


Advanced RAG Techniques for High-Performance LLM Applications


17 min read
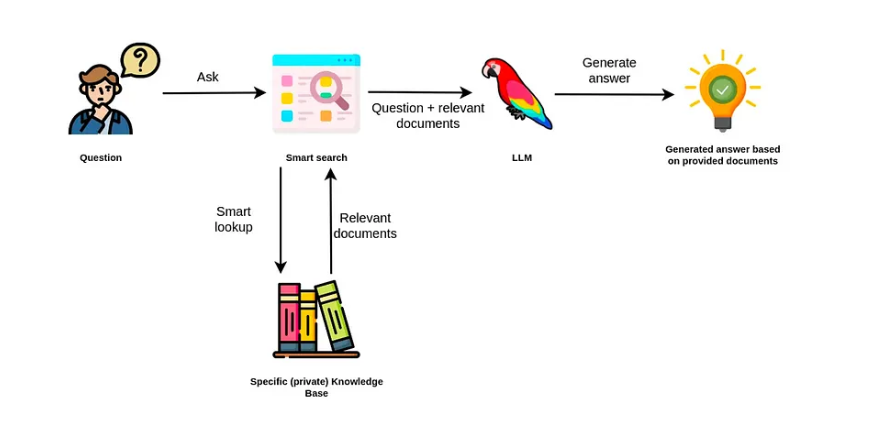
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by combining retrieval with generation to ground outputs in your own data rather than relying solely on pretraining. In practice, RAG systems retrieve relevant information from a knowledge source and integrate it into the prompt, enabling responses that are more accurate, contextual, and trustworthy.
RAG is now a widely used architecture for LLM applications, powering everything from question-answering services that leverage web search, to internal chat tools that index enterprise content, to complex QA pipelines. Its appeal is simple: by augmenting generation with retrieval, teams can deliver LLM experiences that meet today’s expectations for relevance and reliability.
But shipping a RAG system isn’t the finish line. Anyone who’s moved beyond a prototype knows the symptoms: hallucinations creep back in, long queries bog down performance, or answers miss the mark despite the right documents being retrieved. That’s where advanced RAG techniques come in. This guide walks through the strategies that help teams improve relevance, accuracy, and efficiency, so your system not only works, but works at scale.
More in this guide:
RAG Architecture
A typical RAG pipeline is simple to describe but also easy to underbuild for production. Understanding the RAG architecture baseline and why basic setups struggle helps you move into advanced RAG techniques with the right context.
What the RAG Pipeline Does
A standard RAG system does four things:
- Ingests content: splits documents into chunks, adds metadata, and creates embeddings.
- Indexes: builds a store for efficient retrieval, often a vector index, sometimes with a keyword index as well.
- Retrieves: fetches top-k context for a query.
- Generates: prompts the model with the query plus the retrieved context and returns an answer.
At runtime, the system encodes the user’s query with the same model used to embed documents during ingestion, searches the index for the nearest vectors, retrieves the top-k chunks, and includes those chunks with the query in the prompt.
A Typical Failure Mode
Naive pipelines often perform well in demos but break in production.
This might sound familiar: You ship a quick RAG helper for your team. It nails simple fact lookups. Then a PM asks, “Which enterprise customers renewed last quarter and also opened support tickets about SSO?” The bot replies with a partial list, misses a couple of key accounts, and adds an irrelevant customer.
Here are some common symptoms you’ll recognize:
- Top-k returns near duplicates or shallow snippets, so the prompt lacks diversity.
- Retrieval misses proper nouns, IDs, or acronyms (SKU-123, SSO, SOC 2) because they occur rarely.
- Answers cite the wrong entity or mix details across similar accounts.
- Latency climbs when you raise k, use longer chunks, or rerun retrieval after follow-ups.
- Poor table and PDF splitting drops headers or footnotes that change meaning.
- Multi-turn chats drop constraints (“only EMEA,” “last quarter”), so follow-ups forget earlier filters, leading to off-scope answers.
- Thin retrieval sets push the model to guess and fill in unsupported details.
