-generated results into a Neo4j database. To ingest the data, you’ll need to convert the output into a format Neo4j understands. Start by parsing the text from the LLM and transforming it into CSV files—one for each node and relationship type.
Next, map these CSV files to a format compatible with the Neo4j Data Importer tool. This tool lets you preview and adjust the data before importing it.
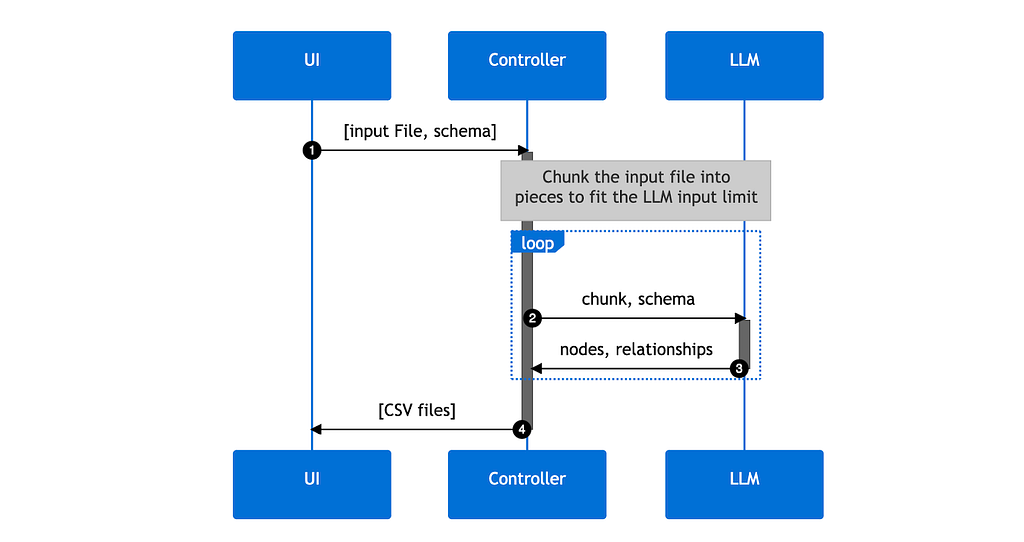
At this point, you’ll have built a three-part application:
- A UI for uploading a file
- A controller that manages the end-to-end process
- An LLM that the controller interacts with
The original source code is available on GitHub. For the most recent version, see llm-graph-builder.
You can also run a version of the pipeline that includes a schema. This schema works like a filter, helping the LLM include only specific types of nodes, relationships, and properties in the output.
If you’re interested in learning more about using LLMs with knowledge graphs, check out The Developer’s Guide to GraphRAG for hands-on examples, architectural patterns, and practical tips to get started.
Building a Knowledge Graph from Text: A Quick Demo
To show you how this works in practice, I tested the application by giving it the Wikipedia page for the James Bond franchise and then inspected the knowledge graph it generated.
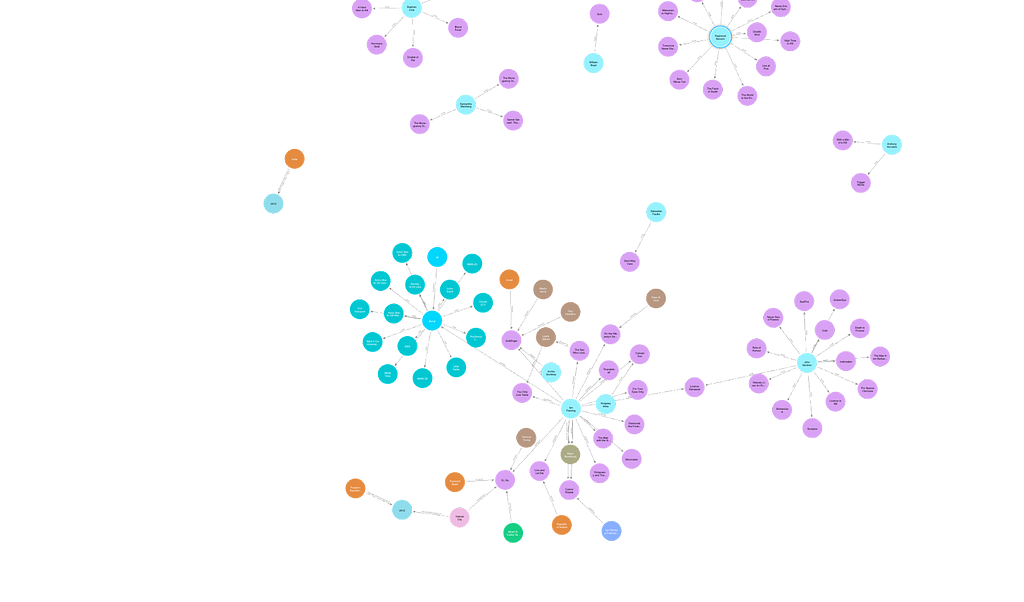
The knowledge graph contains many book nodes and the people connected to them, like authors and publishers. Overall, it gives a decent summary of the article’s content, and it’s impressive how much structure the model can extract from plain text.
