Getting started with the Neo4j BI Connector


9 min read

Over 10 years ago, Neo4j introduced the world’s first native graph database and defined an entirely new category of enterprise software. Since then, Neo4j has been hard at work helping our customers realize the value of the connections between their data. The world’s appetite for harnessing these connections has only increased with the advent of hyperscale computing, social networks, mobile and IOT devices.
With all of these new data sources comes… you guessed it, complexity.
As more and more companies adopt Neo4j into their enterprise environment and begin to realize value from looking at their data as a graph, we noticed a gap between Neo4j power users and traditional business analysts. These business analysts would love to harness the power of connected data, but lack the skills in Neo4j’s powerful Cypher query language or a graph-specific data visualization tool.
To increase the value Neo4j provides to our customers, we decided this functionality void needed to be filled. That’s why we designed a solution to address the complexity of new data sources with a simple, programmatic and supported way to interact with Neo4j and popular tooling: The Neo4j BI Connector.
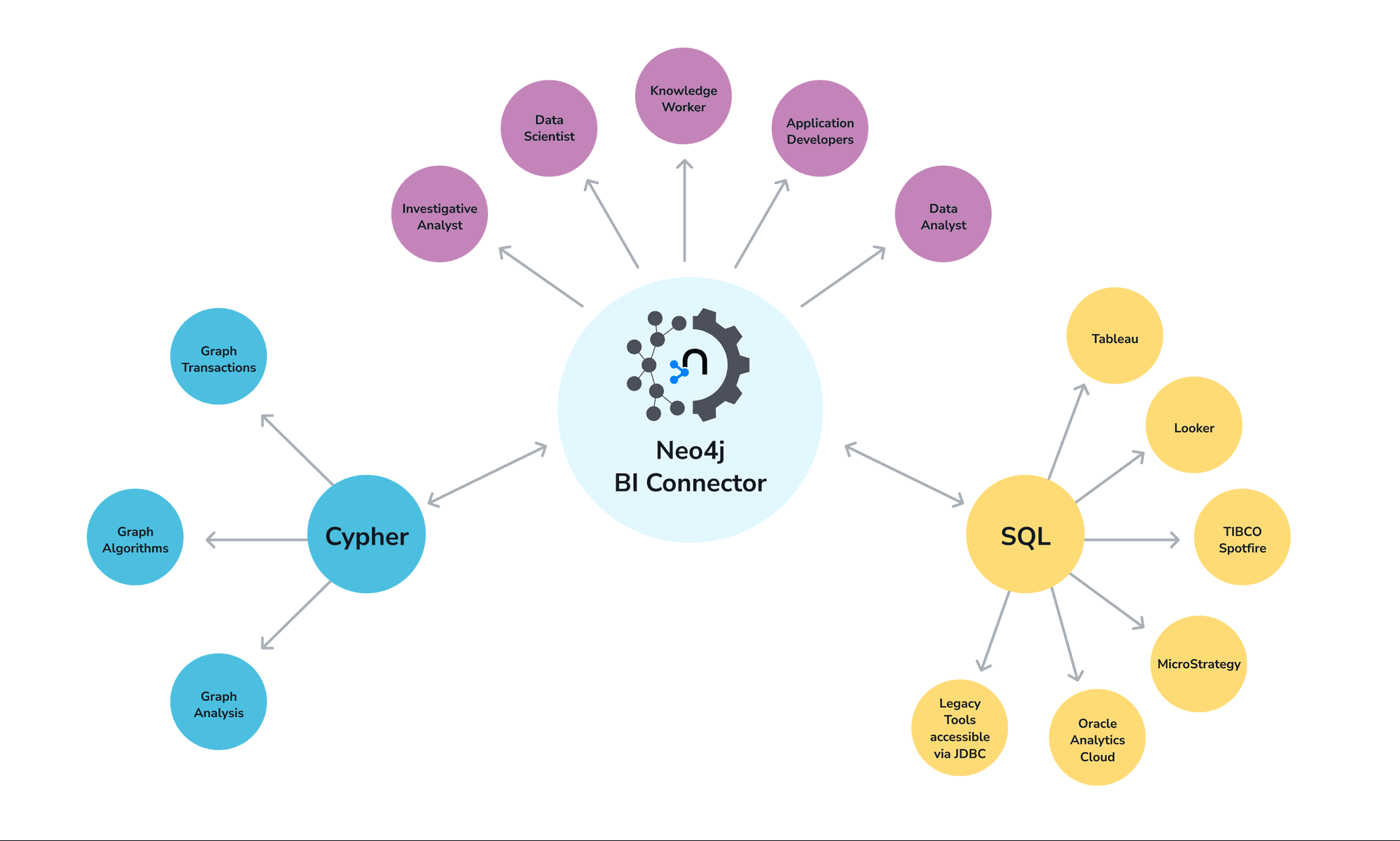
The Neo4j BI Connector allows users to retrieve read-only results from a Neo4j graph database for use in business intelligence (BI) applications, such as Tableau. This new capability makes it much faster and easier to take advantage of graph data in other business applications, and this article is all about how it works and how you can get started.
The BI Connector will help Neo4j customers by:
Reducing dependencies on power users and custom ETL jobs.
This decreases the complexity of maintaining the database connection and frees up internal resources to work on other projects.
Standardizing business intelligence workflows and architecture.
This provides access to real-time data and popular BI tooling in a low friction way.
Ensuring real-time data.
No longer will analysts be dealing with data that is out of sync with the database.
Increasing collaboration.
It’s easier for existing Neo4j customers to share their data with other groups within the enterprise, with less coordination overhead and no code.