Why Basic RAG Breaks (And How Advanced RAG Techniques Help)
Because RAG couples approximate retrieval with probabilistic generation and small context windows, a few recurring failure modes show up in production. These issues usually show up in logs and traces:
- Vector-only retrieval is semantic and can miss exact tokens and rare strings. Without hybrid search, names and codes slip through.
- Chunking boundaries cut across structure, so the model sees fragments without the right context.
- No reranking means cosine similarity rewards proximity, not usefulness.
- Missing filters (time, source, region) let off-scope documents into the prompt.
- Limited query understanding (no expansion or decomposition) under-retrieves for multi-hop questions.
- Limited context window forces you to drop good passages or rely on summaries that lose detail.
- No feedback loop to detect weak context before generation, for example, a simple CRAG-style check.
- No graph context to connect entities and events, so cross-document reasoning fails.
- Stale embeddings or indices after data changes, which means that retrieved data reflects yesterday’s state.
An advanced RAG architecture strengthens what the model sees and how it reasons. It finds better evidence, keeps only what matters, connects it across sources, and verifies the result with citations, so answers are accurate, explainable, and repeatable at scale.
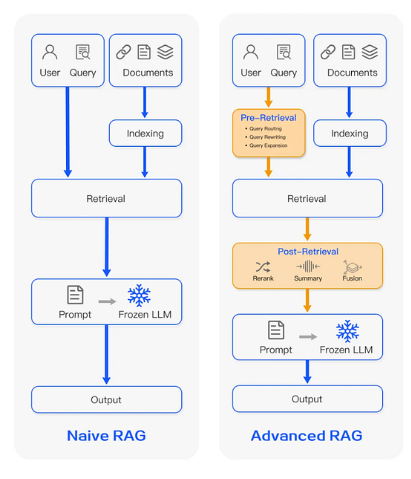
Advanced RAG Advantages and Techniques to Get You There
Advanced generally means better retrieval, better context management, and better answer creation. Below, we list the main advantages of an advanced RAG architecture with go-to techniques.
Improved Retrieval Quality and Relevance
Retrieval decides what the model even looks at. Most production RAG starts with dense retrieval (embeddings), which is strong for semantic matches but can miss rare terms, IDs, or acronyms. Advanced retrieval goes beyond this baseline with techniques that layer precision, coverage, and structure:
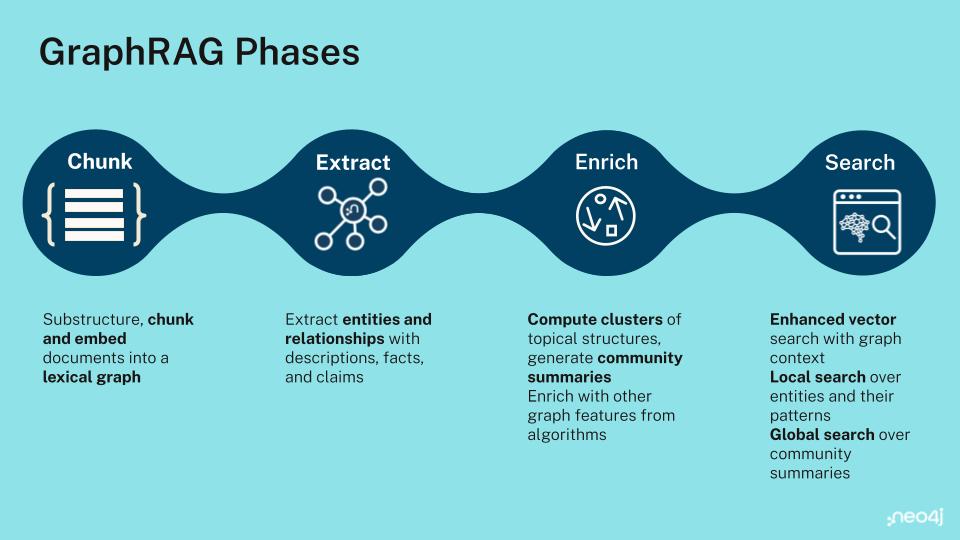
Knowledge Graph Retrieval (GraphRAG)
When your content contains rich entities and relationships (such as people, products, cases, citations), a knowledge graph lets you retrieve the context of your data, not just similar text. You can blend graph traversals with vector search to assemble precise, connected context for the prompt.
