Fraud detection: Finding the needle in a haystack with knowledge graphs

Machine Learning Engineer, Deep Learning Café
11 min read

Editor’s note: This presentation was given by Tawanda Ewing at Connections: Graphs for Cloud Developers 2021.
As a Machine Learning Engineer for a startup called Deep Learning Café, I am in charge of getting most of our artificial intelligence and machine learning systems up and running in a cloud environment, often by using Google Cloud Platform. With my interests in technology, science, and Africa, I see opportunities for Neo4j and AI to solve complex problems that we face on the African continent. So, with that, I’ll share the fraud problem my company faced and how Neo4j was the solution.
The problem: Counterfeit goods and repeat offenders
“Thousands of counterfeit goods are imported into South Africa everyday.”
– South African Revenue Services
If you walk the streets of South Africa, particularly where I live in Johannesburg, it is actually difficult to not come across counterfeit goods. That is how much of a problem it is.
Our client, an intellectual property lawyer for an international law firm, had a database of documents that contained information on people or companies that are importing goods, and within those goods, there were counterfeit items. The client needed a way to quickly and reliably identify repeat offenders bringing in the exact same brands through various ports. It became very difficult to keep track of these repeat offenders over a period of two, three, and even more years. It is necessary to quickly identify a repeat offender from two years ago when new information comes in today.
The data available
The problem was that the client needed to identify key pieces of information from about a hundred plus documents coming in per day from within their practice or from port officials and police reports. These documents included the names of importers, the street addresses for these importers, their phone numbers, their email addresses, and most importantly, the brands that they were bringing into the country, because you are only considered a repeat offender if you bring in the exact same brand twice.
The vast amount of documents and unstructured data was too much for the lawyer to read through. You could build a working memory of who’s a repeat offender, but the moment that starts to span across thousands of documents over a period of years, it becomes too difficult to identify these repeat offenders. Plus there is an added layer of difficulty when you sometimes have different people importing on behalf of a company. You look for the common points, like data with the exact same phone number or a similar email or street address. It is just too much for a human to sort through all this information, though.
The proposed solution
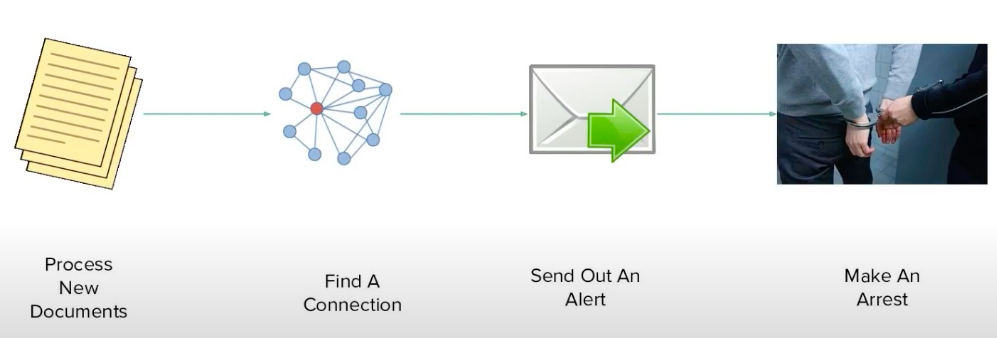
The client needed a way to instantly process both handwritten and electronic documents to identify leads on repeat offenders. If we found something of interest that could help identify a repeat offender, they wanted to receive an alert in the form of an email that would quickly help them further investigate the issue and potentially lead to a repeat offender’s arrest. This was the ideal solution we had in mind. If you look at the proposed solution image above, it looks simple, but we soon found once we actually got started it was a lot more complicated to get right. Neo4j ended up playing a huge role in simplifying and solving this problem for us.
Choosing the right database
Our team at the time was made up of three developers familiar with Google Cloud Platform and Python, so we needed to use the skills we had available to solve the problem. From our predetermined skillset, the difficult part was actually identifying the right database for this particular situation.
To give you a bit of background on what was going on at that time with the startup, I was the least experienced member of the team at that point. Two senior engineers with more industry experience suggested looking at a SQL database or a document database. Still, I had this feeling that either one of those solutions were going to be difficult to implement with this particular problem.
I started by looking into SQL databases, which I had worked with before. SQL is a great way to deal with relational data because it is a relational database after all, but where I found some complications was in deciding how to set up the schema for entities like addresses and important names. For instance, what would happen if they decided to expand those entities or realized that license plate numbers or ID numbers become important for identifying these repeat offenders? It would mean having to rework the schema of the tables and rewrite all of those queries to actually get that information through in the alerts. While it might have been quick to implement, it would be a problem to maintain. We needed a solution that could be maintained on the client’s end.
Next, I looked into document databases, which showed a bit more flexibility. Typically, we were looking at something like MongoDB, and I was actually quite fascinated by just how flexible this database was in terms of identifying the schema of different documents and easily joining data together later on down the line. While this was attractive in terms of flexibility, the big problem with that was that writing or creating the queries that would get the information for us became very complex. Inherently, document databases aren’t really good at maintaining relationships because it’s not what they’re built for. They are built to search across a single collection very quickly and then extract the information you need from the documents that you’ve identified as relevant to your query. The moment we had to try to create links between different collections and quickly identify these repeat offenders using all these different entities, the query completely blew up. We were going to have to write a lot of code to bring in that relational functionality, which would come back to bite us in the long run. We would have to maintain all this code, which would create opportunities for bugs to slip in. We might have coded ourselves into a corner, where we couldn’t actually solve the dynamic, changing nature of this problem as the law firm evolves or offenders catch on and figure out ways to trick the system.