But you may notice a few quirks:
- Role confusion: In several places, Ian Fleming, who wrote most of the James Bond novels, appears as a publisher instead of an author. This likely happened because the model misunderstood part of the article.
- Entity overlap: The graph connects book nodes to directors of movies with the same name, rather than creating separate nodes for the films. This kind of mix-up is common when names overlap across domains.
- Literal relationships: The model created the relationship “use” to connect James Bond to the cars he drives, probably because the article described it that way. A more natural label might be “drove,” but this example shows how literally LLMs interpret source text.
Watch the full demonstration here:
Challenges
As the demo above illustrates, this approach works surprisingly well for a first pass and shows that it’s absolutely feasible (and valuable) to use an LLM to build a knowledge graph from unstructured text. That said, there are a few limitations to keep in mind:
- Unpredictable output: LLMs don’t always follow instructions precisely. Even if you ask for a specific format (like a JSON list of nodes and relationships), the model might ignore that and do something else, like numbering the items or adding unexpected commentary. This makes parsing the output harder and less reliable. New tools like Guardrails and OpenAI’s Function Calling help address this problem, and the ecosystem of useful tools evolves by the day.
- Performance and speed: LLMs aren’t always as fast as you’d expect. Parsing a single long article (like a full Wikipedia page) can take several minutes. If you’re processing a large batch of documents, this adds up quickly. Speed improvements will likely come with time or by rethinking how the pipeline is structured.
- Lack of transparency: There’s no real way to know why the model extracted a certain fact or whether that fact actually exists in the source text. This makes it hard to trust the output without manual review. Compared to more rule-based or human-curated approaches, LLM-driven extraction introduces some fuzziness in data quality.
Getting Started With a Knowledge Graph
Now that you’ve seen how to build a knowledge graph from text using an LLM, you might be wondering: what’s the easiest way to try this yourself?
The good news is you don’t need to start from scratch. Whether you want to test a sample document or build your own pipeline, Neo4j offers beginner-friendly tools and guides to help you get up and running quickly.
Tools to Try
- LLM Knowledge Graph Builder
A ready-made pipeline for turning unstructured text into a structured graph. It includes prompt templates, chunking logic, and CSV exports formatted for Neo4j Data Importer. - GraphRAG Package
Want to use knowledge graphs in a generative AI workflow? This package shows how to combine LLMs with Neo4j for smarter retrieval, better grounding, and multi-hop reasoning. - Neo4j Data Importer
A no-code, drag-and-drop interface that helps you map and load CSV data into a live graph database—great for testing and quick iterations.
Related Resources
If you’re brand new to graph databases or want to level up your understanding, start here:
- How to Build a Knowledge Graph in 7 Steps
- GraphAcademy: Knowledge Graph Fundamentals
- LangChain Library Adds Full Support for Neo4j Vector Index
- Using a Knowledge Graph to Implement a RAG Application
Ready to see what your unstructured data knows? Start building your first knowledge graph with my dataset.
Essentials of GraphRAG
Pair a knowledge graph with RAG for accurate, explainable GenAI. Get the authoritative guide from Manning.
Share Article



Explore
Related Articles

How Graph Intelligence Drives Breakthroughs in Science and Society