Why graphs matter: Vector/semantic search is strong for local lookups but struggles with global, cross-document questions and multi-hop relationships. Start by modeling your sources as entities and relationships, then retrieve in two ways: run local traversals to pull related entities and paths around initial hits, and use global community summaries for big-picture questions. This structured approach makes it much easier to retrieve and use specific information, expanding the types of questions you can answer with greater accuracy.
The Developer’s Guide to GraphRAG
Combine a knowledge graph with RAG to build a contextual, explainable GenAI app. Get started by learning the three main patterns.
Hybrid Retrieval (Semantic + Lexical)
Semantic retrieval encodes queries and documents into embeddings to match by meaning. Lexical retrieval (e.g., BM25 or SPLADE) matches exact terms. Semantic search excels at understanding meaning, but it can miss rare terms like IDs, codes, or proper nouns. Hybrid search covers both: pair a keyword-based retriever with dense embeddings, then combine their results using Reciprocal Rank Fusion (RRF) — a standard way of merging ranked lists — so the model sees passages that contain both the right meaning and the right tokens.
Filtering
Apply metadata rules (source, date, author, doc type) and semantic thresholds after you’ve extracted or enriched those fields from the raw docs. This removes low-quality or irrelevant hits before or alongside reranking, which reduces prompt bloat and improves grounding.
Reranking
After the first pass, rerank with a cross‑encoder or a rerank service so the top‑k you send to the LLM is truly the best. Reranking commonly improves top-k ordering when used after first-pass retrieval.
Make Documents Easier to Retrieve and Use
Raw documents rarely fit cleanly into a prompt. How you split them, keep structure, add metadata, and condense context determines what gets retrieved and how useful it is in a tight token budget.
Here’s how you can keep signal, drop noise, and send the model the parts that matter:
Chunking
Chunk sizes and boundaries strongly influence retrieval quality. Default to fixed-size or sentence-aware splits, layer in semantic chunking when boundaries are messy, and reach for document-aware/adaptive chunkers when structure matters (table, headers, code). When you’re ready to wire it up, the LangChain text-splitter docs have drop-in examples.
Parent Retriever
Keep document structure intact by retrieving smaller “child” chunks but swapping in the “parent” block when many children from the same section appear, preserving context and reducing fragmented prompts.
Text Summarization / Context Distillation
Summarize the hits so more relevant info fits in the window and the model focuses on the right facts. Most stacks support this: GraphRAG uses query-focused summarization, LangChain has a ContextualCompressionRetriever, and LlamaIndex offers tree/refine synthesizers.
Memory Augmentation for Conversations
For multi-turn chat, track conversation history and use retrieval-based memory so the system selectively recalls past turns instead of injecting full transcripts. Combine this with dynamic context windowing so follow-ups inherit the right context without bloating the prompt.
Improve Query Understanding
Sometimes the way a question is written doesn’t match how your docs are written. Add a small query-understanding layer so you can rewrite or expand the question and give retrieval a better shot at finding the right passages without overfetching. Keep this step simple and inspectable.
Hypothetical Questions as a Retrieval Variant
Generate representative questions (or, in HyDE-style approaches, a hypothetical answer) from each chunk and index those. At query time, match the user question to those pre-generated items to improve semantic alignment.
Query Expansion
Add synonyms and related terms, or generate a few query variants, to bridge wording gaps between the question and your docs. This often boosts recall without sacrificing precision (when paired with filtering/reranking).
Handle Complex, Multi‑Step Questions with Agentic Planning
Multi-step questions often require agentic planning. Sometimes referred to as an agent loop, this approach involves an agent breaking a problem into sub-questions, choosing the right tool for each (graph queries, hybrid retrieval, calculators), and orchestrating the loop: plan → route → act → verify → stop. This ensures coverage, provenance, and less guessing. Here’s how advanced agentic planning plays out in practice:
Multi-Step Reasoning or Multi-Hop QA
Some questions require stitching facts across people, events, and time. A single top-k pull often misses links. Break a complex question into smaller sub-questions and let an agent route each to the best retriever (graph/Cypher for relationships/joins; hybrid/semantic+lexical for facts and dates), then synthesize with per-claim citations. If any hop returns weak evidence, expand retrieval or ask a clarifying question before finalizing.