How it works
The most popular BI tools today look at the world through a relational lense. This makes sense, as their primary data source for many years was traditional relational databases. With the proliferation of data and the advent of NoSQL databases, analysts have access to more data than ever before.
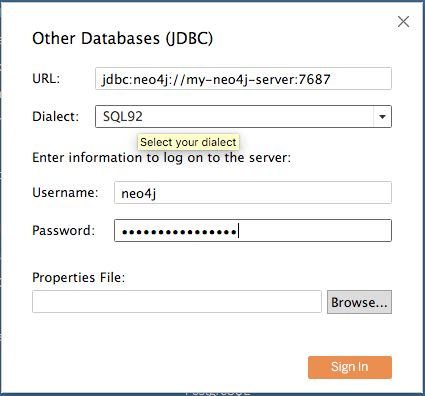
The BI Connector is a JDBC driver, which is a component that allows applications to talk to databases in a general way. Most business applications you run into these days can work with a data connection to another database if exposed by JDBC. Effectively, the BI application connects to a remote database and gets a list of relational tables that the database provides. Then the application issues any SQL queries that it might need to run, and uses that data as needed.
In the case of Tableau, using the BI Connector is simply a matter of copying the JDBC driver JAR file into the appropriate Tableau support folder, selecting “Other JDBC Connection” in Tableau, and then specifying a JDBC URL that looks like this:
Tables and graphs
In Neo4j, of course, there are no tables – only nodes and relationships in a graph. So what the BI driver is really doing is exposing a virtual relational schema that is built by the driver. The BI Connector looks at the graph schema in Neo4j; it exposes one table per unique node label combination, and one table per relationship pair found in the graph.
Let’s look at a simple example graph:

In this graph we have the labels Person and Hobby, and relationship types KNOWS and LIKES. Each label and relationship will get their own tables, forming “join tables” that, via SQL, can then be used to traverse relationships.
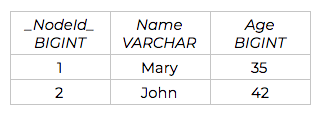
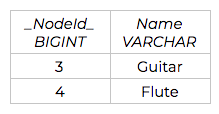
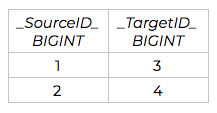
The resulting relational schema is displayed below, divided into four total tables. The rows of data, and their data types, are shown as they would be translated from Neo4j:
Person Table
Hobby Table
Person_KNOWS_Person Table