Why Neo4j?
My background at the time with Neo4j was only from my academics, when my instructor strongly suggested we try out Neo4j as a database for a mock up app we were building. I suddenly found myself turning to SQL and Neo4j in a professional capacity for the first time. I was learning both of them from scratch and comparing which one was going to be the solution. What I found out was that Neo4j is very intuitive when it comes to dealing with highly related data. It’s the Cypher queries that make it so intuitive. Even though I was learning SQL queries and Cypher queries at the same time, I quickly found it much easier to learn Cypher and get the queries I needed out of Neo4j. At that point, I was impressed and realized Neo4j was going to be the solution.
Neo4j is a powerful tool that I can already see a wide range of uses for. It showed the promise of adaptability. Even though I defined the graph schema, which is somewhat rigid and affects the way the system is going to work further down the line, I didn’t feel boxed in. I found there was room to add different relations, entities, or nodes that would allow me to adapt my queries to evolve as their requirements, or as our client’s requirements, evolved.
Overall, one of the most important things to come from using Neo4j was our client’s satisfaction with how visually appealing the graph was. It was just so intuitive and attractive for our clients to actually visualize their data in a graph form, as opposed to just looking at tables and columns that are matched up. They liked the idea of looking at a graph and being able to easily identify repeat offenders and all the documents they have been mentioned in. At a glance, they could find potential crime syndicates linked across multiple documents and entity types. We were already convinced that Neo4j was the solution we wanted to use, and our clients were convinced as well.
Implementation
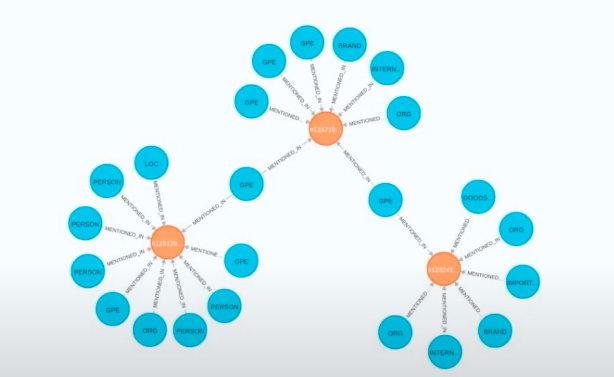
Lastly, I will share how we actually implemented Neo4j. Above, I have an image of the graph structure that we used to identify the syndicates. I know it’s not the clearest image, but what you can see here is that we actually only used one type of relation. We didn’t want to make too many assumptions about how they were going to evolve, or how the problem was going to change over time, so we went for the simplest form that could give us the best result. Thus, the idea was to use one type of relation. Essentially, the process was to go through any particular document and extract the entities identified within that document, and then build a relation on the graph database side by just saying that this brand was mentioned in this document or this person was mentioned in this document, and so on and so forth.
Eventually, we found that the graph allowed us to quickly and easily identify the moment we see an entity that is already in the database and find out where else this entity is mentioned, along with who else might be mentioned in that document. It could even be other email addresses mentioned in that document or any of the other entities of interest. With such a simple structure, the queries were also pretty simple to implement.
We were able to quickly get the solution out to the client, and they were very happy with it. Like us, they loved the fact that they weren’t boxed in if they came back to us with a different requirement. We were able to change the structure of the graph as we progressed and started to understand more about how these syndicates work and the kind of information we want to track.
Our client can actually continuously build on this knowledge graph we built. We used artificial intelligence to extract all the entities from the documents by basically using some natural language processing to find all the entities of relevance, and built this base knowledge graph. We then gave the client a tool on top of that, that would allow them to manually add some annotations. That’s the idea behind adding people who they know are repeat offenders. You add certain bits of information that are not necessarily extracted or appear in the document, but are relevant to helping our client clearly identify repeat offenders and how they actually work within a syndicate.
With that, we opened up the idea of being able to build even more complex and powerful queries on top of the existing knowledge graph, leveraging this manual data that they’re inputting, and then continuously expanding upon our client’s knowledge base. This allows us to run more complex queries and identify more efficiently and reliably who these repeat offenders are.
Conclusion
I hope our use of knowledge graphs has enlightened you and maybe sparked some ideas on how you could easily implement a graph database. One last thing I’d like to mention is that when I was looking at Neo4j’s solution, the biggest problem was, how do I actually get this operating in a cloud environment? Neo4j AuraDB helped tremendously with this, so I recommend exploring that solution. Again, I hope through our insight that I opened some ideas for you and showed how easy it can be to get started with graphs.
Sign up and get started with Neo4j AuraDB Free now!
Share Article



Explore
Related Articles
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report
Fraud rings hide in the connections: Graph-Enriched Detection for Databricks Genie with Neo4j
Introducing Document Intelligence: From documents to a knowledge graph, right inside Aura

Getting started with Neo4j Aura: A guide to the leading cloud graph database

Finding hidden bottlenecks in flight networks with Aura graph analytics on Databricks