Agentic Planning Workflow
To increase the proportion of hops that have sufficient high-quality evidence that leads to a traceable source, use agentic planning to plan the steps, route each to the right tool, verify the evidence, and stop when the answer is supported; this preserves provenance and reduce hallucinations. Use the points below as a short checklist for multi-step questions:
- Break the question into concrete tasks (entities to find, time windows, joins/paths).
- Choose the best tool per task (graph/Cypher for relationships and joins; hybrid retrieval for facts/dates; calculator/code when needed).
- Execute the query or retrieval and collect evidence with provenance.
- Check coverage (does each sub-goal have strong evidence?) and conflicts (do sources disagree?). If weak, try again, broaden your approach, or switch tools.
- Conclude when all sub-goals are satisfied or when you hit the budget (max hops/tool calls/tokens). Provide the answer with per-claim citations or state what evidence is missing.
Chain-of-Thought Prompting (CoT)
Some tasks benefit when the model plans or reasons in steps instead of jumping to an answer. Use CoT as the agent’s private scratchpad to outline hops and track intermediate findings, then return a concise, source-grounded answer with citations. CoT improves multi-step inference but requires strict grounding rules (e.g., “answer only from retrieved sources; say ‘I don’t know’ if unsupported”). For higher accuracy, you can sample multiple plans/chain candidates and pick the best-supported synthesis. Use CoT for reasoning-heavy queries, not for simple lookups or latency-sensitive tasks.
Ground Answers and Reduce Hallucinations
Even with good retrieval, models may still guess when supporting passages are thin or off‑topic. Use these fixes to keep answers tied to evidence in the data and add a simple safety check when retrieval isn’t strong enough:
Grounding
Instruct the model to answer only from retrieved sources. Add this to your prompt: “Answer only from the retrieved sources listed below. If the answer isn’t supported, say ‘I don’t know.’ Include source/citation IDs next to claims.”
Combine strict prompts with reference tags or citation IDs and block unsupported text. (This belongs in your prompt template and evaluation rubric.)
Corrective RAG (CRAG)
When strong retrieval pipelines return incomplete or irrelevant context, CRAG adds a lightweight feedback loop: before generating, the system checks whether the retrieved set is good enough. If it looks weak, the system triggers another retrieval pass or applies stricter filters and then proceeds. This self-check step helps reduce hallucinations and keeps answers tied to stronger evidence.
How to Build an Advanced RAG Pipeline
Build an advanced RAG system by first structuring data into a knowledge graph, then layering graph-aware retrieval and an agentic plan–route–act–verify–stop loop. Choose a framework path like LangChain/LangGraph or LlamaIndex and measure impact with retrieval, answer-quality, and ops metrics.
Structure Your Sources
Extract entities, relations, and key attributes from PDFs/web/text into a property graph (nodes, edges, properties). Keep provenance (source IDs, spans, timestamps) and optional embeddings per chunk or node so you can blend graph hops with lexical/semantic search. Define a lightweight schema early (entity/edge types, required properties). Store confidence scores on extracted fields and down-weight or ignore low-confidence metadata at query time.
Use Agentic Planning for Complex Questions
For multi-hop/global questions, run a simple loop:
- Plan sub-goals (which entities, which joins/paths, which time windows).
- Route each sub-goal to the best tool: graph traversal via a graph query language (e.g., Cypher in property graphs) for relationships and joins; hybrid retrieval (lexical + semantic) for facts, names, and dates; optional calculators/code for transformations.
- Act and verify: execute, check coverage/conflicts, use community/cluster summaries for global questions and path-bounded traversals (k-hop with type/time constraints) to keep context precise and auditable; broaden or switch tools if evidence is weak; apply termination criteria and budgets (max hops/tool calls/tokens) to prevent open-ended tool use; stop when all sub-goals are satisfied or the budget is reached.
