
Top 10 Use Cases: Identity and Access Management

Chief Scientist, Neo4j
4 min read

Graph technology is the future. Not only do graph databases effectively store relationships between data points, but they’re also flexible in adding new kinds of
relationships or adapting a data model to new business requirements.
But how do companies today use graph databases to solve tough problems? In this blog series, we’ll cover the top 10 use cases for graph technology and for each we include a real-world example. This blog series continues with a look at using graph technology for identity and access management.
In this eighth blog in our ten-part series, we examined how graph technology is a perfect fit for data lineage challenges. In this blog, we turn to how graph technology helps companies with identity and access management. Graph technology can handle the complexity of multiplex access and control structures, and features a use case from Telenor Norway fully utilized the technology for their needs.
Use Case #9: Identity and Access Management
Identity and access management (IAM) solutions store information about parties (e.g., administrators, business units, end-users) and resources (e.g., files, shares, network devices, products, agreements), along with the rules governing access to those resources. IAM solutions apply these rules to determine who can access or manipulate a resource.
Traditionally, identity and access management has been implemented either by using directory services or by building a custom solution inside an application’s backend.
Hierarchical directory structures, however, can’t cope with the complex dependency structures found in multi-party distributed supply chains. Custom solutions that use nongraph databases to store identity and access data become slow and unresponsive as their datasets grow in size.
Why Use Graph Technology for Identity and Access Management?
A graph database can store complex, densely connected access control structures spanning billions of parties and resources. Its richly and variably structured data model supports both hierarchical and non-hierarchical structures, while its extensible property model allows for
capturing rich metadata regarding every element in the system.
With a query engine that can traverse millions of relationships per second, graph database access lookups over large, complex structures execute in milliseconds – not minutes or hours. As with network and IT operations, a graph database access control solution allows for both
top-down and bottom-up queries:
- Which resources – company structures, products, services, agreements and end users
– can a particular administrator manage? (Top-down) - Given a particular resource, who can modify its access settings? (Bottom-up)
- Which resource can an end-user access?
Access control and authorization solutions powered by graph databases are particularly applicable in areas like content management, federated authorization services, social networking preferences and software as a service (SaaS) offerings, where they realize minutes-to-milliseconds increases in performance over their relational database predecessors.
Example: Telenor Norway
Telenor Norway is an international communications services company. For several years, it has offered its largest business customers the ability to self-service their accounts. Using a browser-based application, administrators within each of these customer organizations can add and remove services on behalf of their employees.
To ensure users and administrators see and change only those parts of the organization and the services they are entitled to manage, the application employs a complex identity and access management system which assigns privileges to millions of users across tens of millions of product and service instances.
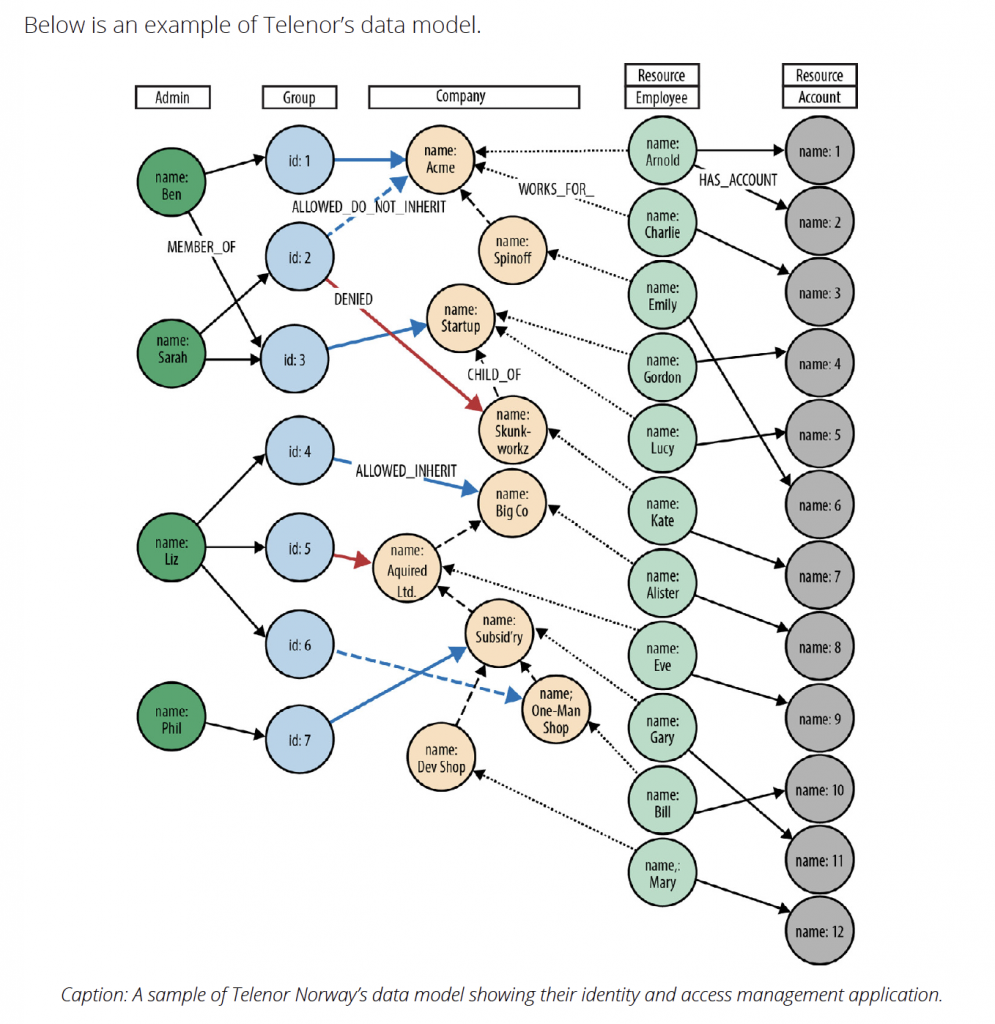
Due to performance and responsiveness issues, Telenor decided to replace its existing IAM system with a graph database solution. Their original system used a relational database, which employed recursive JOINs to model complex organizational structures and product
hierarchies. Because of the join-intensive model, their most important queries were unacceptably slow.
In contrast, once they implemented a graph database solution, Telenor realized the performance, scalability and adaptiveness necessary for handling their identity and access management needs, reducing queries that once took many minutes to milliseconds.
Conclusion
For your enterprise organization, managing multiple changing roles, groups, products and authorizations is an increasingly complex task. Relational databases simply aren’t up to the task of managing your identity and access needs as queries are far too slow and
unresponsive.
Using a graph database, you seamlessly track all of your identity and access relationships in real time. With an interconnected view of your data, you have better insights and controls than ever before.
The next and final blog in this series looks at using graph technology for bill of materials as a way for manufacturing companies to better manage their data.
Share Article



Explore
Related Articles

Mastering Fraud Detection With Temporal Graph Modeling

Top 10 Graph Database Use Cases (With Real-World Case Studies)


Elevate Fraud Detection With Neo4j on AWS: Uncover Hidden Patterns and Enhance Accuracy