Person_LIKES_Hobby Table
SQL translation
On the fly, the BI Connector takes an inputted SQL query and translates it into a Cypher query. The Cypher query is executed against the database via a standard Bolt connection, just as any other query would be, and the results are sent back to the client. To the Neo4j database itself, the BI Connector looks like just another standard Cypher / Bolt client.
Here’s a very simple example of how that translation might work:
SQL:
SELECT name FROM Nodes.Person WHERE age > 20 ORDER BY age DESC;
Cypher:
MATCH (p:Person) WHERE p.age > 20 RETURN p.name ORDER BY p.age DESC;
This simple example shows how a SQL query might be translated, and how there is an equivalence between the relational tables and the Neo4j nodes in the graph.
Relationship tables are more complicated, but follow the same principle. Relationship tables consist at a minimum of a source and target ID, which match the _NodeId_ field in a label’s table. When tools generate SQL JOINs, they are effectively “traversing the graph” through a relationship.
Note that this is just a simple example; nodes and relationships often have complex properties which would appear as extra columns in their tables. In the example above, any relationship properties that might exist on the KNOWS or LIKES relationships would appear in their respective tables as extra columns.
Data types
There’s not always a perfect match between data types in Neo4j and SQL. As a result, you may see columns which are long integers in Neo4j appearing as BIGINT in relational tooling. In some cases, compound data types – such as Neo4j’s geospatial points – will be translated into a String/VARCHAR representation. As development on the BI Connector continues, more types will be broken out into SQL equivalents where possible, and options may be added to destructure these types.
Over-fetching
In some cases, where a tool might express a SQL construct that does not have an equivalent in Cypher, the BI Connector has an in-memory SQL Engine that can be used to satisfy any standard SQL query.
So while you’ll find that you can throw just about any SQL query at the BI Driver and it will work, in some cases the query may be answered by pulling back more information from Neo4j than is strictly necessary to process the results on the client side.
As the BI Driver evolves over time, one of the key priorities is to increase the number of “push-down” operations to get the best possible performance and fetch the minimum data. Subsequent releases will have more efficient push-down operations, thus improving performance.
If you ever want or need to see what the BI Connector is doing in great detail, you can enable query logging on your Neo4j server, and use a Neo4j monitoring tool to even track those queries while they are in flight.
Communicating with Neo4j
Inside of the BI Connector is a regular instance of the Neo4j official Java Driver / Bolt client for Neo4j. When users specify a JDBC URL to connect to Neo4j, they embed in this a Neo4j URL that is passed to the Driver and functions exactly as the standard supported Java Driver works. This means that the BI Connector will transparently support the different connection schemes that Neo4j supports.
It also means that identity separation, security, query throttling and other features, as they pertain to the BI Connector, can be handled as any other Bolt client would be.
Neo4j server-side software
The BI Driver is normally a JAR file and set of documentation that is run on the client side.
For example, if you are using it with Tableau, you might use the BI Connector in conjunction with Tableau Desktop on a business user’s laptop. The BI Connector does require that the Neo4j APOC library is installed on the server though. This standard library provides procedures for the metadata harvesting process to run efficiently on large databases.
As of this first release, APOC version 4.0.0.4 is required for the Neo4j 4.x series, and APOC 3.5.0.9 for the Neo4j 3.5 series. It’s important to ensure that these APOC versions are present. No special configuration of APOC in neo4j.conf is required unless you are whitelisting specific APOC functions, in which case you will need to add apoc.meta.* to the allowed list.
If you’re using an older version of APOC, you can grab the updates you need here! If you are using Neo4j Desktop, then make sure your Desktop is up to date, but it should grab the right version of APOC automatically when you create a new database.
Custom Cypher
A key thing some customers ask for is support for custom Cypher, that is, a “power user” feature where users could expose a particular Cypher query and its results as a custom table. This feature is not yet available as of the initial launch, but it’s in the works. This could potentially allow users to take advantage of special graph operations and algorithms that can be natively executed in Cypher, and provide those results back to the relational layer in tools such as Tableau.
For the time being, to expose these types of features we recommend that you run the query and materialize the results to a new set of nodes and edges. Upon restarting the BI Driver’s connection, the new metadata will be harvested and you can see your new results.
Conclusion
The Neo4j BI Connector provides for easy access to Neo4j datasets from popular BI tools like Tableau, but more broadly than that – to any tool that expects to connect to a relational database addressed with JDBC and SQL.
We are incredibly excited to share the BI Connector with our customers and partners. If you have any questions or feedback, please feel free to reach out at [email protected]
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


A workbench for teams to query, explore, and visualize graph data


Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.