Evaluate Your Advanced RAG Tactics
Don’t skimp on evaluation. You can create a solid evaluation baseline by measuring:
- Retrieved-context relevance. Is the context actually useful for the question?
- Groundedness/faithfulness. Does the answer stick to the retrieved sources?
- Answer relevance. Does it answer the user’s question?
- Ranking metrics for retrieval. For example, track MRR/Recall@k and latency for end-to-end UX.
When you introduce graphs, add simple explainers. For example, show which nodes/edges and passages supported an answer. This increases trust and makes debugging easier.
A Practical Plan Using Advanced RAG Techniques
Practice makes perfect. Use this sequence to add improvements safely and see what actually moves the needle. Make one change, measure it, and then move to the next.
- Stabilize basic retrieval: Start with good embeddings, sensible chunking, and clean metadata. Add a reranker so the top-k results are stronger, then measure to establish a baseline.
- Add hybrid search: Combine BM25 with vectors (via Reciprocal Rank Fusion or RRF) to catch both exact tokens and semantic matches. Track precision@k, Recall@k and groundedness to see the lift.
- Introduce query understanding: Use query expansion and HyDE (hypothetical questions/documents) to bridge phrasing gaps and improve recall without overfetching.
- Optimize context supply: Use parent-doc logic and summarization/context distillation to fit more relevant content into the window.
- Structure your data as entities and relationships: Extract and normalize key entities (people, orgs, products, IDs) and their relationships with provenance, then load them into a lightweight knowledge graph. Index nodes/edges alongside text so retrieval can pull paths and not just passages.
- Enable agentic multi-step Q&A: Use an agent to handle multi-hop questions: plan sub-goals, route each to the right tool, execute, verify coverage and resolve conflicts, stop within budget, and return answers with per-claim citations and auditable paths.
- Harden grounding: Lock answers to retrieved sources with strict prompts, CRAG-style retrieval checks, and citation tagging to cut hallucinations.
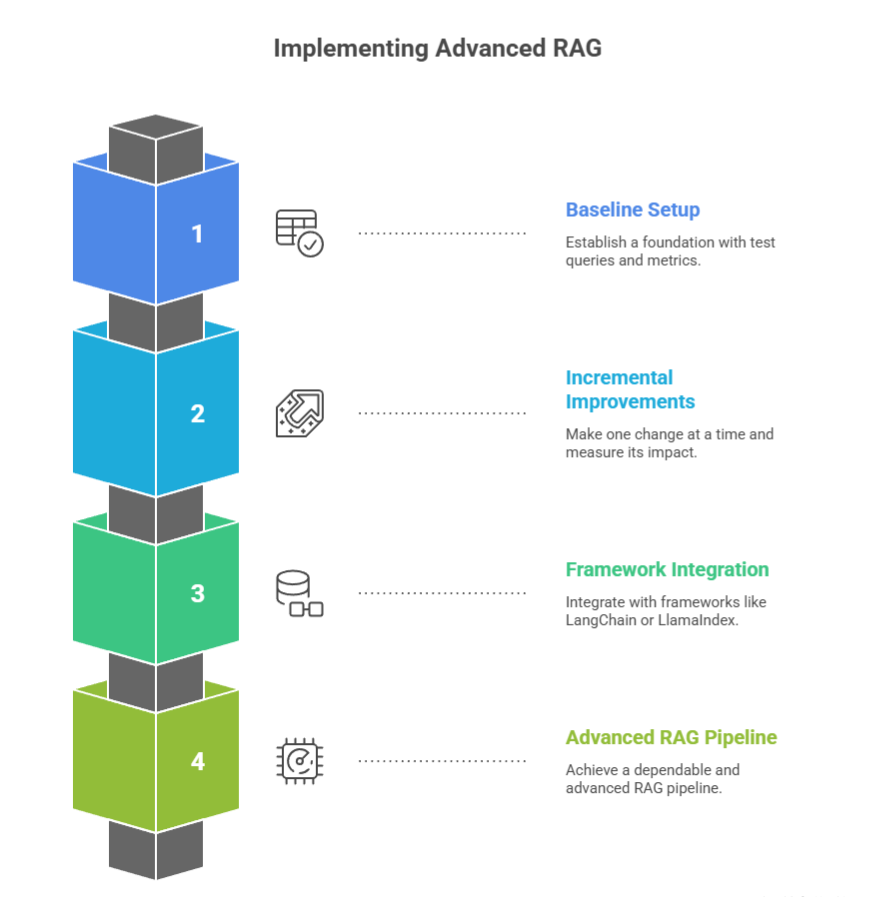
Start Practicing Advanced RAG
Want to move from a demo to something dependable? Kick off the process with a small baseline of test queries and a couple of metrics. Then make one change at a time and measure the impact.
- Pick one improvement at a time. Start with reranking or hybrid search. Both are low-risk and high-return. Measure changes on a fixed eval set.
- Track your pipeline. Log retrieved chunks, scores, graph paths, and citations for each answer.
- Integrate with your framework of choice. Frameworks like LangChain, LangGraph, or LlamaIndex can help orchestrate advanced RAG pipelines, but the graph-aware pieces come from Neo4j’s ecosystem.
- LangChain / LangGraph: Use them for orchestration (e.g., routing sub-questions to the right tool, managing agents, and handling plan → route → act → verify → stop loops). Pair them with Neo4j’s GenAI ecosystem components like LLM Graph Builder (to create knowledge graphs) and Model Context Protocol (to connect agents and LLMs to graph queries). Read this blog post to learn how to use the neo4j-advanced-rag template and host it using LangServe.
- LlamaIndex: Use Graph Index / Query Engine for path-bounded traversals and sub-question decomposition. Pair graph retrieval with document retrievers, apply post-processors (dedupe, compression), and rerank before generation. Parent-child retrieval or embedding hybrids are especially useful when structure or multi-hop reasoning matters.
- Adopt CRAG patterns. It’s essential for high-stakes domains such as legal, compliance, or support deflection with strict SLAs.
- Plan for scale. Use hybrid indices, approximate‑nearest‑neighbor vector search (ANN), and caching of common queries to cut latency without losing quality. Keep evaluations running as you optimize.
Where to Go From Here
Advanced RAG is about steady, incremental improvements across retrieval, context management, and generation (not a single trick).
To get your RAG ship-ready, start with reranking and hybrid search, add query understanding and context distillation, and bring in multi-step reasoning with a knowledge graph. Advanced RAG patterns benefit from graph-based retrieval through improved relevance and explainability. A Neo4j knowledge graph paired with an LLM delivers:
- Relevancy: Obtain more relevant answers compared to just vector searches
- Context: Includes domain-specific, factual, structured knowledge on your subject
- Explainability: Provide the user with more reasoning on how the results were obtained.
- Security: Role-based access control (RBAC) with fine-grained privileges on labels, relationships, and properties.
Learn how to build your first GraphRAG application today with the free guide:
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

Advanced RAG: FAQs
If your basic pipeline still hallucinates or misses exact identifiers, you need techniques that get more precise results, keep structure, and keep answers grounded.
Start with hybrid retrieval (vector + keyword), metadata filtering, reranking, and structure‑aware chunking/parent‑doc. Then, layer summarization, query expansion/HyDE, multi‑step reasoning, grounding/CRAG, and retrieval‑based memory as needed.
Complex questions fail when retrieval lacks coverage and the model guesses. These methods raise recall and precision while keeping grounding in place. Hybrid + expansion finds the right docs, reranking and parent‑doc/summarization surface the right passages, and CRAG catches weak evidence before you answer.
A knowledge graph unifies scattered documents, tables, and APIs into a connected picture of your data. With entities and relationships mapped out, GraphRAG retrieves along those connections, improving disambiguation, supporting multi-hop answers, and keeping sources traceable.
Share Article



Explore
Related Articles

Why Healthcare CIOs Can’t Afford to Scale AI Without a Knowledge Graph Foundation




